







在之前写过两篇比较系统的关于 OpenTelemetry 的文章:
从基本概念到如何部署 demo 实战了解 OpenTelemetry,从那个 demo 中也可以得知整个 OpenTelemetry 体系的复杂性,包含了太多的组件和概念。
为了能更清晰的了解每个关键组件的作用以及原理,我打算分为几期来讲解 OpenTelemetry 的三个核心组件:
Trace
Metrics
Logs
首先以 Trace 讲起。
Trace
开始之前还是先复习一下 Trace 的历史背景。
如今现代的分布式追踪的起源源自于 Google 在 2010 年发布的一篇论文:
Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
在这篇论文中提出了分布式追踪的几个核心概念:
Trace
Span
Span 的一些基础数据结构
可视化追踪以及展示
之后 Twitter 受到了 Dapper 的启发开源了现在我们熟知的 Zipkin,包含了存储和可视化 UI 展示我们的追踪链路。
Uber 也在 2015 年开源了 Jaeger 项目,它的功能和 Zipkin 类似,但目前我们用的较多的还是 Jaeger;现在已经成为 CNCF 的托管项目。
之后陆续出现过 OpenTracing 和 OpenCensus 项目,他们都企图统一分布式追踪这一领域。
直到 OpenTelemetry 的出现整合了以上两个项目,并且逐渐成为可观测领域的标准。
更多历史背景可以参考之前的文章:OpenTelemetry 实践指南:历史、架构与基本概念
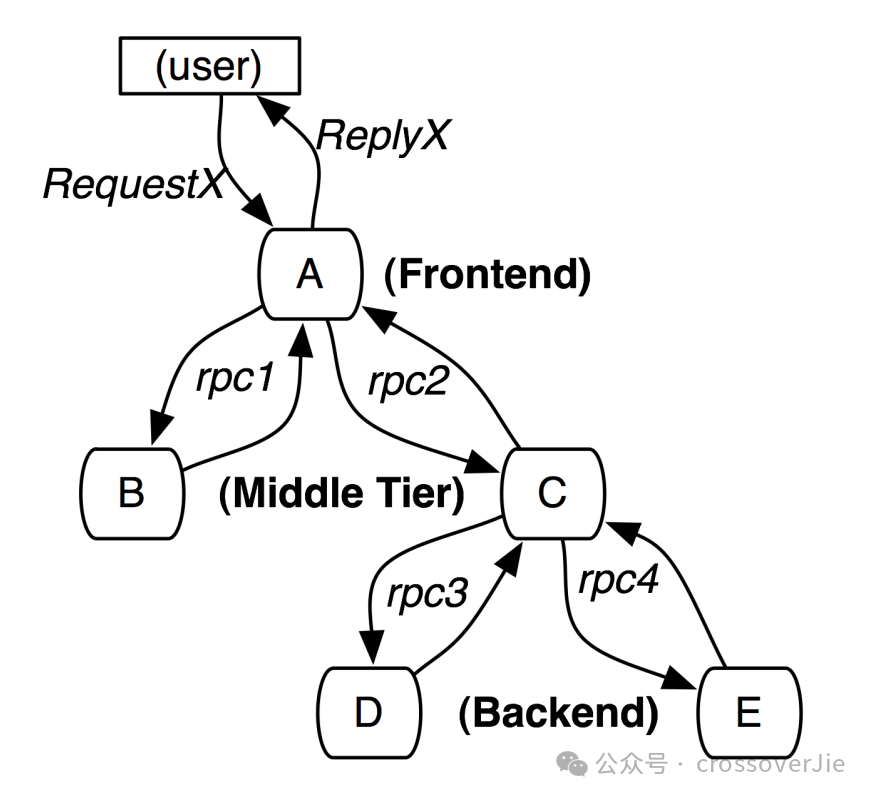
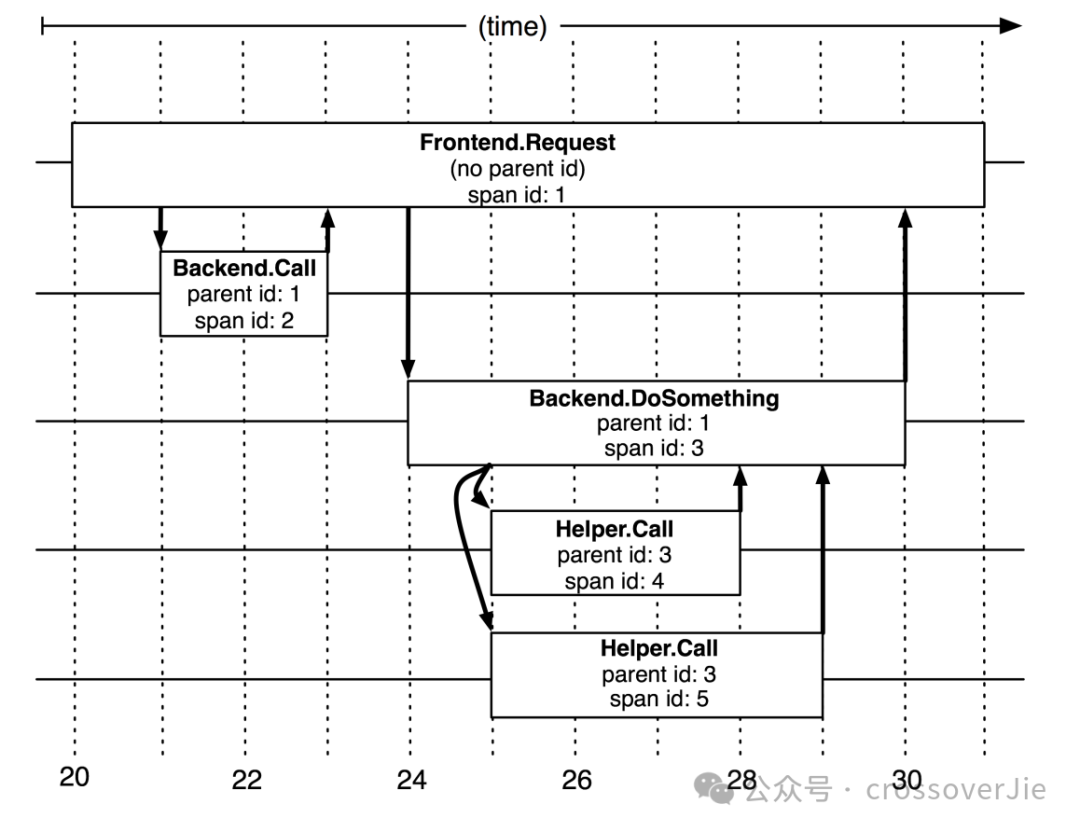
这里我们结合 Dapper 论文中的资料进行分析,在这个调用中用户发起了一次请求,内部系统经历了 4 次 RPC 调用。
从第二张图会看到一些关键信息:
spanName
parentId
spanId
parentId 很好理解,主要是定义调用的主次关系;要注意的是并行调用时 parentId 是同一个。
spanId 在可以理解为每一个独立的操作,在这里就是一次 RPC 调用;同理一次数据库操作、消息的收发都是一个 span。
span 的更多内容在后文继续讲解。
Span
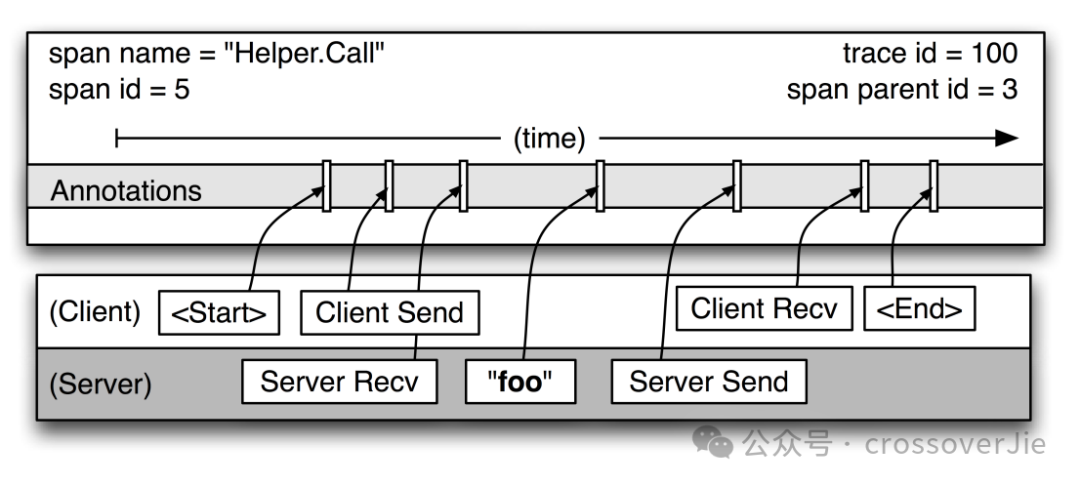 当我们把某一个具体的 span 放大会看到更加详细的信息,其中最关键的如下:
当我们把某一个具体的 span 放大会看到更加详细的信息,其中最关键的如下:
traceId
spanName
spanId
parentId
开始时间
结束时间
由于一个完整的 trace 链路由 N 个 span 组成,所以这个链路必须得有一个唯一的 traceId 将这些 span 串联起来。这样才可以在可视化的时候更好的展示链路信息。
以上的这些字段很容易理解,都是一些必须的信息。
在 Dapper 论文中使用 Annotations 来存放 span 的属性,也就是刚才那些字段,当然也可以自定义存放一些数据,比如图中的 "foo"。
OpenTelemetry 中的 Span
OpenTelemetry 的 trace 自然也是基于 Dapper 的,只是额外做了一些优化,比如在刚才那些字段的基础上新增了一些概念:
{
"name": "/v1/sys/health",
"context": {
"tr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









