









以唐诗生成模型为例,模型输入一个长度为 input_length=20 的序列,编码维度为 emb_dim = 128 ,token 最大词数为 max_word=10000 搭建如下模型。
1. LSTM
# 开始搭建网络
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM, Dropout
from keras.optimizers import Adam
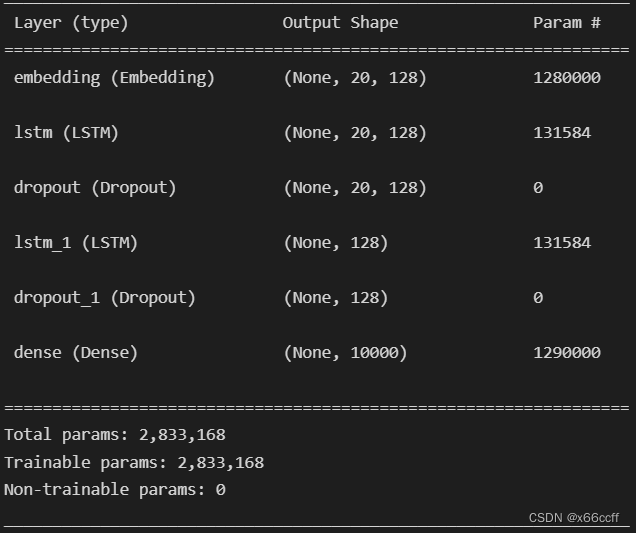
model = Sequential()
model.add(Embedding(10000, 128, input_length=20))
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(128))
model.add(Dropout(0.2))
model.add(Dense(10000, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
model.summary()
2. TextCNN
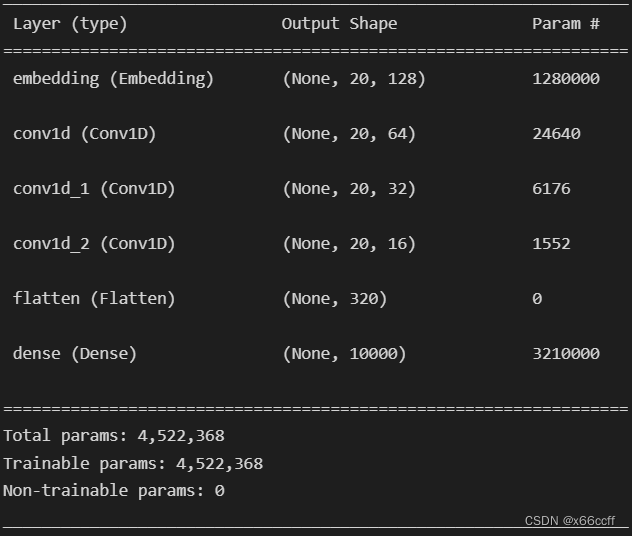
model = Sequential()
# 建立一个 TextCNN 模型
model.add(Embedding(10000, 128, input_length=20))
model.add(Conv1D(64, 3, padding='same', activation='relu'))
model.add(Conv1D(32, 3, padding='same', activation='relu'))
model.add(Conv1D(16, 3, padding='same', activation='relu'))
model.add(Flatten())
model.add(Dense(10000, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
model.summary()
3. Multi_head Layer 堆叠模型
# 开始搭建网络
from keras.models import Sequential , Model
from keras.layers import Dense, Embedding, LSTM, Dropout, MultiHeadAttention, Input, Flatten
from keras.optimizers import Adam
# 从 keras_nlp 导入位置编码层
from keras_nlp.layers import position_embedding
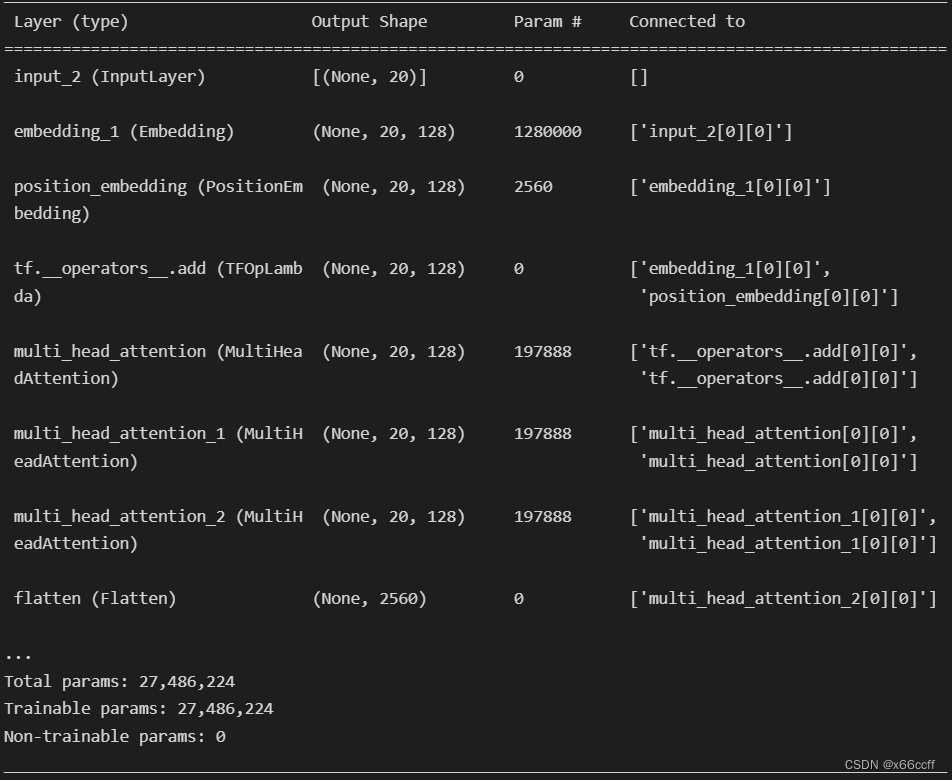
inputs = Input(shape=(20,))
x = Embedding(10000, 128, input_length=20)(inputs)
pos = position_embedding.PositionEmbedding(sequence_length=20)(x)
x = x + pos
x = MultiHeadAttention(num_heads=3, key_dim=128)(x,x)
# x = Dropout(0.1)(x)
x = MultiHeadAttention(num_heads=3, key_dim=128)(x,x)
# x = Dropout(0.1)(x)
x = MultiHeadAttention(num_heads=3, key_dim=128)(x,x)
x = Flatten()(x)
x = Dense(10000, activation='softmax')(x)
# 建立模型
model = Model(inputs=inputs, outputs=x)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
model.summary()
4. Transformer (Encoder)
# 开始搭建网络
from keras.models import Sequential , Model
from keras.layers import Dense, Embedding, LSTM, Dropout, MultiHeadAttention, Input, Flatten
from keras.optimizers import Adam
from keras import layers
# 从 keras_nlp 导入位置编码层
from keras_nlp.layers import position_embedding
import keras
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential(
[layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),]
)
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
def get_config(self): # 重写 get_config 方法,以便保存模型
config = super().get_config().copy()
config.update({
'att': self.att,
'ffn': self.ffn,
'layernorm1': self.layernorm1,
'layernorm2': self.layernorm2,
'dropout1': self.dropout1,
'dropout2': self.dropout2,
})
return config
inputs = Input(shape=(20,))
x = Embedding(10000, 128, input_length=20)(inputs)
pos = position_embedding.PositionEmbedding(sequence_length=20)(x)
x = x + pos
x = TransformerBlock(embed_dim=128, num_heads=8, ff_dim=256)(x) # (None, 20, 128)
x = layers.GlobalAveragePooling1D()(x) # (None, 128)
x = Dense(10000, activation='softmax')(x)
# 建立模型
model = Model(inputs=inputs, outputs=x)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
model.summary()
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









