







数据宏观把握--->数据预处理--->导出特征向量--->载入特征向量--->构建模型--->训练模型--->预测测试集
一、数据宏观把握
训练集25000张,猫狗各一半。测试集12500张,没标定是猫还是狗。
二、数据预处理
数据集的文件名是以type.num.jpg这样的方式命名的,比如cat.0.jpg,但是使用 Keras 的 ImageDataGenerator 需要将不同种类的图片分在不同的文件夹中,因此我们需要对数据集进行预处理。这里我们采取的思路是创建符号链接(symbol link),这样的好处是不用复制一遍图片,占用不必要的空间。
ImageDataGenerator是keras的Preprocessing模块 用于小型数据集上进行data augmentation,在深度学习中,当数据量不够大时候,常常采用下面4中方法:
1,Data Augmentation. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.
2,Regularization. 数据量比较小会导致模型过拟合, 使得训练误差很小而测试误差特别大. 通过在Loss Function 后面加上正则项可以抑制过拟合的产生. 缺点是引入了一个需要手动调整的hyper-parameter.
3,Dropout. 这也是一种正则化手段. 不过跟以上不同的是它通过随机将部分神经元的输出置零来实现.
4,Unsupervised Pre-training. 用Auto-Encoder或者RBM的卷积形式一层一层地做无监督预训练, 最后加上分类层做有监督的Fine-Tuning.
import os import shutil train_filenames = os.listdir('train') train_cat = filter(lambda x:x[:3] == 'cat', train_filenames) train_dog = filter(lambda x:x[:3] == 'dog', train_filenames) def rmrf_mkdir(dirname): if os.path.exists(dirname): shutil.rmtree(dirname) os.mkdir(dirname) rmrf_mkdir('train2') os.mkdir('train2/cat') os.mkdir('train2/dog') rmrf_mkdir('test2') os.symlink('../test/', 'test2/test') for filename in train_cat: os.symlink('../../train/'+filename, 'train2/cat/'+filename) for filename in train_dog: os.symlink('../../train/'+filename, 'train2/dog/'+filename)三、 导出特征向量
对于这个题目来说,使用预训练的网络是最好不过的了(通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到我们正在面对的问题上),经过前期的测试,我们测试了 ResNet50 等不同的网络,但是排名都不高,现在看来只有一两百名的样子,所以我们需要提高我们的模型表现。那么一种有效的方法是综合各个不同的模型,从而得到不错的效果,兼听则明。如果是直接在一个巨大的网络后面加我们的全连接,那么训练10代就需要跑十次巨大的网络,而且我们的卷积层都是不可训练的,那么这个计算就是浪费的。所以我们可以将多个不同的网络输出的特征向量先保存下来,以便后续的训练,这样做的好处是我们一旦保存了特征向量,即使是在普通笔记本上也能轻松训练。
既然预训练模型已经训练得很好,我们就不会在短时间内去修改过多的权重,在迁移学习中用到它的时候,往往只是进行微调(fine tune)。在修改模型的过程中,我们通过会采用比一般训练模型更低的学习速率。
微调模型的方法:
1.特征提取:我们可以将预训练模型当做特征提取装置来使用。具体的做法是,将输出层去掉,然后将剩下的整个网络当做一个固定的特征提取机,从而应用到新的数据集中。
2.采用预训练模型的结构:我们还可以采用预训练模型的结构,但先将所有的权重随机化,然后依据自己的数据集进行训练。
3.训练特定层,冻结其他层:另一种使用预训练模型的方法是对它进行部分的训练。具体的做法是,将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,我们可以多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配。
如何使用与训练模型,是由数据集大小和新旧数据集(预训练的数据集和我们要解决的数据集)之间数据的相似度来决定的。
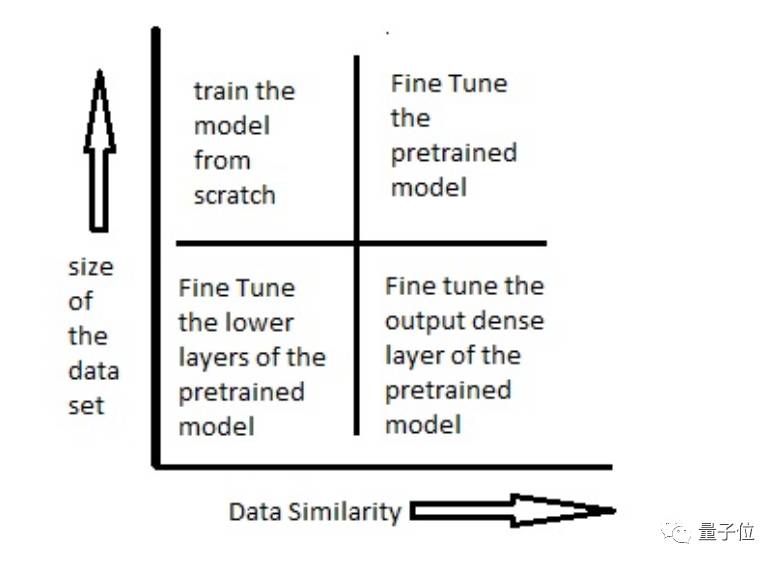
场景一:数据集小,数据相似度高(与pre-trained model的训练数据相比而言)
在这种情况下,因为数据与预训练模型的训练数据相似度很高,因此我们不需要重新训练模型。我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3093
3093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









