







 本文详细介绍了使用PyTorch进行Kaggle Dogs vs. Cats图像分类任务的实践过程,包括数据加载、预处理、模型构建、损失函数和优化器设定,以及模型训练中的内存管理问题和解决方案。
本文详细介绍了使用PyTorch进行Kaggle Dogs vs. Cats图像分类任务的实践过程,包括数据加载、预处理、模型构建、损失函数和优化器设定,以及模型训练中的内存管理问题和解决方案。
PyTorch实战Kaggle之Dogs vs. Cats
目录
1. 导包
import torch
from torch.autograd import Variable
import torchvision
from torchvision import datasets, transforms
import os
import matplotlib.pyplot as plt
import time
%matplotlib inline
- torch:定义了许多与神经网络相关的类、函数;
- torch.autograd:完成神经网络后向传播中的链式求导;
- Variable:torch.autograd包中的一个类,将Tensor数据类型变量封装成Variable对象,使得程序能够应用自动梯度的功能;
- torchvision:实现数据的处理、导入和预览等;
- datasets:数据导入;
- transforms:数据处理;
- os:集成了一些对文件路径和目录进行操作的类;
- matplotlib:绘图;
- time:主要是一些和时间相关的类。
2. 数据载入及装载
- 数据
这个数据集的训练数据集中一共有25000张猫和狗的图片,其中猫、狗各12500张。在测试数据集中有12500张图片,其中猫、狗图片无序混杂,且无对应的标签。
官方网站:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data
百度云网盘
链接:https://pan.baidu.com/s/1ZfjfBCRjTU4Q1j5ST-k8wQ
提取码:913v - 数据分类存放
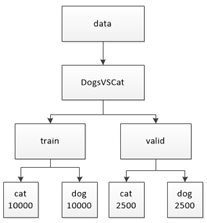
在获取全部数据集之后,我们需要对这些数据进行一个简单分类,将测试数据集中的数据分出一部分用作验证集,完成文件的分类之后再运行程序。文件层次结构及存放的数据量如下图所示:
- 载入:可理解为对图片的处理
- 装载:可理解为将图片打包好送给模型进行训练
data_dir = './data/DogsVSCats'
# 定义要对数据进行的处理
data_transform = {x: transforms.Compose([transforms.Resize([64, 64]),
transforms.ToTensor()])
for x in ["train", "valid"]}
# 数据载入
image_datasets = {x: datasets.ImageFolder(root=os.path.join(data_dir, x),
transform=data_transform[x])
for x in ["train", "valid"]}
# 数据装载
dataloader = {x: torch.utils.data.DataLoader(dataset=image_datasets[x],
batch_size=16,
shuffle=True)
for x in ["train", "valid"]}
注:在以上代码中数据的变换和导入都采用了字典的形式,这是因为我们需要分别对训练数据集和验证数据集的数据载入方法进行简单定义,使用字典可以简化代码,也方便之后进行相应的调用和操作。
3. 数据预览
1)获取一个批次的数据
- 代码
X_example, y_example = next(iter(dataloader["train"]))
print(u'X_example个数{}'.format(len(X_example)))
print(u'y_example个数{}'.format(len(y_example)))
print(X_example.shape)
print(y_example.shape)
- 输出结果

- 分析
其中,X_example是Tensor数据类型的变量,因为在上一步图片载入和装载时,对图片大小进行了缩放变换,所以现在图片的大小全部是64×64了。X_example的维度为(16, 3, 64, 64),维度的构成从前往后分别为(batch_size, channel, height, weight)。
y_example也是Tensor数据类型的变量,不过其中的元素值全为0和1,为什么会出现0和1?这是因为在进行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4225
4225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









