







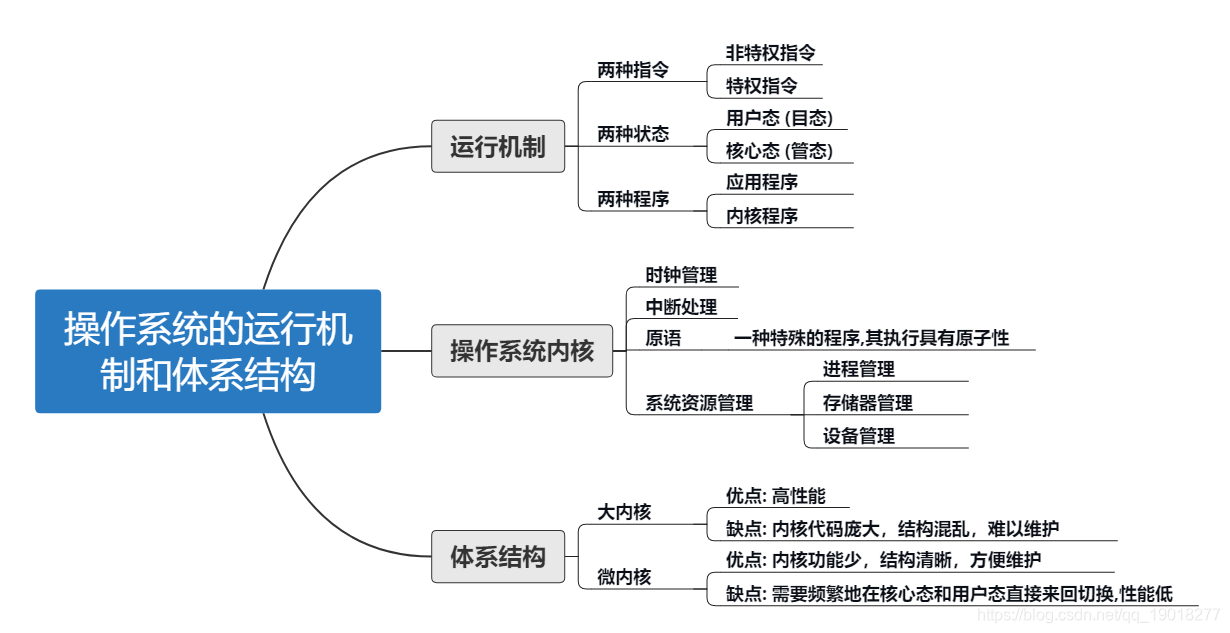
操作系统的运行机制和体系结构
代码和指令的区别
我们所说的代码一般指一段有意义的字符串,我们可以理解它的意思。比如,我们在C语言中写 x = x + 1;,我们可以清楚的理解这段代码的意思,但是计算机CPU却无法理解,因为它只能理解机器指令。我们来看看这段代码转换为机器指令后,变成了什么亚子。
001011000000011010011111
100100100000110000000001
001011000000011010011111
显然,我们看不懂这是什么意思,但是计算机CPU看得懂,它可以把这些3条指令转换为相应的电信号,去控制其他组件的运行。(这3条机器指令是我胡编的,实际上翻译成为的指令不是这样的)
简而言之,他们的区别在于:
- 代码:我们能理解,但是计算机CPU无法理解。但可以通过某些程序转换为指令。
- 指令:我们不能理解,但是计算机CPU能理解并执行指令之中相应的操作。
非特权指令和特权指令
在计算机之中,有的指令是"人畜无害"的,比如加法指令。
但是有的指令却十分危险,比如内存清零指令。如果某程序可以使用这个指令,这就意味着该程序可以将其他程序的内存数据随意清零,这样做显然很危险。
所以,我们必须对这些指令加以分类,将指令分为特权指令(如内存清零指令),和非特权指令(如普通的运算指令)。
- 非特权指令
“人畜无害”,安全的指令,程序可以随便用。 - 特权指令
危险的指令,只允许某些程序的调用。
问:CPU怎么判断当前是否可以执行特权指令呢?
这就引出了CPU的两种状态,用户态,还有核心态。
用户态和核心态
CPU的两种状态:
-
用户态
当CPU处于用户态时,CPU只能执行非特权指令, -
核心态
而当CPU处于核心态时,CPU能执行非特权指令和特权指令。
问:那CPU怎么知道自己位于哪个状态呢?
其实CPU中有一个寄存器 — 程序状态字寄存器(PSW),当该寄存器的值是0时,表示CPU处于用户态;而当为1时,表示CPU处于核心态。
应用程序和内核程序
在用户态和核心态的基础上,我们划分了两种程序,应用程序和内核程序。
- 应用程序
应用程序运行于用户态,只能执行非特权指令。 - 内核程序
内核程序是操作系统的管理者,运行于核心态,所以可以执行特权指令和非特权指令。
大内核和微内核
操作系统的内核分为两种,一种是大内核,一种是微内核。下面用图示展示二者的区别。
 可以看出,大内核比微内核多了一个层次 (处理机管理,存储管理,设备管理等),既大内核需要负责更多的工作。
可以看出,大内核比微内核多了一个层次 (处理机管理,存储管理,设备管理等),既大内核需要负责更多的工作。
下面举个例子说说二者有什么优缺点。
假如你和你的小伙伴开了一家公司,由于公司刚开,人员比较少,所以你们既当管理人员,又当处理人员。
现在有一个任务,公司要去商店采购一堆货物,所以你把采购清单列好之后,自己直接去商店采购,然后采购任务就完成了。
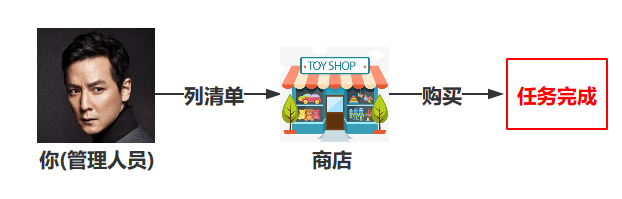
在这里,你并不需要向管理人员汇报采购什么(因为你就是管理人员…)。
所以当你即是管理人员,又是处理人员时,你的办事效率会很高,但是这样有一个不好的地方,那就是分工不明确。
等你们公司发展壮大之后,公司的人越来越多,而且此时,公司的分工明确了。
那么如果你们公司要采购货物, 过程是这样的:处理人员写好采购清单->发送给管理人员,等待审核->审核通过->处理人员向财务人员申请经费->经费到手,开始采购->采购完成。

显然,这个过程比较繁琐,但是分工很明确。
回到操作系统,
例子中的第一种情况就是大内核的情况,CPU不必在用户态(处理人员)和核心态(管理人员)之间来回切换,这样可以提高工作的效率,但是结构(分工)有些混乱。
而第二种情况就是微内核的情况,CPU必须来回切换用户态(处理人员)和核心态(管理人员,财务人员),工作效率降低了,但是结构(分工)很清晰。
总结
感谢
以上内容大部分来自王道操作系统系列视频教学。

















 2079
2079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









