




免责声明:本教程仅供学习和研究爬虫技术使用,严禁将所学知识用于违法、侵害他人隐私或利益的行为。任何使用本教程所提供信息造成的法律责任由读者自行承担,作者不承担任何法律责任。请在遵守相关法律法规的前提下,谨慎使用爬虫技术,遵守网站的使用规定。如有疑问或争议,请及时与网站管理员联系解决,作者不承担任何责任。感谢您阅读本教程,并希望能通过学习爬虫技术带来更多的收获和成就感。
背景
最近有朋友找到作者,在b站想找一些关于符合某种条件的博主联系,进而有一些合作,但是通过一个一个人工去寻找并筛查实在太麻烦,于是开始分析!
开始分析
打开F12点击查询
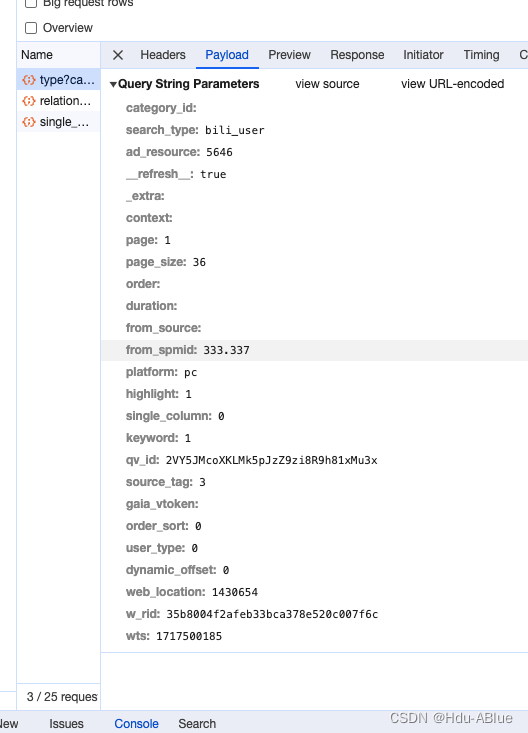
多次请求发现,w_rid和wts是一直在变化
全局开搜定位到 w_rid位置下断点
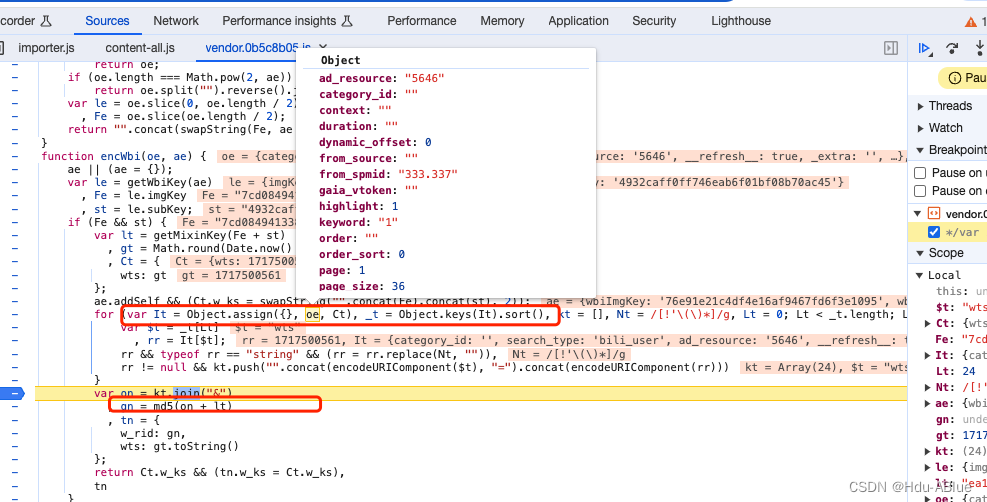
经分析wts就是当前系统的时间戳,w_rid如图就是请求所有url参数通过排序拼接后加上一个通过固定算法生成的32位字符,值为固定ea1db124af3c7062474693fa704f4ff8
代码还原算法
python模拟算法,结构与预期一致
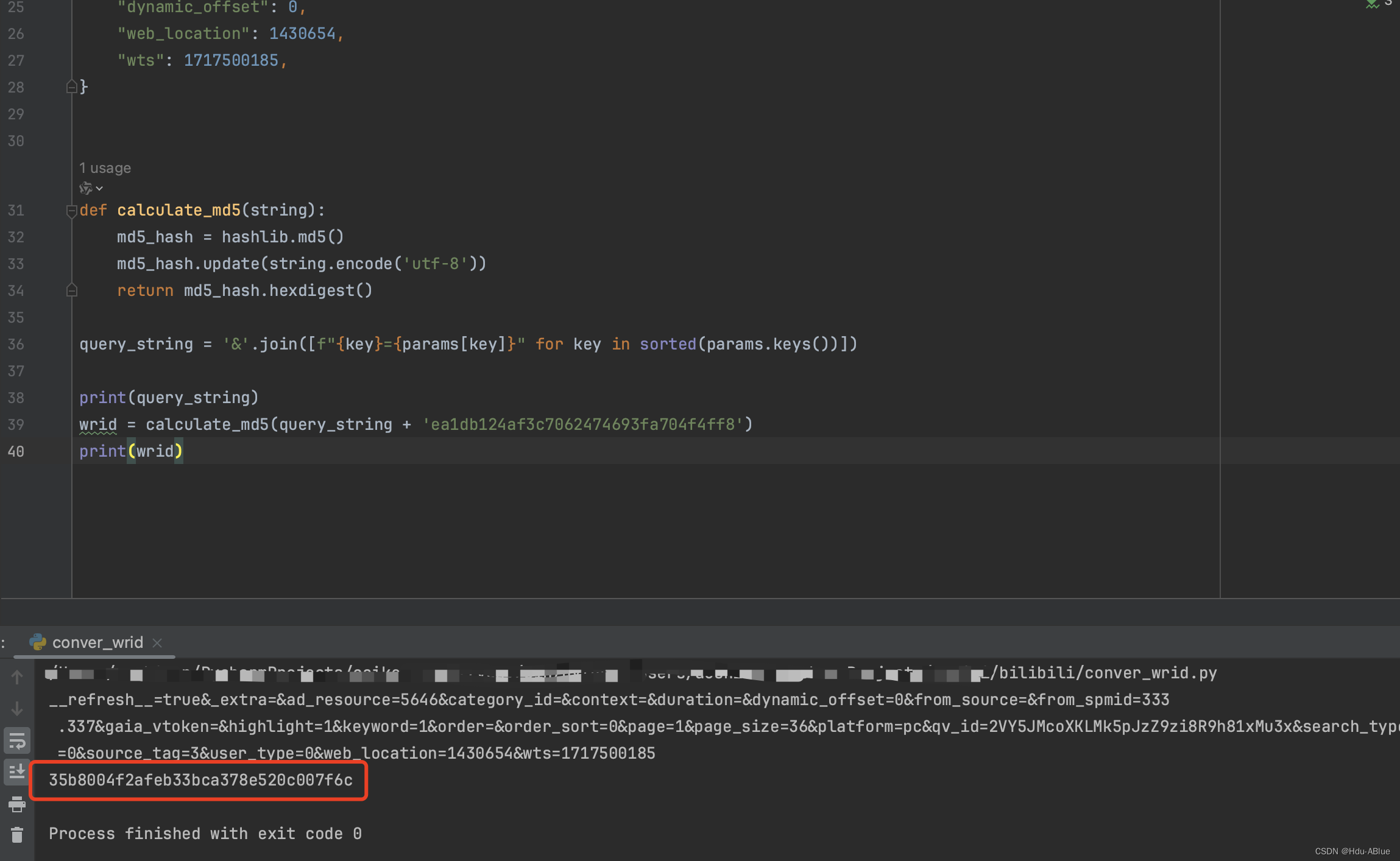
w_rid , python实现如下
import hashlib
params = {
"category_id": '',
"search_type": "bili_user",
"ad_resource": 5646,
"__refresh__": 'true',
"_extra": "",
"context": "",
"page": 1,
"page_size": 36,
"order": "",
"duration": "",
"from_source": "",
"from_spmid": "333.337",
"platform": "pc",
"highlight": 1,
"single_column": 0,
"keyword": "1",
"qv_id": "cookie获取qv_id",
"source_tag": 3,
"gaia_vtoken": "",
"order_sort": 0,
"user_type": 0,
"dynamic_offset": 0,
"web_location": 1430654,
"wts": 1717500185, #当前时间
}
def calculate_md5(string):
md5_hash = hashlib.md5()
md5_hash.update(string.encode('utf-8'))
return md5_hash.hexdigest()
query_string = '&'.join([f"{key}={params[key]}" for key in sorted(params.keys())])
print(query_string)
wrid = calculate_md5(query_string + 'ea1db124af3c7062474693fa704f4ff8')
print(wrid)
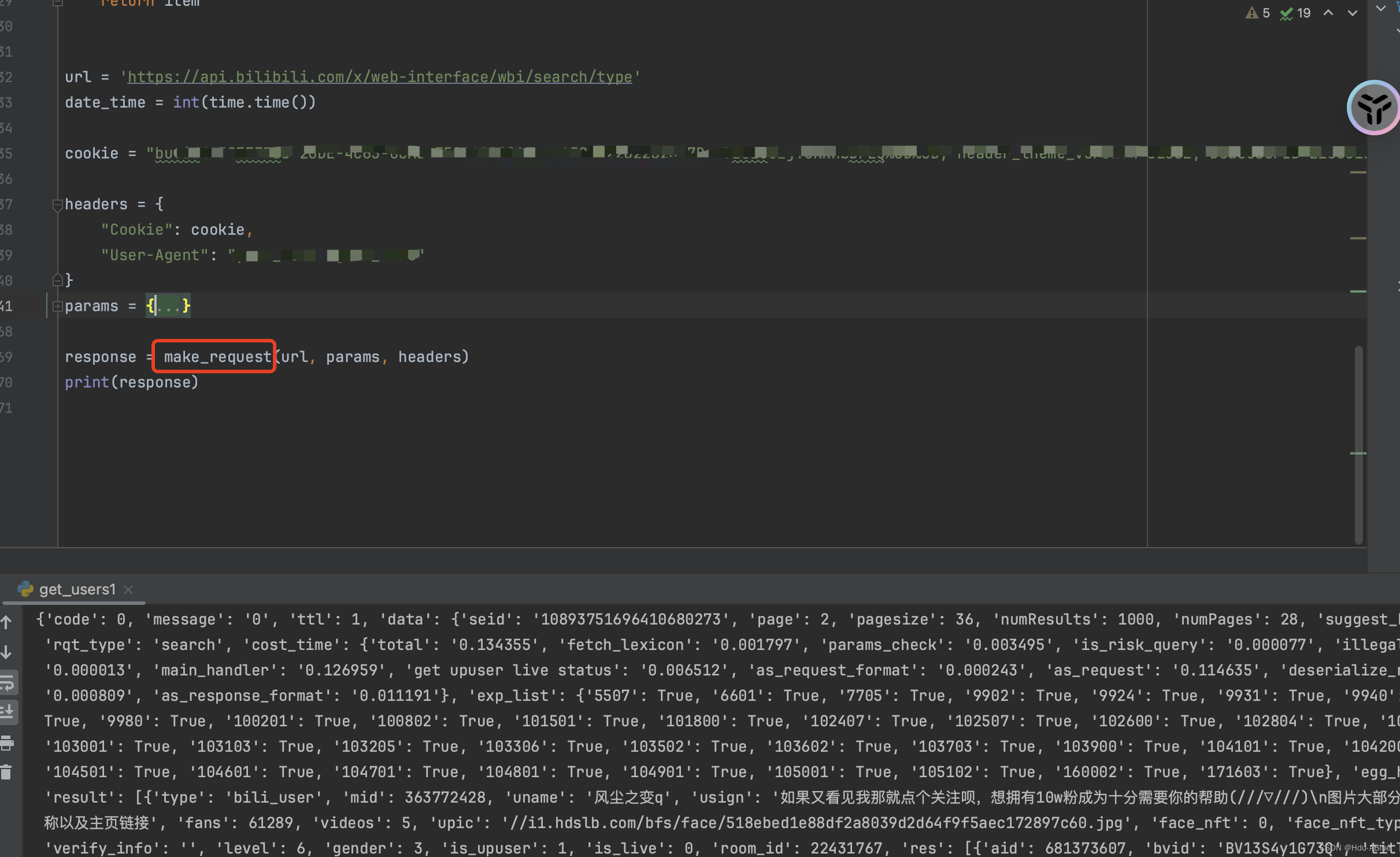
不想调试的小伙伴我封装了一个通用请求方法,自动填充参数,关注点赞评论学习找我获取哈
总结
关于逆向就到这里结束了,后续会发布 红薯、某乎等平台算法。也会分享一写应用场景,比如私信通知,信息导出excel等,创作不易,麻烦点赞关注支持一下。
ps: 引用请注明来源

















 2958
2958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









