






 该文章介绍了一个Python脚本,用于抓取B站(哔哩哔哩)用户主页的视频信息。脚本涉及到了请求参数的加密处理,包括w_rid和wts的计算,并提供了完整的代码示例。文章还解释了如何解析返回的数据,包括视频的播放数、点赞数、发布时间等信息。
该文章介绍了一个Python脚本,用于抓取B站(哔哩哔哩)用户主页的视频信息。脚本涉及到了请求参数的加密处理,包括w_rid和wts的计算,并提供了完整的代码示例。文章还解释了如何解析返回的数据,包括视频的播放数、点赞数、发布时间等信息。
概要
23 11新增:dm_cover_img_str,dm_img_list 代码已更新可借鉴一下,仅供学习交流
关于B站用户主页获取视频,w_rid wts加密
目标地址
获取内容
内容图片
接口地址
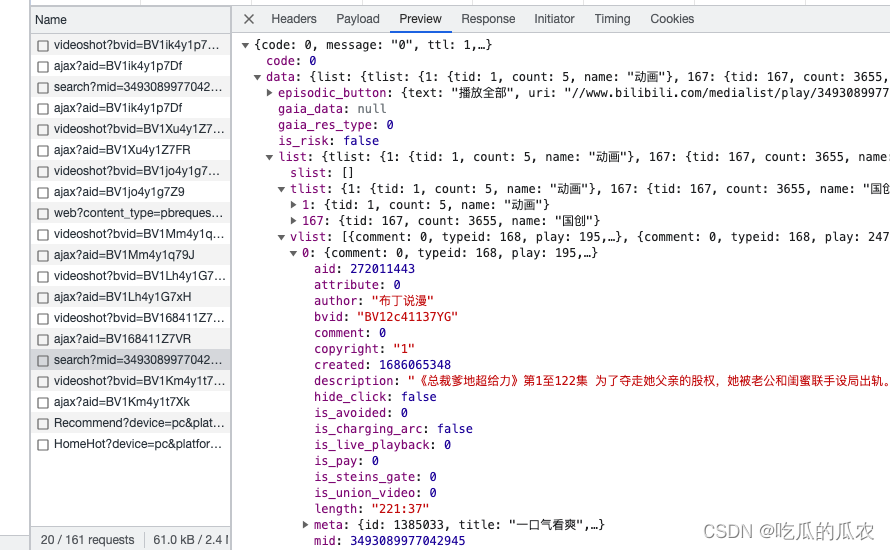
整体流程
curl
curl 'https://api.bilibili.com/x/space/wbi/arc/search?mid=3493089977042945&ps=30&tid=0&pn=2&keyword=&order=pubdate&platform=web&web_location=1550101&order_avoided=true&w_rid=fcb29335e712fd1a98705e31e98f929c&wts=1686275590' \
-H 'authority: api.bilibili.com' \
-H 'accept: application/json, text/plain, */*' \
-H 'accept-language: zh-CN,zh;q=0.9' \
-H 'cache-control: no-cache' \
-H $'cookie: 这里手动打码' \
-H 'origin: https://space.bilibili.com' \
-H 'pragma: no-cache' \
-H 'referer: https://space.bilibili.com/3493089977042945/video?tid=0&pn=2&keyword=&order=pubdate' \
-H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-site' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \
--compressed
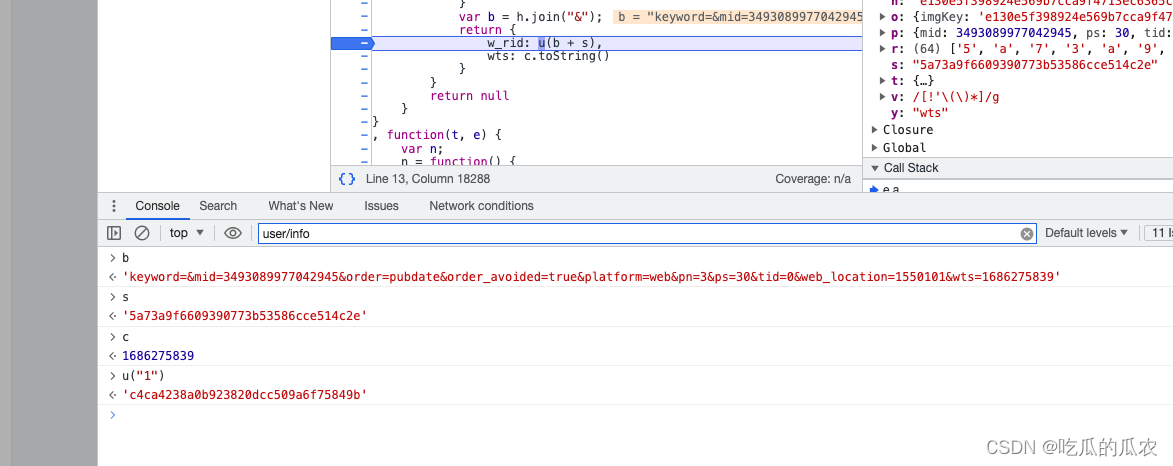
看加密那些参数
{“code”:-403,“message”:“访问权限不足”,“ttl”:1}

发现 就是 w_rid wts加密,u(b+s) 具体参数都在下面列出来了,也可以看出md5
完整代码
# -*- coding:utf-8 -*-
# 享受雷霆感受雨露
# author xyy 23 11
import datetime
import time
import requests
import random
import base64
import json
from urllib.parse import urlencode
from hashlib import md5
from retrying import retry
# 代理
def get_proxy():
return {}
# Md5 加密函数 32 返回32位的加密结果
def md5_use(text: str) -> str:
result = md5(bytes(text, encoding="utf-8")).hexdigest()
return result
# 通过时间字符形式 返回时长格式
def unify_duration_format(duar_str_or_s: str):
"""
01:11 -> 71,'00:01:11'
00:01:11 -> 71,'00:01:11'
:param duar_str: '01:11' or '00:01:11'
:return: 71, '00:01:11'
"""
error = 0, ''
def hms(m: int, s: int, h=0):
if s >= 60:
m += int(s / 60)
s = s % 60 #
if m >= 60:
h += int(m / 60)
m = m % 60
return h * 60 * 60 + m * 60 + s, str(h).zfill(2) + ':' + str(m).zfill(2) + ':' + str(s).zfill(2)
try:
s = int(duar_str_or_s)
except:
pass
else:
return hms(m=s % 3600 // 60, s=s % 60, h=s // 3600)
try:
if duar_str_or_s:
duar_list = duar_str_or_s.split(':')
if len(duar_list) == 2:
return hms(m=int(duar_list[0]), s=int(duar_list[1]))
elif len(duar_list) == 3:
return hms(m=int(duar_list[1]), s=int(duar_list[2]), h=int(duar_list[0]))
else:
return error
else:
return error
except Exception as e:
return error
def base64_encode(encoded_str, encode='utf-8'):
"""
Base64解密函数
:param encoded_str: Base64编码的字符串
:return: 原始的二进制数据
"""
encoded_str = encoded_str.encode(encode)
encoded_str = base64.b64encode(encoded_str)
encoded_str = encoded_str.decode()
return encoded_str.strip('=')
def get_dm_cover_img_str(num=650):
num = random.randrange(350, 651)
sss = f'ANGLE (Intel Inc., Intel(R) Iris(TM) Plus Graphics {num}, OpenGL 4.1)Google Inc. (Intel Inc.)'
dm_cover_img_str = base64_encode(sss)
return dm_cover_img_str
# 解析ifno
def analysis_parms(info_json):
lis = info_json.get("data",{}).get("list",{}).get("vlist",[])
now_count = int(info_json.get("data",{}).get("page",{}).get("pn"))*int(info_json.get("data",{}).get("page",{}).get("ps"))
all_count = int(info_json.get("data",{}).get("page",{}).get("count"))
has_more = True if now_count<=all_count else False
lis_dic_ifno = []
for each in lis:
dic_info = dict()
dic_info["play_num"] = each.get("play","")
dic_info["like_num"] = each.get("photo","")
dic_info["vid"] = each.get("aid","")
dic_info["comment_num"] = each.get("comment","")
dic_info["url"] = "https://www.bilibili.com/video/{}".format(each.get("bvid",""))
dic_info["title"] = each.get("title","")
duration, duration_str = unify_duration_format(each.get("length",""))
dic_info["duration"] = duration_str
dic_info["cover"] = each.get("pic","")
dic_info["uid"] = each.get("mid","")
dic_info["author_name"] = each.get("author","")
dic_info["author_url"] = "https://space.bilibili.com/{}".format(each.get("mid",""))
dic_info["pubtime"] = each.get("created","")
if dic_info["pubtime"]:
dic_info["pubtime"] = datetime.datetime.fromtimestamp(int(str(dic_info["pubtime"])[:10])).strftime("%Y-%m-%d %H:%M:%S")
dic_info["photoUrl"] = each.get("pic","") # 这个是默认的播放的地址 完整版的
lis_dic_ifno.append(dic_info)
return lis_dic_ifno,has_more
# 通过链接获取对应的信息
@retry(stop_max_attempt_number=9, wait_fixed=20)
def get_parms(userId="", pcursor=1, keyword=""):
h = {
'authority': 'api.bilibili.com',
'cache-control': 'max-age=0',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-language': 'zh-CN,zh;q=0.9',
}
api = 'https://api.bilibili.com/x/space/wbi/arc/search'
dm_img_list = []
dm_img_list = json.dumps(dm_img_list, separators=(',', ':'))
params = { # 顺序很重要
"dm_cover_img_str": get_dm_cover_img_str(),
"dm_img_list": dm_img_list,
'keyword': keyword,
"mid": userId,
"order": "pubdate",
"order_avoided": "true",
"platform": "web",
"pn": pcursor,
"ps": "30",
"tid": "0",
"web_location": "1550101",
"wts": str(int(time.time())),
}
response = requests.get('https://space.bilibili.com', headers=h)
cookies = dict(response.cookies)
w_rid = md5_use(urlencode(params) + 'ea1db124af3c7062474693fa704f4ff8')
params['w_rid'] = w_rid
h.update({'referer': f'https://m.bilibili.com/space/{userId}'})
res = requests.get(
api,
headers=h,
params=params,
cookies=cookies,
proxies=get_proxy(),
timeout=15,
)
if '风控校验失败' in res.text:
print('retrying...')
raise
# print(res.text)
return res.json()
# 主要的执行的函数
def run(userId="",pcursor=1,max_list_page=1,last_list=None,keyword=""):
"""
userId 用户ID
pcursor 起始页
max_list_page 截止页
keyword 搜索关键词 默认空
"""
# last_list = []
if last_list is None:
last_list = []
try:
ever_page_info = get_parms(userId=userId,pcursor=pcursor,keyword=keyword)
lis_dic_ifno,has_more = analysis_parms(ever_page_info)
last_list.extend(lis_dic_ifno)
# print(pcursor,has_more)
if pcursor<max_list_page and has_more :
pcursor+=1
return run(userId=userId,pcursor=pcursor,max_list_page=max_list_page,last_list=last_list,keyword=keyword)
except Exception as e:
return last_list
return last_list
if __name__ == '__main__':
"""
pn 翻页 /每页30条
"""
userId = "3493089977042945" #
pcursor = 1 # 启始页
max_list_page = 3 # 终止页面
keyword = "老公" # 搜索关键词
info = run(userId=userId,pcursor=pcursor,max_list_page=max_list_page,keyword=keyword)
print(info)
print(len(info))
小结
以上 就完成对主页视频采集
欢迎👏关注我的GitHub 欢迎star
我会分享一些平时的爬虫小例子 我们一起讨论

















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









