







归一化
文章目录
归一化的作用
归一化让(??的)分布相近, 让模型收敛更快, 可以用更大的学习率
为什么需要归一化
神经网络训练开始前,都要对输入数据做一个归一化处理。原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每个batch训练数据的分布各不相同,那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
归一化还可以让很深的神经网络能够训练,隐藏层越深, 梯度越小, 可能导致不同层不能同时收敛
BatchNorm归一化的实现
B是一个batch的输入
要学习的参数是delta和beta
μ B = 1 m ∑ i = 1 m x i σ B 2 = D ( X ) x i ^ = x i − μ B σ B 2 + ε y i = δ x ^ i + β \mu_B = \frac{1}{m} \sum_{i=1}^m x_i \\ \\ \sigma_B^2 = D(X) \\ \\ \hat {x_i} = \frac{x_i - \mu_B}{\sqrt{\sigma^2_B + \varepsilon}}\\ \\ y_i = \delta\hat x_i + \beta μB=m1i=1∑mxiσB2=D(X)xi^=σB2+εxi−μByi=δx^i+β
归一化的用法
1. 使用顺序
卷积 归一 激活 池化

2. 训练集与测试集使用的不同
训练集是拿每一个batch的均值与方差去做归一化
而测试集若以相同方式进行有可能一个batch只有一个训练集, 无法进行归一化
测试集若不进行归一化输出会和训练集产生很大不同(训练集归一化, 但测试集没有归一化)
测试集用的均值和方差应该是整个数据集的均值和方差
全局均值方差的具体更新方式:
归一化与标准化的区别
标准化与归一化差别就在最后的线性变换上(所以归一化需要那个线性变换)
标准化和归一化都能压缩数据到(0~1)或者(-1~1)区间之内,但标准化会改变原来数据的分布, 标准化不会, 标准化只是拍瘪了原来的数据
归一化只是缩放了数据的范围, 标注化是使数据符合了一种新的分布(比如正态分布)PyTorch——解决报错“RuntimeError: running_mean should contain * elements not *”_墨门-CSDN博客
Fundamentals——神经网络中BN层的位置的Empirical Study - 知乎 (zhihu.com)
e.g.
1. 归一化
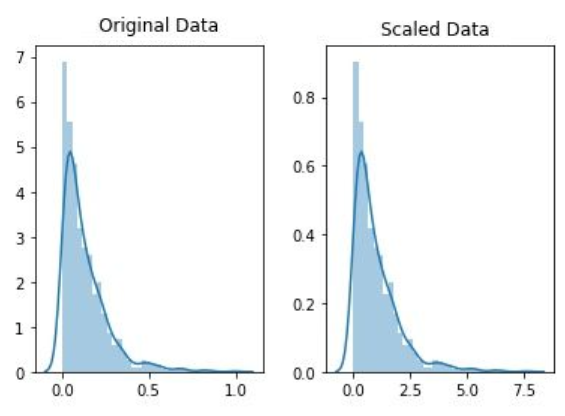
2. 标准化

为什么归一化可以加快模型的收敛速度
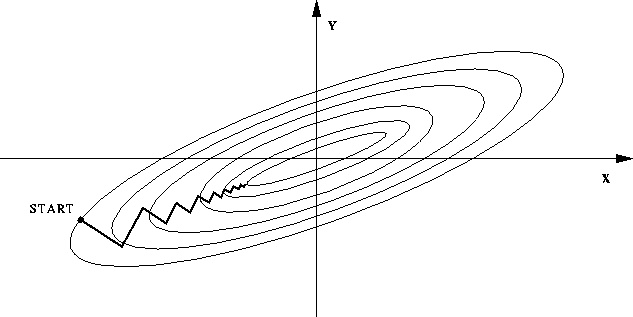
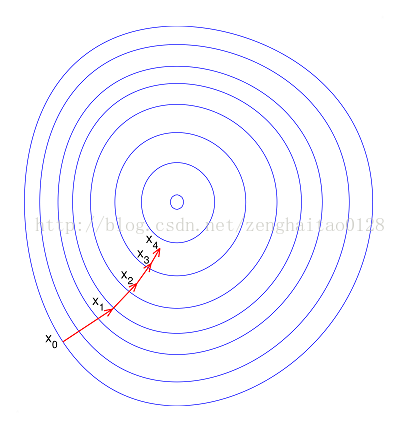
假设有两个变量,都是均匀分布,x1范围是[10000,20000],x2范围是[1,2]。有很多处于同一直线上的点,我们称这条直线为L。如果现在我们要做一个分类的话,x2几乎可以被忽略,x2很无辜的被干掉了,仅仅因为所谓量纲的问题。即便x2不被干掉,现在继续求解,来做梯度下降。 很显然,如果某一步我们求得的下降方向不在直线L上,几乎可以肯定肯定这步不会下降。这就会导致不收敛,或者收敛很慢。
不进行归一化:















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









