






代码地址:https://gitee.com/mindspore/models/tree/master/research/cv/AsConvSR
论文小结
本文提出的网络名为AsConvSR,结合一些高性能的算子,比如pixel-unshuffle,repeat upscaling,移除局部残差连接,提出了一个快且轻量级的超分网络。
此外,本文提出了一个可以根据输入特征(input features)调整卷积核的组合卷积(assembled convolution)。从实验表明,其效果比其他的高效超分模型要更好,且在运行时间和质量方面取得了最佳结果。
论文简介
之前的高效网络都是基于低分辨率(360P/540P/640P),这次挑战的分辨率为720P或1080P,之前的性能就显得有些不足。
本文的工作有重新评估一些复杂拓扑的网络架构,比如Enhanced Spatial Attention(ESA)和Residual Feature Distillation Block(RFDB)。这些结构可以提高SR网络的性能,但也会增加模型运行时间。所以本文的策略还是选择那些简单拓扑的网络,认为那是构建高效超分辨率网络的最佳选择。
这些选择包括:使用unPixelShuffle/PixelShuffle,简单拓扑的顺序卷积来提取特征,舍弃了所有在实际上会带来额外计算开销的中间跳跃连接(skip connection),只保留了一个全局跳跃连接以实现高效性。
作者认为,对于不同纹理的输入(树、建筑物、人等),在直观上,是需要复杂地使用不同的处理方法的。所以,作者提出了一个组合卷积(assembled convolution),可以让网络自适应地应用不同的卷积核。
与之前提出的动态卷积相比,本文的组合卷积更灵活和高效,因为它计算每个通道的最佳卷积核系数,并且该设计仅给整个网络带来微弱的计算成本和推理时间成本。
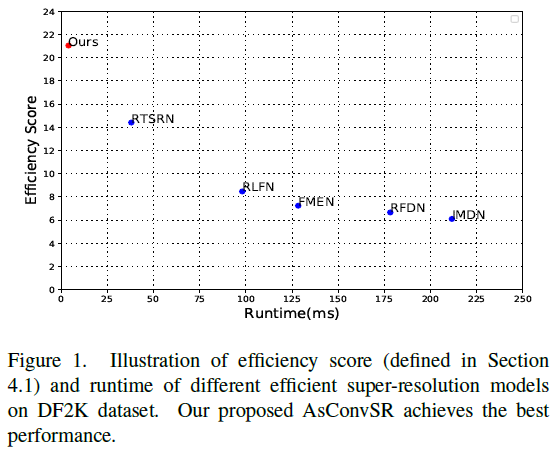
模型的性能如下图所示,高效性得分和运行时间是最好的,可以在一个单独的GPU上(NVIDIA Tesla V100)上达到720P和1080P的实时超分性能。
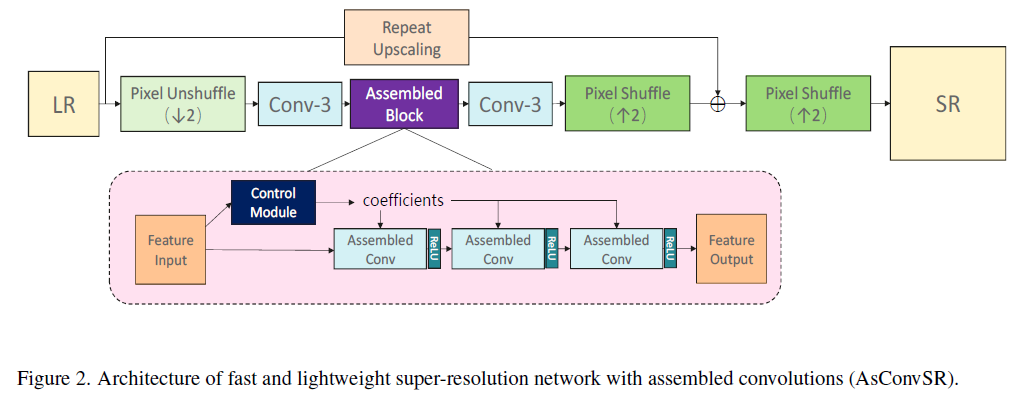
网络设计
实际中,对于大多数的计算设备,当通道数量小于一定水平( 16 16 16或 32 32 32)时,无法通过减少通道大小来减少运行时间。小通道尺寸也限制了设计的灵活性和SR网络的性能。
skip connection
除了卷积层,跳跃连接也占据了大量的计算资源。它们不仅需要添加两个特征映射,而且还必须缓存之前的特征映射,这增加了访问内存的运行时间。
在超分网络中,跳跃连接主要分为两类:(1)在网络架构内部中,比如残差模块的跳跃连接;(2)全局残差。
依据后面的实验,可以知道,网络结构内部的跳跃连接可以移除。但全局残差不可以简单地移除,因为那可以稳固网络的训练,以及加速收敛。
Assembled Block
前言
分而治之的思想被广泛地应用于图像处理领域,从经典方法到深度学习算法。例如,去除平坦区域的噪声和压缩效应,在边缘占优势(edge-dominant areas)的区域锐化边缘,在纹理丰富的区域生成更精细的细节。这些直觉是基于patch(patched-base)的超分辨率的基础。
比如ClassSR使用一个分类网络来决定Patch是使用简单的子网来节省FLOPs还是使用一个复杂子网来得到更好的性能。但依据作者的实验,将图像分割并将其重新组合的过程也显著增加了网络的总运行时间。以一张1080p图像作为输入,组装patch的过程总共花费
7
7
7ms,而整个运行耗时仅需要
30
30
30ms。
另一方面,动态卷积只会导致运行耗时的少量增加,因为动态消耗处于权重级别。动态卷积的主要计算成本仍然是
3
×
3
3\times3
3×3卷积,这使得它非常适合超分辨率任务。
模块细节
assembled block包含一个控制模块和三个组合卷积。如下图所示,控制模块可以从特征图中得到组合参数:
c
o
e
f
f
=
F
c
o
n
t
r
o
l
(
f
i
n
)
\mathbb{coeff}=\mathcal{F}_{control}(f_{in})
coeff=Fcontrol(fin)
f
i
n
f_{in}
fin是输入特征图,
f
i
n
∈
R
B
×
C
i
×
H
×
W
f_{in}\in \mathcal{R}^{B\times C_i \times H \times W}
fin∈RB×Ci×H×W,
c
o
e
f
f
∈
R
B
×
C
o
×
E
\mathbb{coeff}\in\mathcal{R}^{B\times C_o \times E}
coeff∈RB×Co×E,
E
E
E是候选卷积核的数量。
E
E
E的作用,类似于SENet的Expand,只不过是作用于Weight上。
实际上和channel attention的类似,但对象是权重,而不是激活层。
K
=
c
o
e
f
f
⊗
k
b
a
s
i
s
K=coeff \otimes k_{basis}
K=coeff⊗kbasis
f o u t = c o n v ( f i n ; K ) f_{out}=conv(f_{in};K) fout=conv(fin;K)
其中
k
b
a
s
i
s
∈
R
E
×
C
i
×
k
s
×
k
s
k_{basis}\in\mathcal{R}^{E\times C_i \times k_s \times k_s}
kbasis∈RE×Ci×ks×ks是候选卷积核,
K
K
K是卷积的组合kernel,
k
s
k_s
ks是kernel size。
c
o
e
f
f
coeff
coeff和
k
b
a
s
i
s
k_{basis}
kbasis先要分别reshape成
R
(
B
×
C
o
)
×
E
R^{(B\times C_o)\times E}
R(B×Co)×E和
R
E
×
(
C
i
×
k
s
×
k
s
)
R^{E\times (C_i\times k_s \times k_s)}
RE×(Ci×ks×ks),然后进行矩阵乘法得到最终的卷积核
K
∈
R
B
×
C
o
×
C
i
×
k
s
×
k
s
K\in \mathcal{R}^{B\times C_o \times C_i \times k_s \times k_s}
K∈RB×Co×Ci×ks×ks。
不同batches大小的数据需要不同的卷积核,特征图的batch维度被reshape到channel维度,然后使用group卷积来计算最后的输出特征图。

动态卷积
动态卷积和组合卷积的对比如下图所示。动态卷积基于卷积核的base生成整个卷积核(所有通道),可以表示为:
K
d
y
n
a
m
i
c
=
∑
i
=
0
E
c
o
e
f
f
i
×
k
i
d
y
,
k
i
d
y
∈
R
C
o
×
C
i
×
k
s
×
k
s
(5)
K_{dynamic}=\sum_{i=0}^E \mathcal{coeff}_i \times k_i^{dy}, k_i^{dy}\in \mathcal{R}^{C_o\times C_i \times k_s \times k_s} \tag{5}
Kdynamic=i=0∑Ecoeffi×kidy,kidy∈RCo×Ci×ks×ks(5)
其中, K d y n a m i c ∈ R C o × C c × k s × k s K_{dynamic}\in \mathcal{R}^{C_o\times C_c\times k_s \times k_s} Kdynamic∈RCo×Cc×ks×ks是卷积的卷积核, k i d y k_i^{dy} kidy是候选核,与 K d y n a m i c K_{dynamic} Kdynamic有相同的维度。
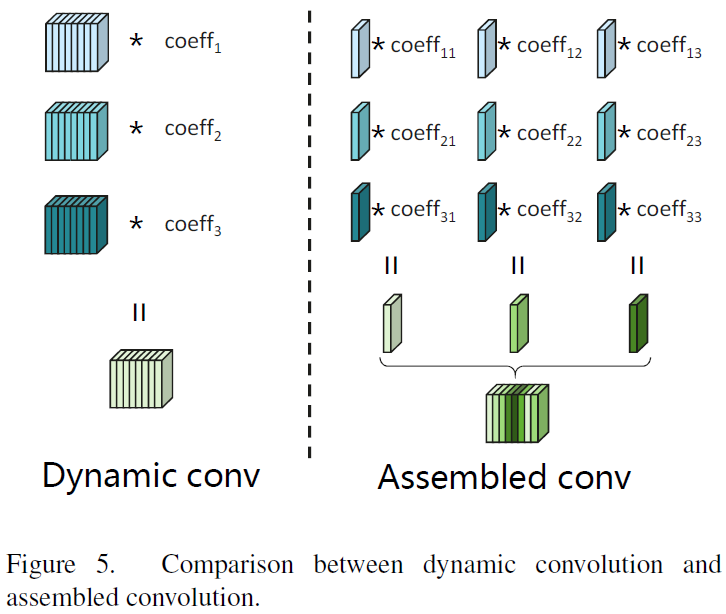
组合卷积
组合卷积,为每个channel生成最优卷积核系数,可表示为:
K
j
r
s
=
∑
i
=
0
E
c
o
e
f
f
i
,
j
×
k
i
r
s
,
k
i
r
s
∈
R
C
i
×
k
s
×
k
s
(6)
K_j^{rs}=\sum_{i=0}^E\mathcal{coeff}_{i,j}\times k_i^{rs},k_i^{rs}\in\mathcal{R}^{C_i\times k_s \times k_s} \tag{6}
Kjrs=i=0∑Ecoeffi,j×kirs,kirs∈RCi×ks×ks(6)
K a s s e m b l e d = c a t ( K 0 r s , K 1 r s , . . . , K C o r s ) (7) K_{assembled}=\mathcal{cat}(K_0^{rs}, K_1^{rs}, ...,K_{C_o}^{rs}) \tag{7} Kassembled=cat(K0rs,K1rs,...,KCors)(7)
其中, K j r s K_j^{rs} Kjrs是卷积核第 j j j个输出channel, K j r s ∈ R C c , k s , k s K_j^{rs}\in\mathcal{R}^{C_c, k_s, k_s} Kjrs∈RCc,ks,ks, k i d y k_i^{dy} kidy是assembled kernel的基础。
卷积 K a s s e m b l e d K_{assembled} Kassembled是所有 K j r s K_j^{rs} Kjrs的组合。
与动态卷积相比,本文提出的组合卷积在参数生成方面具有耕细粒度和更高的灵活性,从而在超分辨率方面具有更好的性能。实际上,相当于动态卷积扩展了一下。
网络
网络架构如下图所示,使用两个 C o n v 3 × 3 \mathbb{Conv}3\times3 Conv3×3连接组合模块。前面的 C o n v 3 × 3 \mathbb{Conv}3\times3 Conv3×3输出channel为 32 32 32( × 2 \times 2 ×2)或 64 64 64( × 3 \times 3 ×3),后面的 C o n v 3 × 3 \mathbb{Conv} 3\times 3 Conv3×3输出channel为 48 48 48( × 2 \times 2 ×2)或 108 108 108( × 3 \times 3 ×3)。后面连接两个pixelShuffle,是为了添加两个全局残差连接。
论文实验
训练细节
训练数据集共3450张图像,来自于DIV2K和Flick2K数据集。在五个基准数据集上测试模型的性能:DF2K(100张侧视图),Set5,Set14,BSD100和Urban100.
在RGB颜色空间评估PSNR和SSIM,依据NTIRE 2023 实时超分挑战的排名规则计算模型性能分数: S c o r e = 2 P S N R − b i c u b i c × 2 C × r u n t i m e (8) Score=\frac{2^{PSNR-bicubic}\times2}{C\times \sqrt{runtime}} \tag{8} Score=C×runtime2PSNR−bicubic×2(8)
其中,'bicubic’是双三次差值的PSNR, C C C是常数,设为 0.1 0.1 0.1。使用 Adam 作为优化器, β 1 = 0.9 , β 2 = 0.9999 \beta_1=0.9,\beta_2=0.9999 β1=0.9,β2=0.9999,初始学习率为 5 × 1 0 − 4 5\times10^{-4} 5×10−4,每 2 × 1 0 5 2\times10^5 2×105次迭代衰减一次。整个训练过程迭代 1 × 106 1\times106 1×106次,使用 Charbonnier 作为损失函数。在训练的时候,HR的patchSize设为 256 × 256 256\times 256 256×256,即LR的patchSize为 128 × 128 128 \times 128 128×128,batchSize为32。增强手段为随机旋转和翻转。
定量结果
与当前最先进的高效超分辨率模型进行比较,模型有IMDN、RFDN、RLFN、FMAN和RTSRN,对比结果如下表所示。AsConvSR表示规模较小的模型,AsConvSR-L有两个组合模块,每个模块有 128 128 128个通道和 128 128 128个侯选核。AsConvSR只有一个 32 32 32通道的组装块。
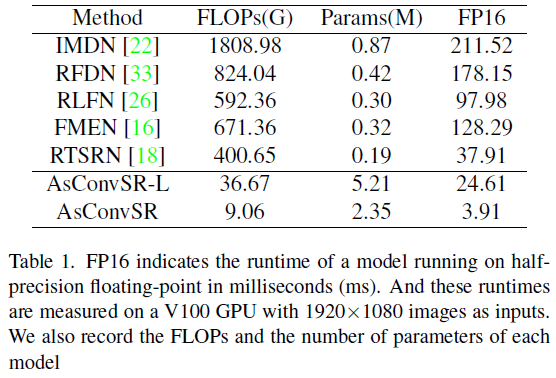
如上表所示,AsConvSR的FLOPs只有RTSRN的 2.26 % 2.26\% 2.26%,运行时间只有RTSRB的 10.33 % 10.33\% 10.33%。由于组合卷积具有大量的权值基,所以本文的模型参数是另一个模型的数倍。然而,本文的模型仍然比其他模型快得多,这表明组装卷积并不占用太多的计算资源,大部分计算预算仍然被特征映射上的常规卷积所消耗。
与其他高效SR模型的定量比较如下表所示。本文方法可以在每个基准数据集上得到最好的分数。从表中可以看出,其中分数较高,但是PSNR和SSIM在其中并不突出,但都比其中最快的RTSRN好些。这也符合NTIRE 2023超分挑战的分数公式预期:要更快的运行速度。

视觉比较
从下图 6 6 6可以看出,AsConvSR-L在恢复压缩纹理方面要比RTSRN要好。与RLFN和FMEN相比,在锐度方面也有竞争力。

下图 7 7 7是AsConvSR的可视化结果,对比双三次插值时,AsConvSR的视觉效果明显优于双三次插值,也仅仅使用了 3.91 3.91 3.91ms,达到与RTSRN相似的质量。总的来说,AsConvSR-L和AsConvSR都保持了恢复精度,并显著缩短了模型运行时间。

消融学习
模块消融
网络结构,不同模块的消融学习如下,分数使用NTIRE 2023的计算方式,即上面的公式(8)。验证集为DF2K数据集。
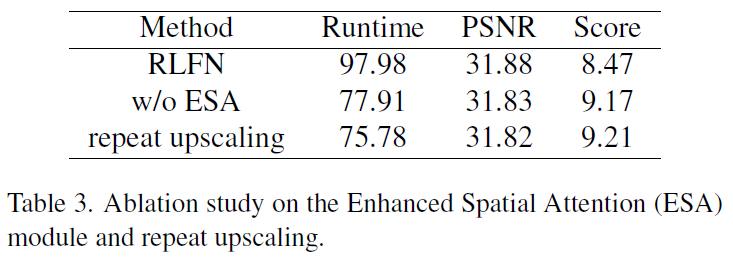
使用RLFN作为baseline,验证ESA和repeat upscaling的高效性。从上表可以看到,增加EAS确实能提高PSNR,但它增加了
20.07
20.07
20.07ms的运行时间,这是整个模型运行时间的
25.72
%
25.72\%
25.72%。这个现象显示,ESA对于高分辨率图像的输入来说不够高效。
然后使用repeat upscaling 替换模型中的双三次插值,这能减少
2.13
2.13
2.13ms的运行时间。在实时性为
30
30
30ms的标准下,使用repeat upscaling可以节省
7.1
%
7.1\%
7.1%的运行耗时。这表明,repeat upscaling 是实用且高效的。
UnPixelShuffle消融
Pixel-Unshuffle(1)表示将图像的原图分辨率作为网络的输入,没有使用pixel-unshuffle来对宽高进行采样channel数据。Pixel-Unshuffle(x)表示从高度和宽度维度到通道维度以间隔x采样像素。x越大,通道数量就越大。所以,对下标来说,对应网络的channel分别为 64 64 64, 128 128 128, 192 192 192和 256 256 256,这样可以确保每次试验中FLOPs的一致性。

如上表所示,尽管实验中的FLOPs保持了一致,但随着pixel-unshuffle因子的提升,PSNR和运行时间都在下降。
这表明:(1)在FLOPs不变的情况下,更大的通道尺寸和更小的分辨率的卷积在NVIDIA GPU上运行得更快。。(2)unPixelShuffle打乱了特征的空间分布,降低了模型的性能。
综合来看,作者选择 2 2 2作为随后实验的pixel-unshuffle因子。
残差结构消融
残差结构和卷积算子的bias消融学习如下表所示。
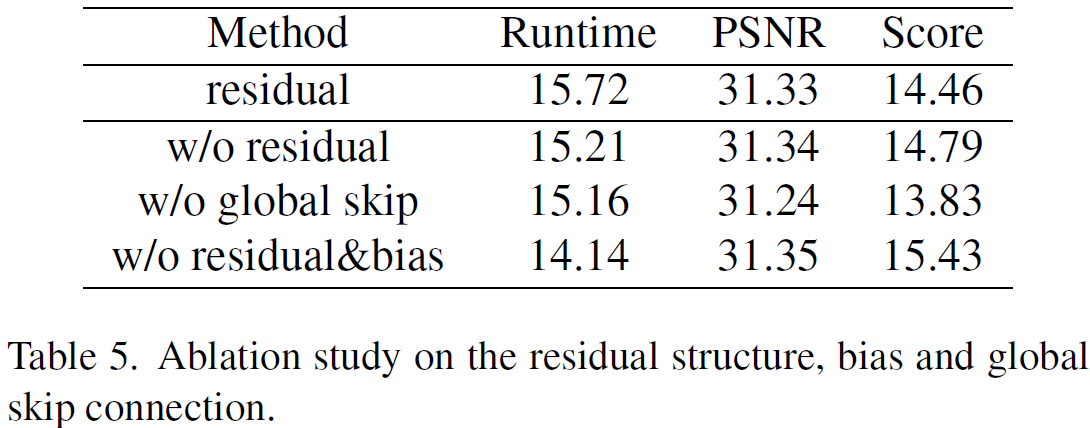
在没有残差连接的网络中,作者在某个卷积上添加了 1 1 1个输出通道。这是因为按照RepOpt的指示,如此修改相当于增加了对应的跳跃连接,虽然没有明确指示。
在丢掉残差结构的网络,其PSNR仍保持着,但运行时间有所下降。
相反,全局残差连接证明了其必要性。因为移除掉全局残差之后,PSNR掉的非常多,而且训练过程变得不稳定。
同时,作者发现移除卷积中的姹姹,可以提高网络的性能。
结论:对于超分模型来说,移除全局残差是不可取的。在接下来的实验中,作者选择移除残差结构和卷积中的偏置。
Channel Size消融
不同channel size对于模型的性能影响如下表所示。
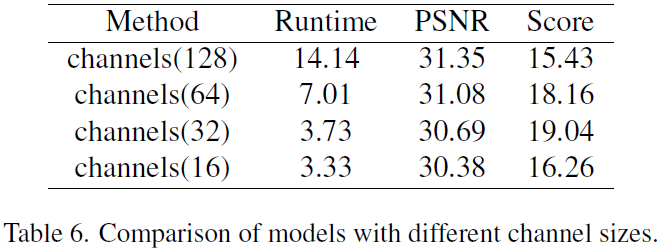
当通道数量改变时,FLOPs和运行时间不会成比例地减少或增加。
128channel的网络的FLOPs几乎是64channel网络的
4
4
4倍,但运行时间只有
2
2
2倍。
然而考虑到PSNR的恶化速度,64channel在效率得分上仍然胜出。
此外,减少通道所带来的速度提升也是有限度的。
在Tesla V100平台上,当网络减少到
16
16
16通道时,运行时间的减少不再明显。
考虑到运行时间和PSNR,作者认为 32 32 32是模型的最佳通道数。
动态卷积 vs 组合卷积
如下表所示,替换传统卷积为动态卷积,只增加了 0.11 0.11 0.11ms的运行时间,但能带来0.14dB的PSNR提升。这证明了分而治之思路的有效性。

此外,组合卷积在运行时间基本不变的情况下,提高PSNR和较大幅度地提高了NTIRE 2023超分挑战的分数。
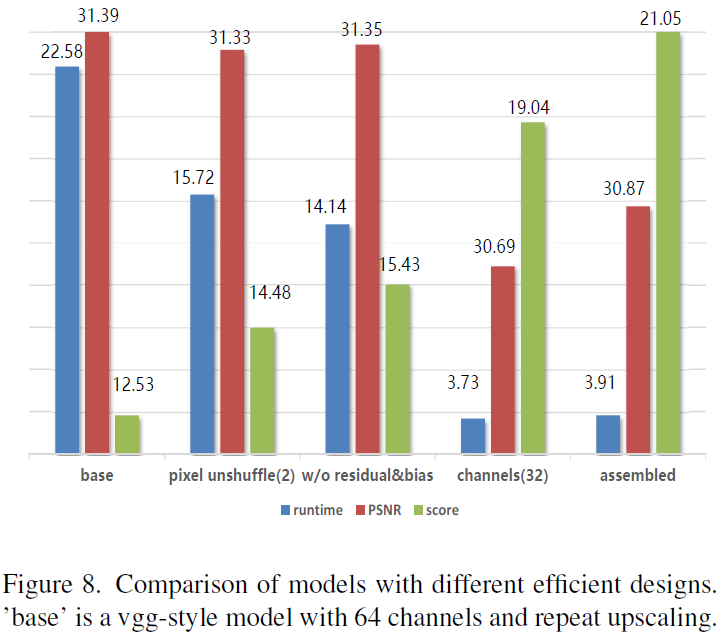
所有设计对比
减少网络的通道数,可以减少运行时间,进而可以较大幅度地提高NTIRE 2023超分挑战的分数,但也减少了PSNR指标。组合卷积可以提高PSNR,同时基本不增运行时间,从而对分数带来较大的提升。
比赛版本
参加NTIRE 2023实时超分挑战,本文方法获得了Track 1赛道( × 2 \times 2 ×2)的第一名。和前面所述的最大区别在于训练数据上。在比赛中,作者使用了DIV2K,Flick2K,DIV8K,GTAV 和 LIU4K-V2用于训练。其他超参和上述实验保持一致。如下表所示,本文方法比第二名最好的模型在PSNR搞了0.39dB,同时有最高的分数。
















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









