







论文小结
这是17年的老论文了,Transformer的出处,刚发布时的应用场景是文字翻译。BLUE是机器翻译任务中常用的一个衡量标准。
在此论文之前,序列翻译的主导模型是RNN或者使用编解码器结构的CNN。本文提出的Transformer结构不需要使用循环和卷积结构,是完全基于注意力机制的模型。Transformer在序列转换上具有高并行度,在两个机器翻译的任务上都得到了卓越的成果,且其训练时间显著减少。在WMT2024的英语转法语翻译任务上,本文的Transformer模型在 8 8 8张P100 GPU上训练 3.5 3.5 3.5天达到了收敛目标。
同时,作者表示Transformer框架可以泛化到其他任务上,效果都能很好。现实也是如此,ViT在各种任务上也是一次次刷新指标,与CNN相印上升。
与其他结构的对比
RNN结构存在的问题
RNN的结构,是2017年之前常用于处理时序问题的。但其存在两个问题:
- (1)在 t t t时刻的输入有前一个时刻的隐藏层输出 h t − 1 h_{t-1} ht−1,所以时序计算是串行的,难以并行化进行加速计算。因此,RNN模型在GPU/TPU这种并行化设计的硬件上性能会较差。
- (2)RNN结构中的时序信息是逐步传递的,当时序信息较长时,隐藏层状态 h t h_t ht可能会遗失历史信息。如果想让 h t h_t ht尽可能保留历史信息,则要让 h t h_t ht尽量大,就会让内存的开销更大。
Transformer结构能够优化训练时难以并行训练的问题,能够大大减少并行时间。Transformer能够并行的原因是没有使用RNN的循环结构。同时,Transformer架构可以一次将所有的输入信息放入编码器中处理,能够一个结构就让第一个向量和最后一个向量联系起来,因而也能缓解第二个遗失历史信息的问题。
Attention机制在RNN中已经有所应用,主要是在循环中将编码器(encoder)的信息传递到解码器(decoder)中。
CNN结构处理时序计算存在的问题
CNN结构,如果要让任意位置的输入和任意位置的输出产生联系(如果产生长远信息联系),则需要将网络的深度拉大。因为CNN使用的滑动窗口是比较小的( 3 × 3 , 5 × 5 3\times 3, 5\times 5 3×3,5×5),能看到的单层信息比较少。这就使得长远位置之间的依赖关系学习变得更加困难。
在Transformer中,使用的attention机制可以将输入的任意位置信息联系起来。尽管使用attention机制会将有效维度降低(类似于CNN中的卷积,一个kernel输出一个channel),使用多头注意力机制(Multi-Head Attention)来解决这个问题。
Self-Attention
self-attention,自注意力,是一种将单个序列的不同位置相关联的注意力机制。形象而言,是不添加额外输入的情况下,自己能够完成的抽象Attention动作的结构。
Transformer结构
大多数具有竞争力的转换模型都是由编码器-解码器(encoder-decoder)结构组成。模型是自回归模型。自回归的意思为上一时刻的输出要参与当前时刻的输入组成部分(除了原始输入,还需要上一时刻的输入)。
原始输入序列是长度为 n n n的词,表示为 x = ( x 1 , . . . , x n ) x=(x_1,...,x_n) x=(x1,...,xn),将其编码成长度为 n n n的向量 z = ( z 1 , . . . , z n ) z=(z_1,...,z_n) z=(z1,...,zn),输出的目标是长度为 m m m的序列 y = ( y 1 , . . . , y m ) y=(y_1,...,y_m) y=(y1,...,ym)。
Transformer的架构设计也是encoder-decoder方式。具体来说,就是将self-attention和全连接层堆叠在一起。Transformer架构如下图所示。
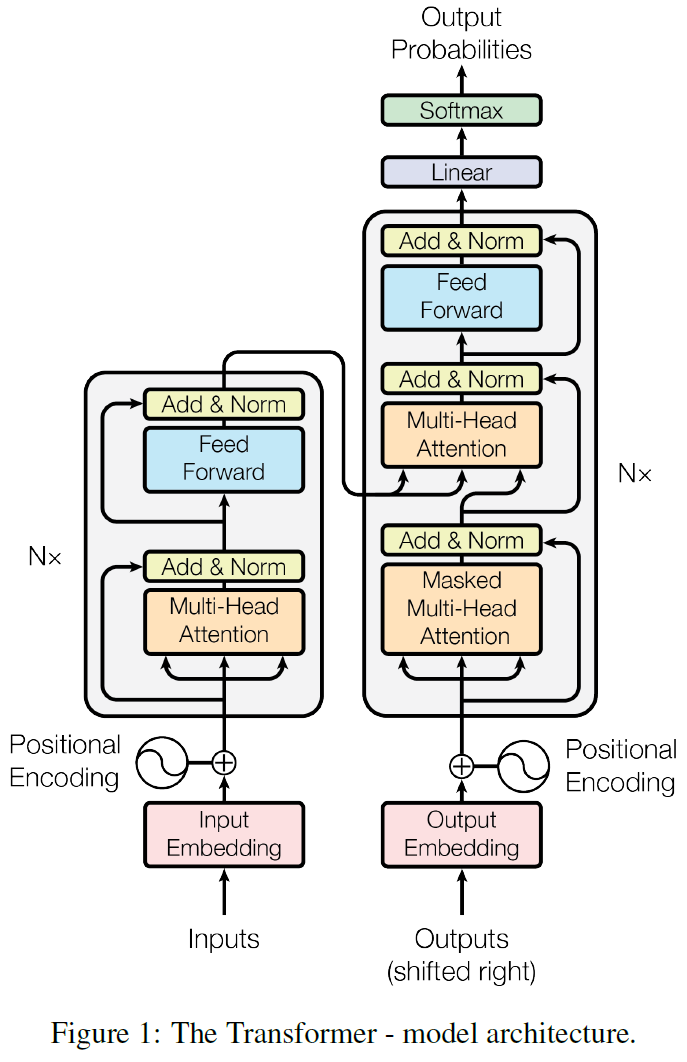
结构解析
如上图所示,Transformer的整体结构是比较简单明了的。就是一个编码器,一个解码器组成。每个编码器和解码器都重复各自的模块N次。参数 N N N在Transformer中默认为 6 6 6。
Encoder
Encoder里面由 N N N个相同结构的块组成,每个块由两个组成部分:(1)多头自注意力机制(multi-head self-attention mechanism);(2)全连接层(Feed Forward)网络。每个子块都使用残差链接和 Layer Normalization(LN),表示为 O u t = L N ( I n + S u b l a y e r ( x ) ) \mathcal{Out}=\mathbb{LN}(\mathcal{In + \mathcal{Sublayer}(x)}) Out=LN(In+Sublayer(x))。为了方便残差连接的使用,所有模块的输入输出维度 d m o d e l = 512 d_{model}=512 dmodel=512。整个模型的可调参数只有两个,为 N N N和 d m o d e l d_{model} dmodel。(后面的bert、GPT基本也是可调参数只有 N N N和 d m o d e l d_{model} d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









