







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 功能:WebWalker通过多智能体框架和垂直探索策略,帮助模型处理长上下文信息。
- 数据集:提供WebWalkerQA数据集,包含680个多语言、多领域的查询,用于测试模型性能。
- 应用:适用于智能信息检索、多源信息整合、数据收集与分析等场景。
正文(附运行示例)
WebWalker 是什么
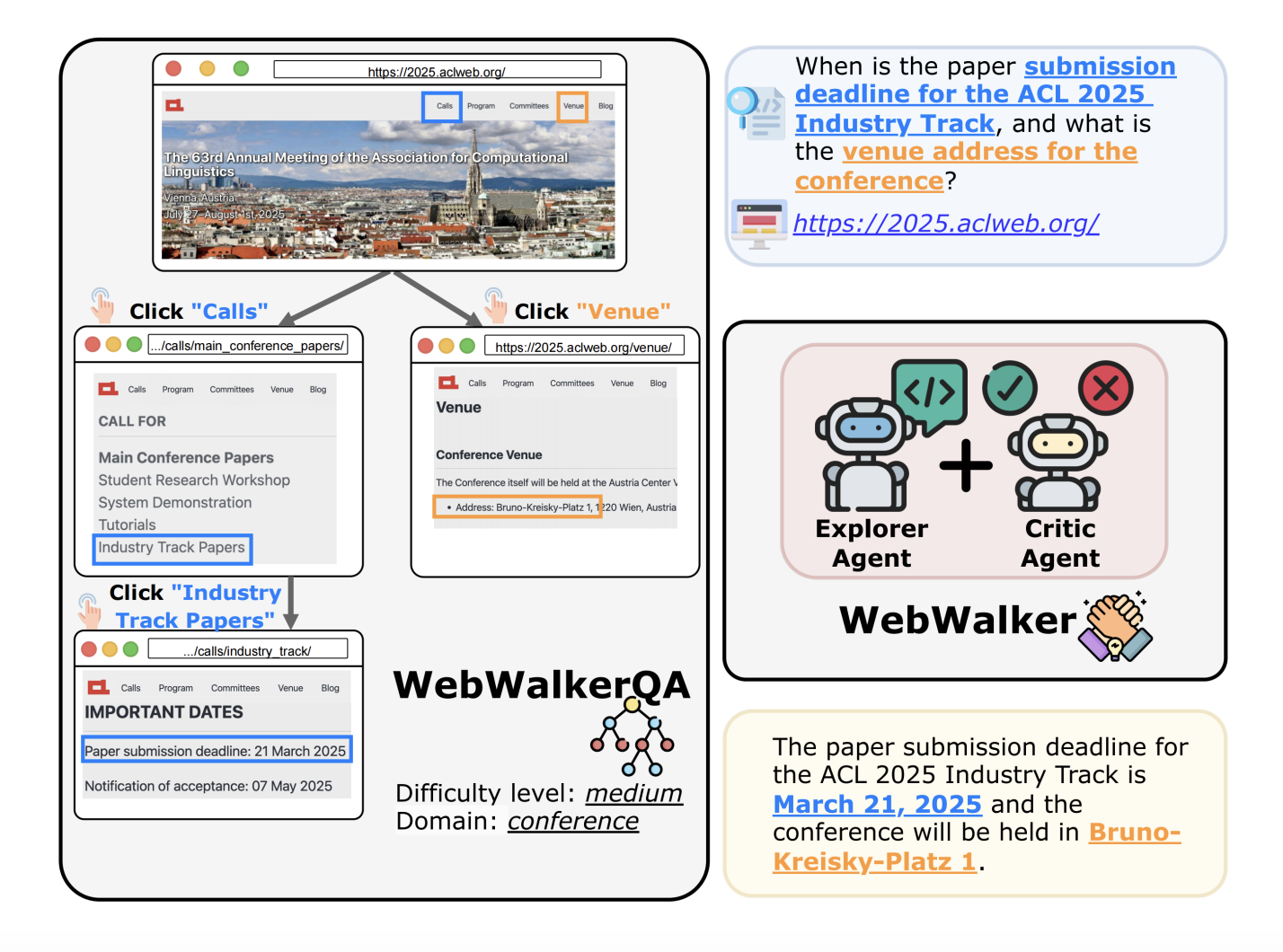
WebWalker是阿里巴巴自然语言处理团队开发的工具,旨在评估和提升大型语言模型(LLMs)在网页浏览任务中的性能。通过模拟网页导航任务,WebWalker帮助模型更好地处理长上下文信息,提升其在复杂网页浏览任务中的表现。
WebWalker的核心功能包括多智能体框架、垂直探索策略以及WebWalkerQA数据集。这些功能使得WebWalker能够有效管理内存、深入探索网页内容,并通过数据集测试模型的性能。
WebWalker 的主要功能
- 多智能体框架:支持模型在浏览网页时保持对之前交互的记忆,更好地处理需要长上下文信息的任务。
- 垂直探索:深入探索单个页面或相关页面链,寻找和回答问题所需的信息。
- WebWalkerQA 数据集:包含680个具有挑战性的查询,覆盖多语言和多领域的网页内容,用于测试模型的性能。
- 性能评估:通过HuggingFace的Leaderboard提交和比较不同方法的性能。
如何运行 WebWalker
1. 环境配置
首先,确保你已经安装了Python 3.10,并创建了一个虚拟环境:
conda create -n webwalker python=3.10
git clone https://github.com/alibaba-nlp/WebWalker.git
cd WebWalker
pip install -e .
pip install -r requirements.txt
crawl4ai-setup
crawl4ai-doctor
2. 运行本地演示
在运行之前,请设置你的API密钥:
export OPEN_AI_API_KEY=YOUR_API_KEY
export OPEN_AI_API_BASE_URL=YOUR_API_BASE_URL
或者使用Dashscope API密钥:
export DASHSCOPE_API_KEY=YOUR_API_KEY
然后,运行app.py文件:
cd src
streamlit run app.py
3. 运行RAG系统
你可以通过以下命令运行RAG系统:
cd src
python rag_system.py --api_name [API_NAME] --output_file [OUTPUT_PATH]
资源
- GitHub 仓库:https://github.com/Alibaba-nlp/WebWalker
- HuggingFace 仓库:https://huggingface.co/datasets/callanwu/WebWalkerQA
- arXiv 技术论文:https://arxiv.org/pdf/2501.07572
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









