







TP:True positive
预测为1,实际也为1
FP:False positive
预测为1,实际为0
FN:False negative
预测为0,实际为1
TN:True negative
预测为0,实际为0
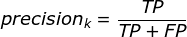

总的来说就是,准确率为在所有预测为1中占正确的比例,召回率为在所有实际为1中占正确的比例。
准确率(accuracy)
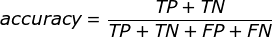
f1-score
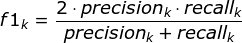
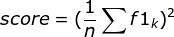
TP:True positive
预测为1,实际也为1
FP:False positive
预测为1,实际为0
FN:False negative
预测为0,实际为1
TN:True negative
预测为0,实际为0
总的来说就是,准确率为在所有预测为1中占正确的比例,召回率为在所有实际为1中占正确的比例。
准确率(accuracy)
f1-score











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


















 820
820





