







CVPR-2020 何凯明 动量对比无监督学习
Nips-2020 Jean-Bastien Grill 仅正样本对比学习
CVPR 2022 何凯明 MAE
文章目录
什么是自监督学习
没有人工标注标签的监督学习
可以将它看作没有人类参与的监督学习
标签仍然存在(因为需要有辅助内容来监督学习过程)
自监督学习分类
基于损失函数 loss function
基于构建辅助任务 pretext task
loss function
基于损失函数自监督学习方式,目的是度量模型的预测和固定目标之间的差别来学习一个好的特征
如jigsaw,有点类似拼图游戏,一张图像,将图像分成不同的小块,确定图像小块所在图像中的位置,每个位置代表一个监督的信息
如对比学习,如对图像进行4个90°角的翻转,可以看成一种监督,形成一种对比学习,学习图像特征。对比学习核心思想:
学习一个映射函数f,满足
输入的图像与正样本距离尽可能近,同时拉远负样本之间的距离
如对抗学习,GAN
pretext task
设计一种辅助任务,但目的并不在于解决设定的任务,而在于学习一个好的数据表示方式
比如MAE,对有噪声的图像进行重建,去噪
如着色自编码器,黑白图像生成彩色图像
(一个从我本科导师里偷师来的思路,用transformer的最后一层weight当词特征表示)
应用背景
小样本学习
代表论文
When does self-supervision imporve few-shot learning?
迁移学习
代表论文
IEEE - Category contrast for unsupervised domain adaptation in visual task
近期代表的自监督学习论文
CVPR-2020 何凯明 动量对比无监督学习
CVPR-2020 何凯明大佬的《Momentum Constrast for Unsupervised Visual Representation Learning》
利用对比学习方式构建一个队列更新的负样本对,进行自监督学习
论文地址:
https://openaccess.thecvf.com/content_CVPR_2020/papers/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.pdf
动机:
以前的对比学习方法,主要采用端到端的并行结构构建正负样本特征,或者是构建一种大的memory bank的负样本字典对,存在显存过大和特征不一致问题,显存end-to-end老毛病,特征不一致指epoch1和epoch100表现特征可能会不一致
基本思想:
两个公式 简单明了
目的:训练一个动态编码器进行字典查询任务
特点:大,字典数量要大,一致性,在训练得时候更新进化,尽可能使用新的特征,老的特征将其淘汰
左边是正常的编码器,右边是动量编码器,能够把每次迭代的batchsize的特征都储存在动量编码器中,一致性把老的给去掉
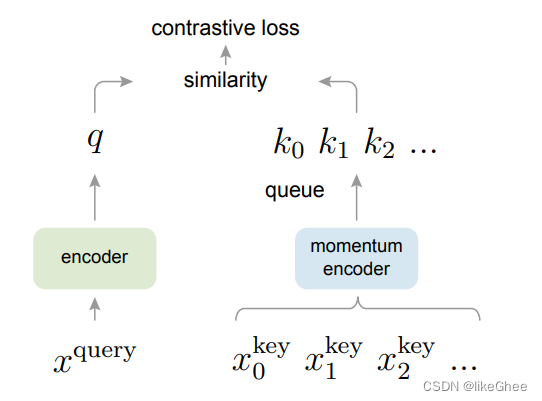
下面看看以往的自监督学习方案
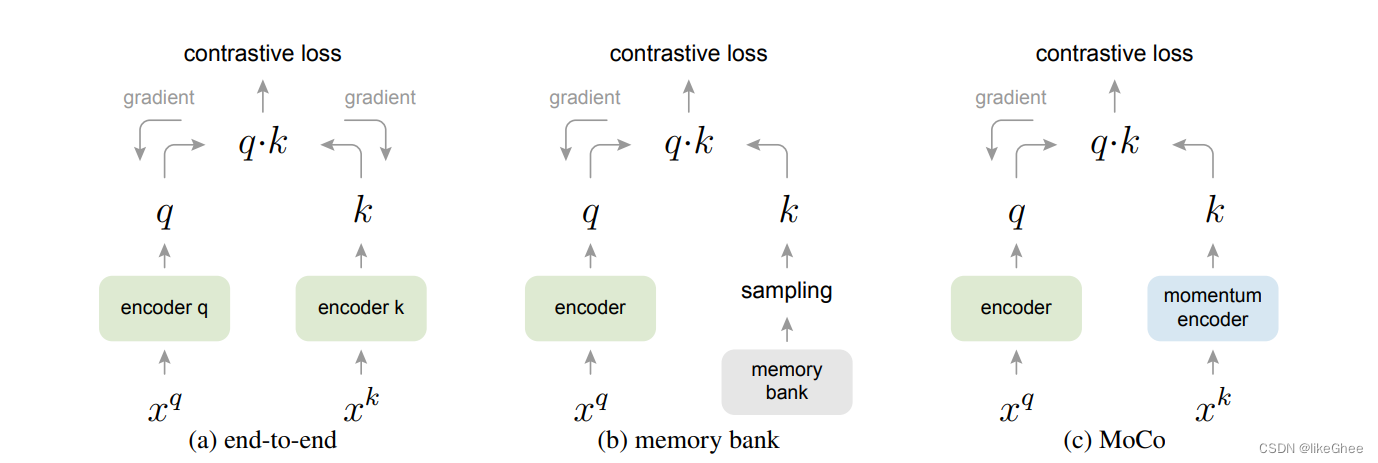
第一种end2end方式,字典大小和mini-batch大小相同,编码器q和k,编码是一致的,都要经过反向梯度传播,batch-size大一点显存就很可能不够用,单单1张图可能就需要几G的显存
第二种memory bank方式,为了储存更多的特征,没有使用编码器,直接进行储存,也不进行反向梯度,因此构建了一个十分大的bank与当前的mini-batch进行对比学习
memory bank 包含所有数据集所有数据的特征表示
一个样本的特征表示只有在它出现时候才在memory bank更新,因此具有较小的一致性,较老的特征没出现不会更新
更新只进行特征表示的更新,有没有encoder
第三种MoCo,构建动量编码的方式,右边使用了动量编码器,不需要反向的梯度更新,只需要通过左边编码器的参数θq,和动量编码器参数θk,进行一个组合,动量更新θk,θk给定初始值,并不断通过θq来更新更新,因此不需要梯度更新不占显存
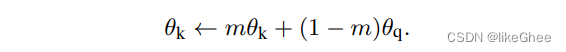
新的队列进去了,老的字典会被淘汰
正样本构造:来自q,k+,数据增强,尽可能的拉近正样本之间的距离
核心损失函数
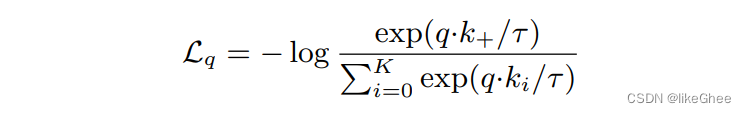
简单的来过一遍伪代码,短短几行(何凯明的文章就是好读)
# f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
f_q是左边的encoder
f_k是动量编码器
一开始初始化把左边的f_q参数赋值给右边f_k
同时输入的图像会经过两边的数据增强
x_q和x_k进行aug数据增强
x_q和x_k输入各自的编码器得到q和k编码后的向量
细节设置q_k参数不用进行更新
用bmm,q和k+相乘构建正样本之间距离
q和之前所有的memory bank的字典当成负样本相乘得到负样本距离
两个计算得的距离合并起来
赋予标签,只用N个正样本标签即可
计算loss交叉熵,更新梯度,保证和正样本之间的距离
只梯度更新左边的encoder
而右边的f_k只用一种动量更新的方式只用f_q的参数更新即可
当前batchsize的k放入队列,同时把最开始的队头数据淘汰掉,保持队列的长度固定
实验结果
对比其他方式的自监督方式,很明显Moco性能最好
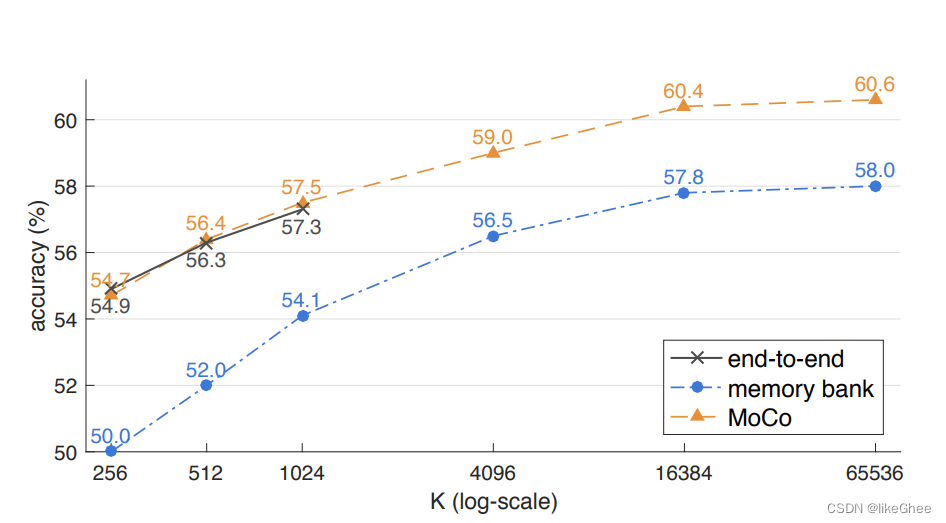
动量编码器的更新参数m,在0.999时达到最优,也就是说动量编码器和特征编码器基本保持一致,只有0.001的小的更新
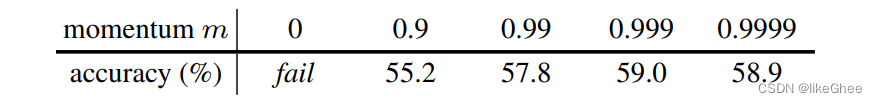
Nips-2020 Jean-Bastien Grill 仅正样本对比学习
Nips-2020 《Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning》
在不使用负样本的对的情况下,仅通过构建正样本对进行对比学习
https://arxiv.org/abs/2006.07733
https://arxiv.org/pdf/2006.07733.pdf
标题:开启你的自己的天赋
动机:之前的对比学习依赖于构建正负样本对的学习,或者依赖于图像数据增强,未考虑利用正样本对的学习方式
思想:自己拳头打自己的脸
文章的BYOL框架图
输入一张图像,对图像进行表征增强变成两张图像,online相当于上一篇论文的特征编码器,会梯度更新,下面的target可以理解为动量编码器,不需要进行更新,只是参数进行一个凸组合的更新
多了一个projection层特征投影
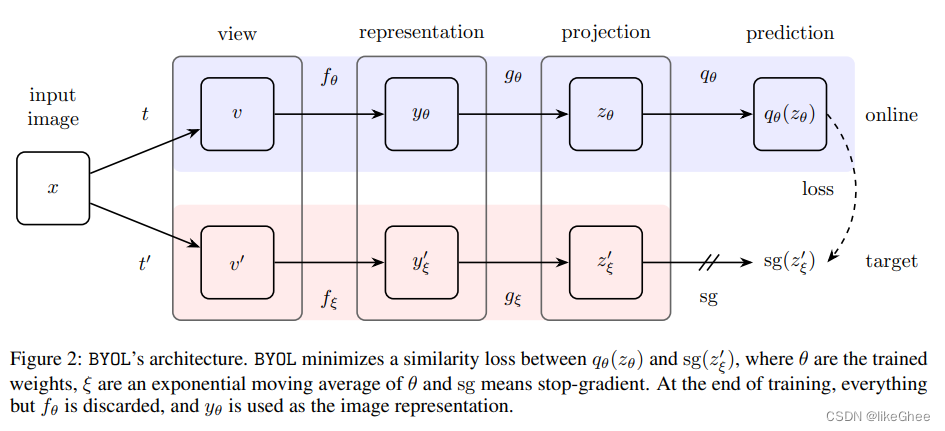
损失函数,进行了一个归一化后的欧氏距离,只是自己和自己的一个正样本的简单的损失函数
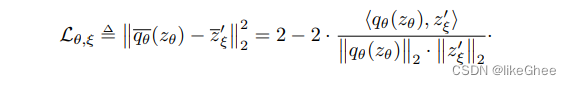
总损失函数,t和t’输入,t’和t输入,就是交换一个t’和t的位置

伪代码,简单的看一下,一共只有12行
B一个采样的batch,从B中随机的选取样本xi
T和T’表示不同的数据增强方式transformations
经过两层的线性变换(encoder和projector)分别是得到z1和z’1
计算损失函数,梯度下降,更新参数
后面就是正常的梯度更新

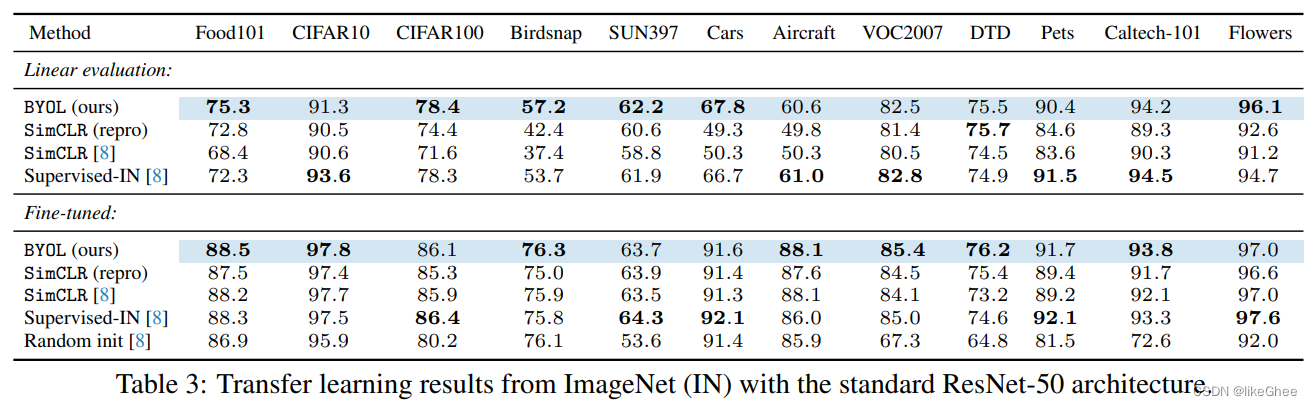
实验结果:
评价:可以在自己的领域进行尝试,比Moco模型高出3个点,参数量也不大
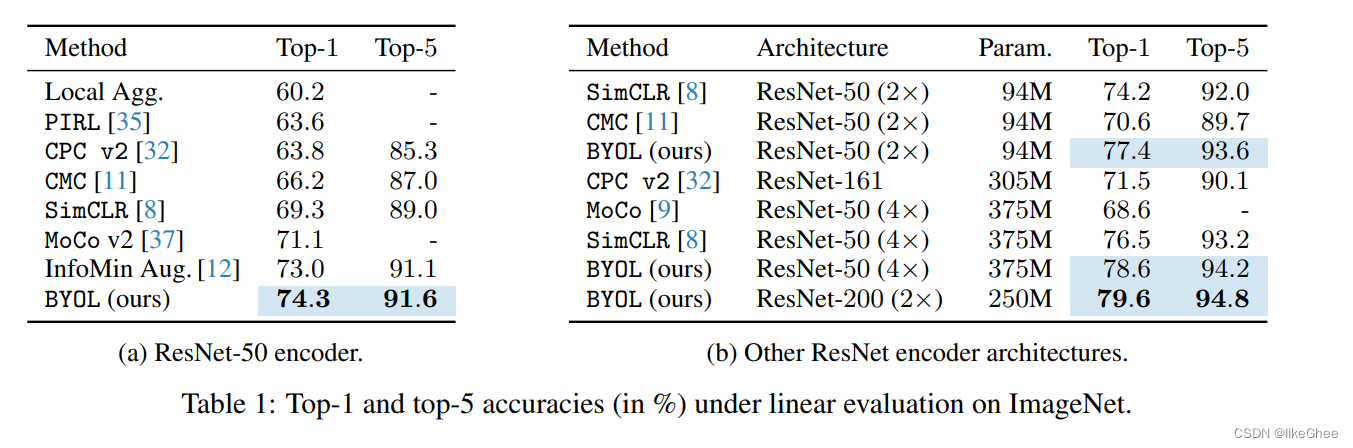
跨域数据实验,能胜过监督学习在ImageNet task
CVPR 2022 何凯明 MAE
CVPR-2022 《Masked Autoencoder Are Scalable Vision Learners》
辅助任务的方式,设计了一种随机遮盖输入图片的子块,再重建子块像素的自监督任务
https://arxiv.org/abs/2111.06377
之前写过一篇博客记录了,可以回头看看
https://blog.csdn.net/qq_19841133/article/details/126127849
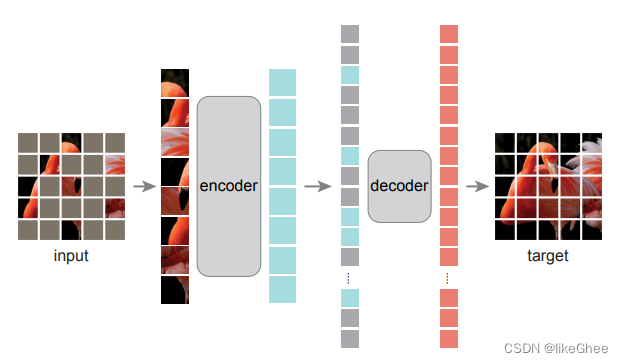
基于pretext task,辅助任务方式,思想来源于bert结构的启发
什么使得掩码编码在CV和NLP中不一样呢?
凯明大佬给出了3个不同
结构不同,CNN没有有效考虑位置信息,更多考虑的是局部的位置信息,(VIT可编码长距离的编码结构,借鉴NLP思想运用到CV)
信息密度的不同,自然语言语义信息丰富和信息密度更大,视觉相反,所以在CV中掩码更多的部分
自编码器和解码器,自然语言语义信息丰富,一个词不同可能有重大意思转变,但是在图像中生成图像差不多就行,少有一些的像素差异不影响整张图像的识别,因此图像只是构建出一个底层的语义信息
基本思想:
随机mask多个patch,在对patch进行重建
对称编码器解码器设计
轻量级解码,仅仅通过可见patch编码和解码
写在后面
回顾了一下CV领域的一些自监督学习文章,感觉重点还是在数据增强这一块,目的是如何更好的表示图像特征














 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









