







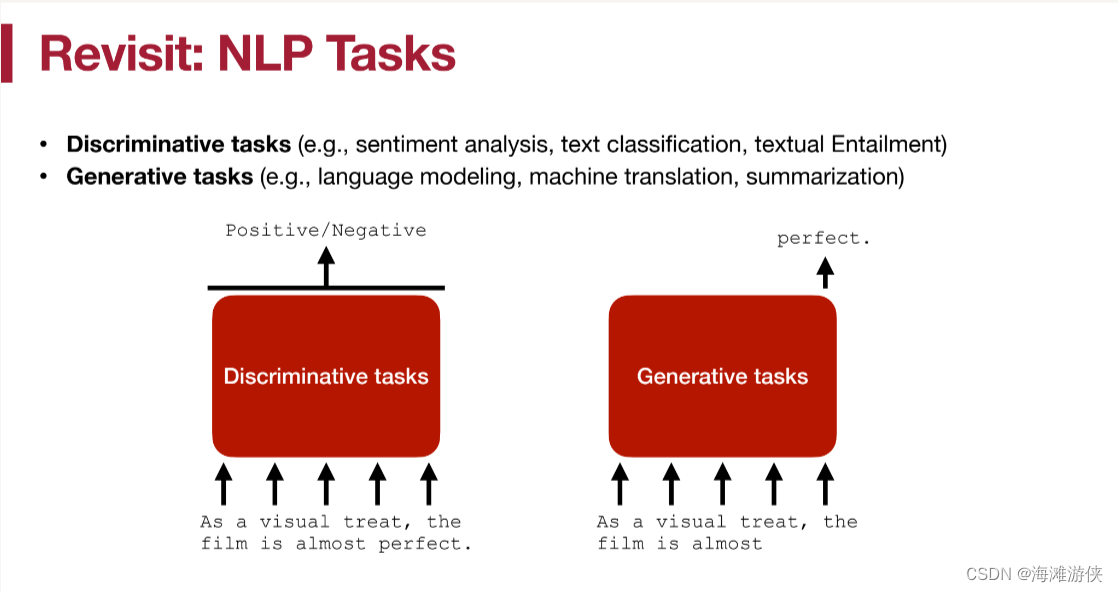
首先,回顾了一下以往的NLP任务,可以分为Discriminative tasks和 Generative tasks。
而以往,会尝试使用RNN,CNN
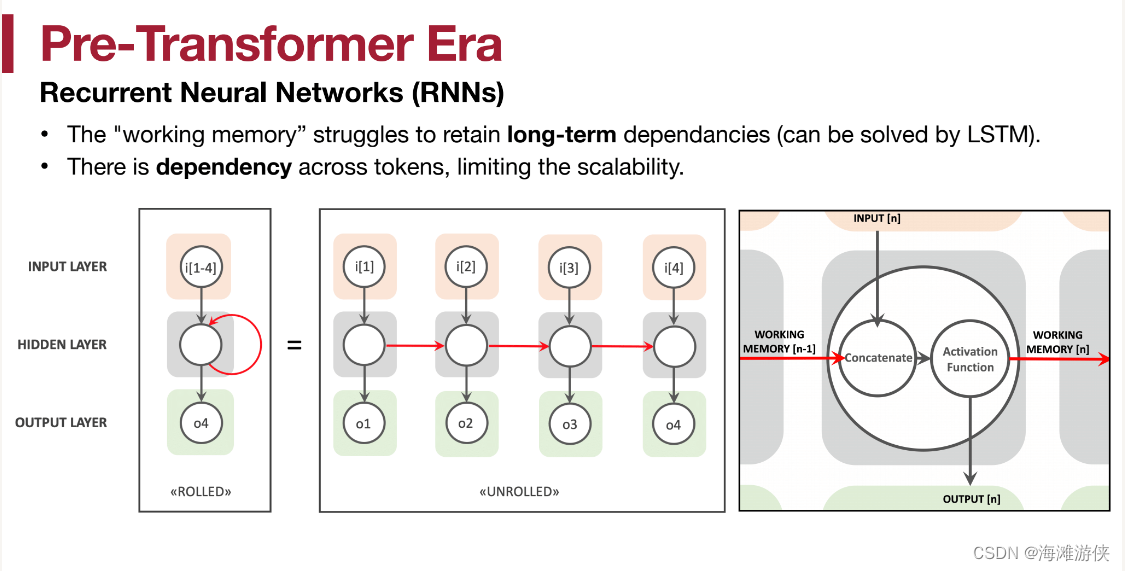
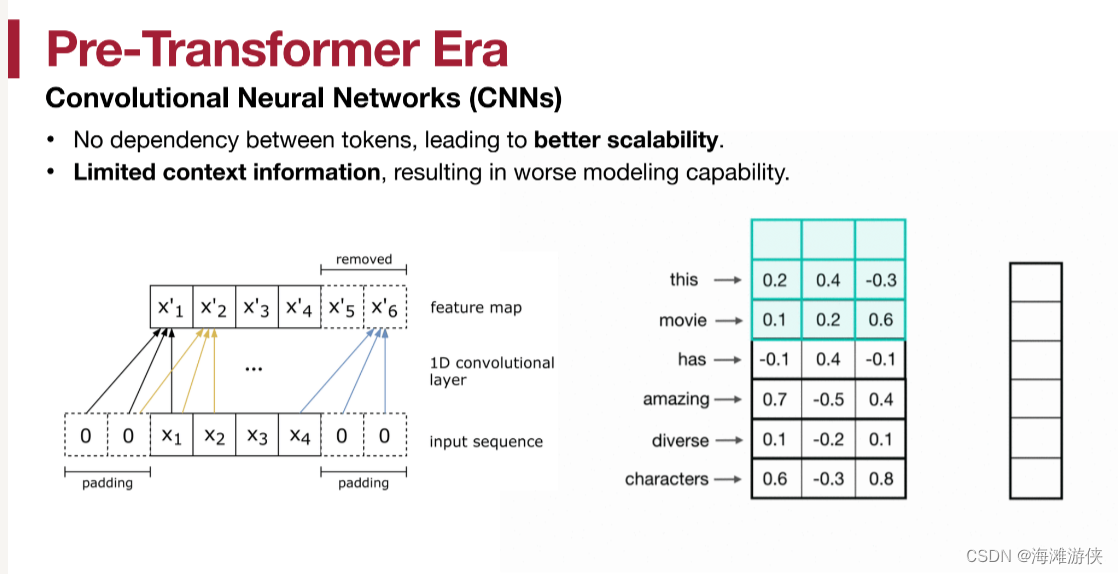
不管是RNN,CNN,都遇到类似的问题,那就是无法保证足够大的感受域。比如一个人说的话题可能和他几分钟前说的话有因果关系。
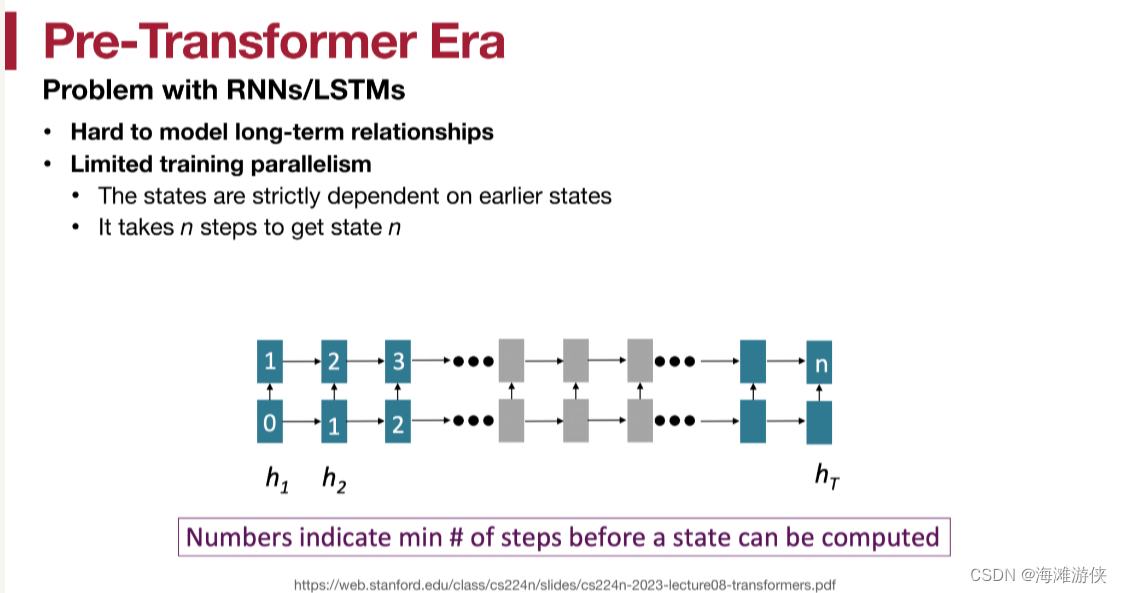
上面这张图总结了RNN/LSTM的缺点。然后,Transformer闪亮登场。
首先,我们需要把单词句子mapping成token。值得注意的是,token和单词的对应关系其实很紧密。一个token对应1--2个单词。

然后基于one-hot encoding来表达单词。

 对应的问题也显而易见,那就是词汇量很大时,one hot所占用的词汇大小非常大,而如果用float的形式,将大大减小数据的大小。(这个也给我了一些启示,那就是视觉单词,voc同样也是更好的选择)
对应的问题也显而易见,那就是词汇量很大时,one hot所占用的词汇大小非常大,而如果用float的形式,将大大减小数据的大小。(这个也给我了一些启示,那就是视觉单词,voc同样也是更好的选择)
如何理解 P, Q, V

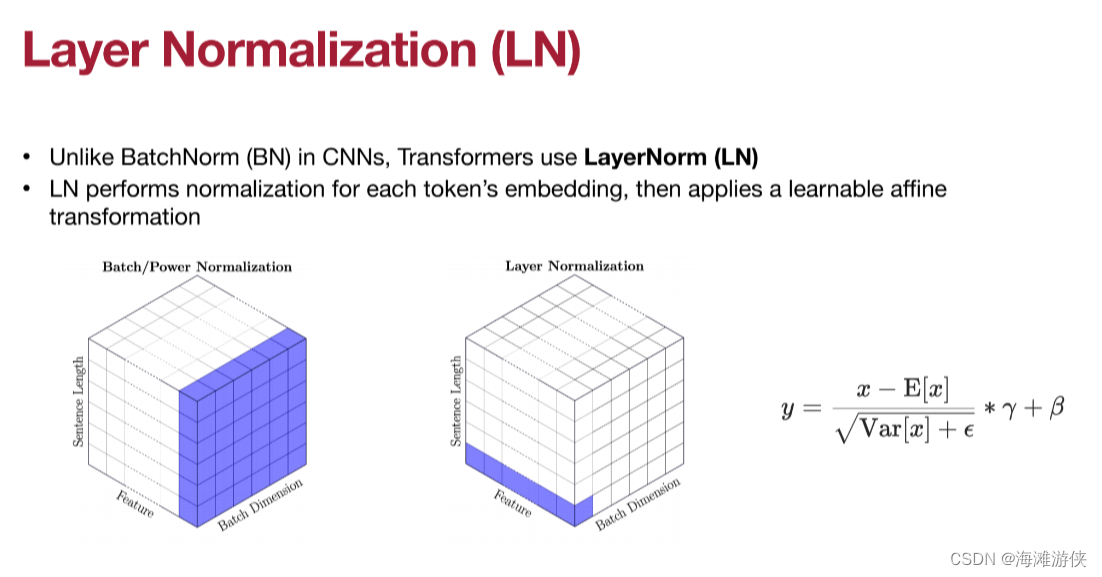
在CNN中,我们会试图把每一个batch进行norm处理,而在transformer中,我们希望把Feature进行norm处理,也就是对应的word。
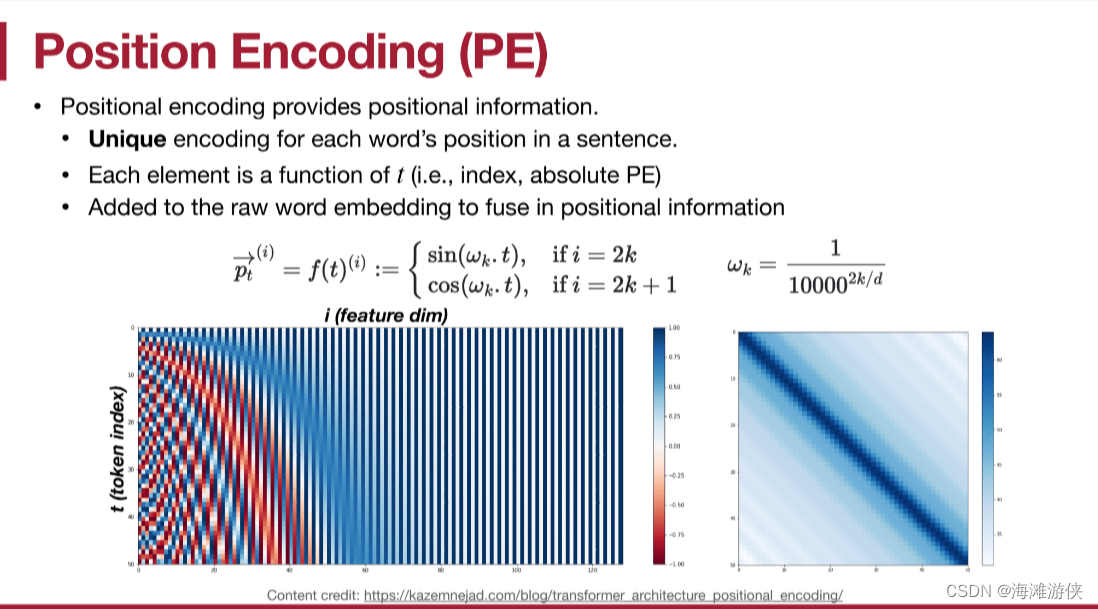
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog
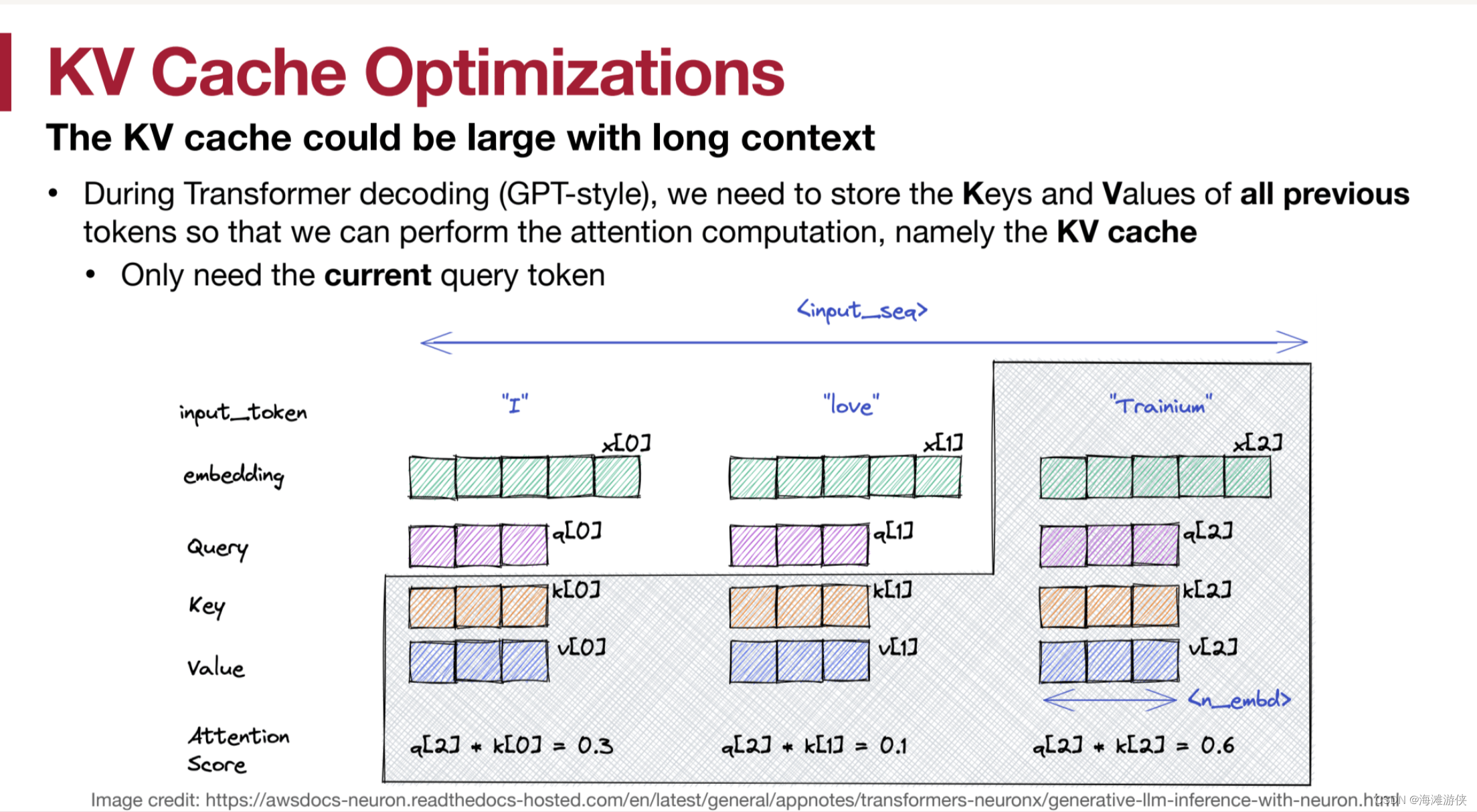















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









