







 文章讲述了在下载并运行Transformer模型时遇到的问题,涉及矩阵数据结构、优化参数如block_size、weightreordering策略,以及代码中不同加速技术的实现,如多线程和SIMD编程。
文章讲述了在下载并运行Transformer模型时遇到的问题,涉及矩阵数据结构、优化参数如block_size、weightreordering策略,以及代码中不同加速技术的实现,如多线程和SIMD编程。
初次运行
在按照文档下载好模型和代码后,在transformer文件夹执行
./evaluate.sh结果如下
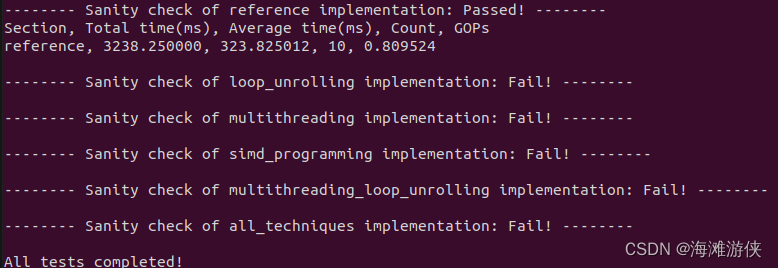
通过
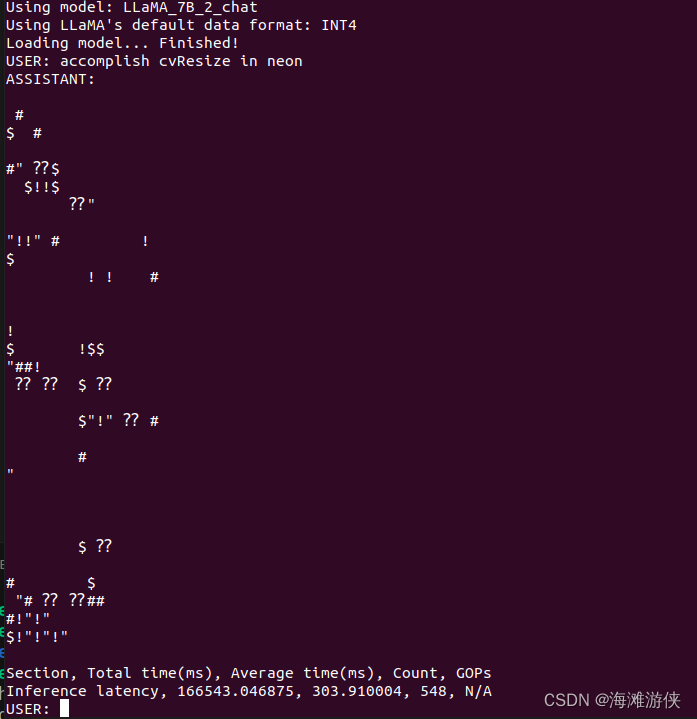
./chat查看了一下效果,着明显是个不工作的gpt
Code Review
搜索了一下代码中的TODO,第一感觉是一脸蒙B。告诉自己别慌,
结合文档,大概明白了,这是为了进行矩阵的运算,然后通过各种加速手段,加速运算的进行。
影响我阅读代码的原因之一:基本的数据结构不熟悉。包括matmul_params
struct matmul_params {
struct matrix A, B, C, bias;
struct optimization_params opt_params;
float alpha, beta;
// for int4
float *scales, *offset, *zero_point;
int block_size;
// for int8 activation
float *A_scales;
int8_t A_zero_point;
};矩阵的数据结构包含了矩阵的尺寸信息,以及float32,int8, uint8 uint4对应的指针。
此外,还有blk_size和num_threads两个参数。
struct matrix {
int row;
int column;
float *data_ptr;
int32_t *int32_data_ptr;
int8_t *int8_data_ptr;
uint8_t *uint8_data_ptr;
uint8_t *int4_data_ptr;
struct quantization_params qparams;
int length() { return row * column; }
};
struct optimization_params
{
int blk_size;
int num_thread = 8;
};在evaluate.sh中,我们可以通过不同的keys实现不同的测试类型的映射。
# List of implementation
# 0: reference
# 1: loop_unrolling
# 2: multithreading
# 3: simd_programming
# 4: multithreading_loop_unrolling
# 5: all_techniques
keys=("reference" "loop_unrolling" "multithreading" "simd_programming" "multithreading_loop_unrolling" "all_techniques")
values=("0" "1" "2" "3" "4" "5")可以看到,navie的操作,对应函数mat_mul_reference。
另外,注意在文档里提到了weight reordering的策略,具体是为了加速 weight reordering。

这里直接使用作者的描述, 针对4bit的量化后的权重,采用交叉的排布方式。这也可以解释一部分源码里我没有看明白的地方
顺便看了一眼这个项目,star数量吓了我一跳。
GitHub - ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++
问题:block size的作用是什么?它和weight对应的32是一致的吗?
kernels/starter_code/reference.cc中,这是算法优化前的基本实现的参考,但是,它所实现的内容并不简单,并不是一个简单的矩阵的乘法。
首先,我们实现fp32到int8的乘法。函数的内容比较抽象,
quantize_fp32_to_int8(A->data_ptr, A->int8_data_ptr, params->A_scales, A->row * A->column, block_size);
所包括的函数
float32x4_t vld1q_f32(float32_t const * ptr):从地址ptr依次向后加载四个元素放入返回的寄存器中。
float32x4_t vld1q_f32(float32_t const * ptr):从地址ptr依次向后加载四个元素放入返回的寄存器中。其他的内容,不管是ARM的,还是X86的,目前我读起来都很份费劲。但是,这个函数的基本意义我也算理解了,那就是将float32的数据转换为int8类型的,并且记录float32转换为int8所失去的尺度信息。
TODO: 阅读forward_ref函数
在阅读test_linear.cc的函数后,发现,forward_ref的输入维度是 [1,1,4096], 经过在forward_ref中,和[1, 32000, 2048]相乘, 输出是 [1,1,32000]。 此外,发现BLK_SIZE 被hard code成了16。
这里两倍的关系意味着,必然存在数据的压缩。综上所述,在test_linear.cc中实现的,就是三维的两个矩阵相乘。因此,我认为可以否定BLK SIZE有其他的特殊含义。
此外,block_size = QK #32.
一个block对应的是一个scale
上周ski holiday的过程中,总算把这个代码的框架和逻辑正明白了。为了帮助自己和大家理解,首先用画图的方式来表达一下各种加速方式的策略。之前的思路有点混乱,下次我们重新再说

















 102
102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









