







在完成了本次作业后,可以理解,这次作业是把矩阵乘法的优化加速方式和大模型推理时常用的操作结合,比如引入block和对应的scale的概念,以及4bit存储weight,8 bit存储activation的方式。
总之,这些让我们应用起矩阵乘法的加法时更加困难。
首先,通过图来表达,常规的矩阵乘法和本次作业涉及的乘法的加速策略。
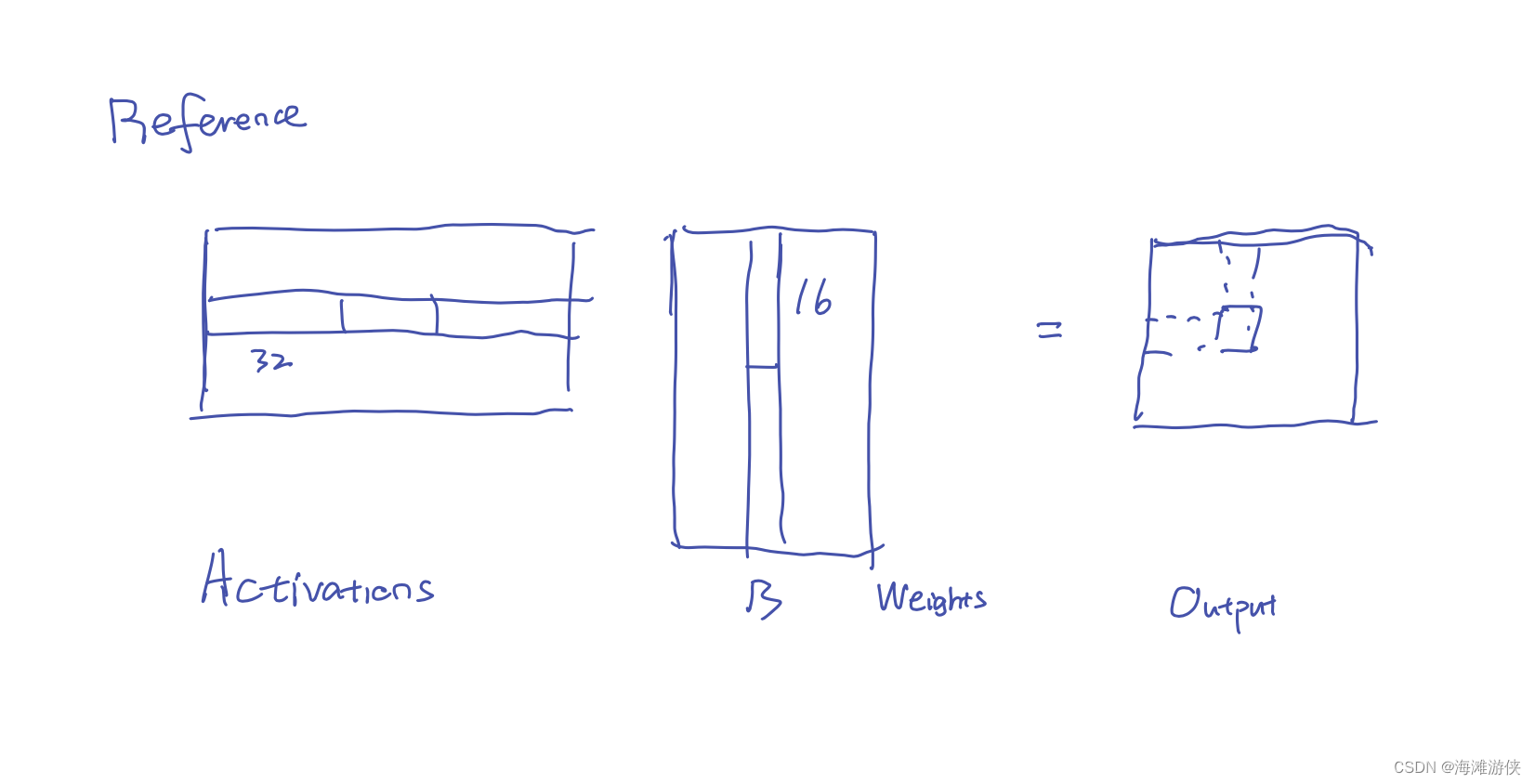
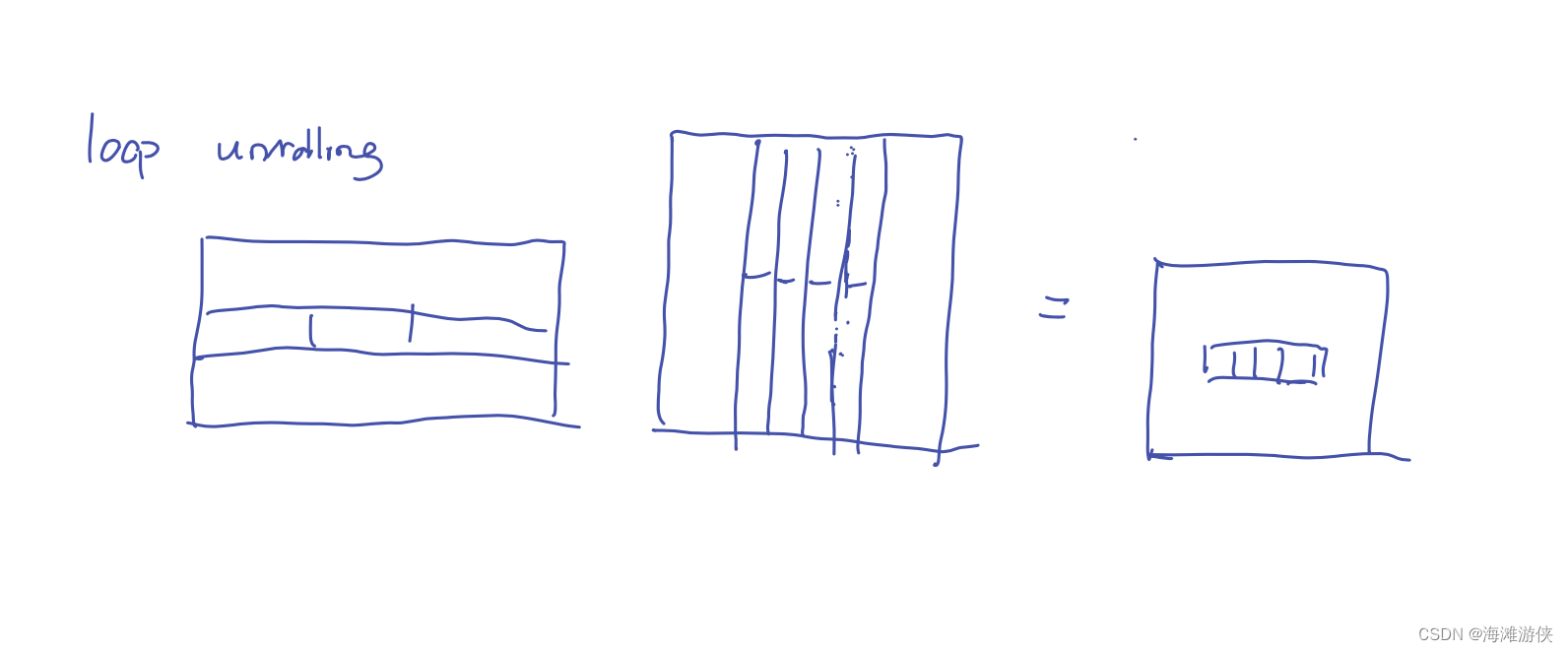
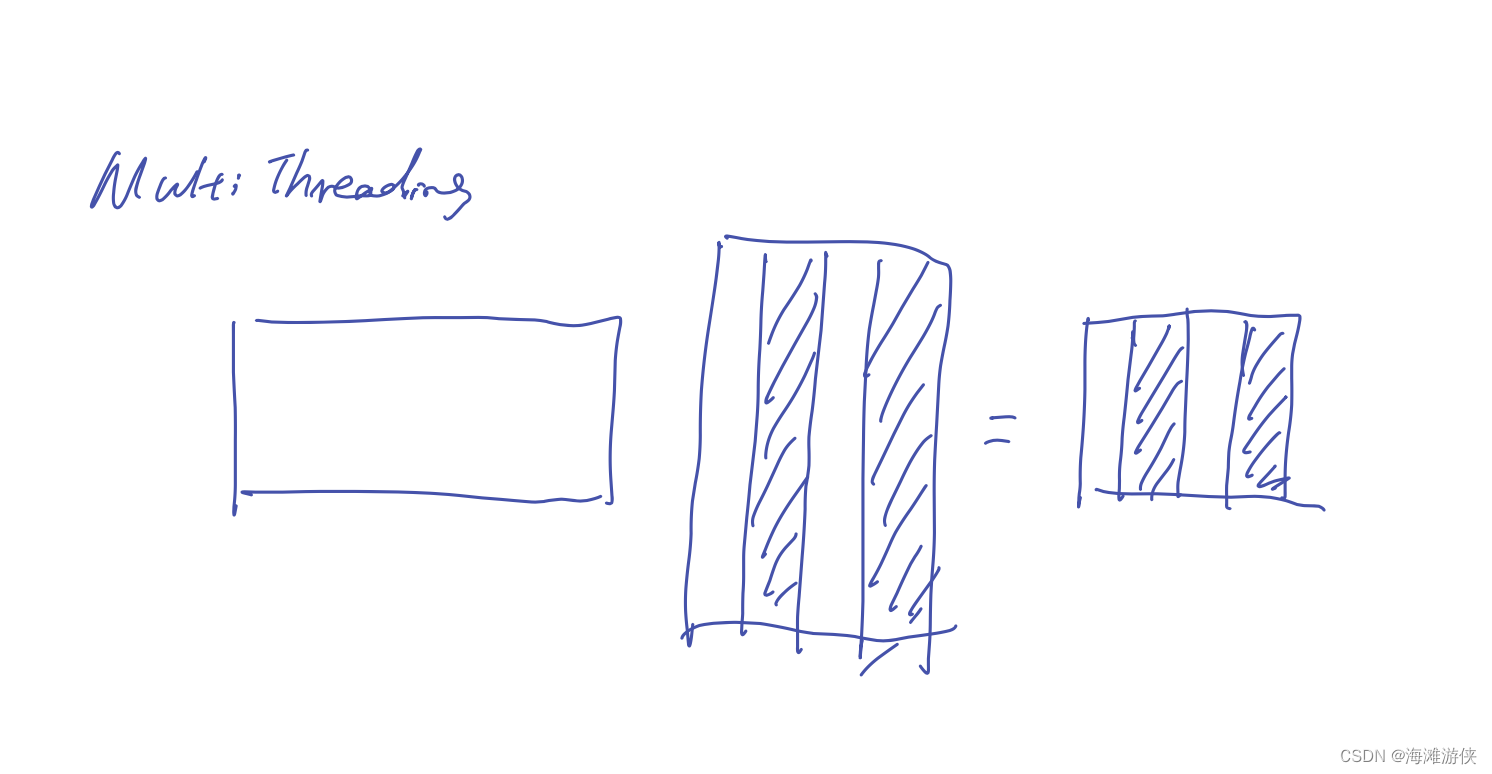
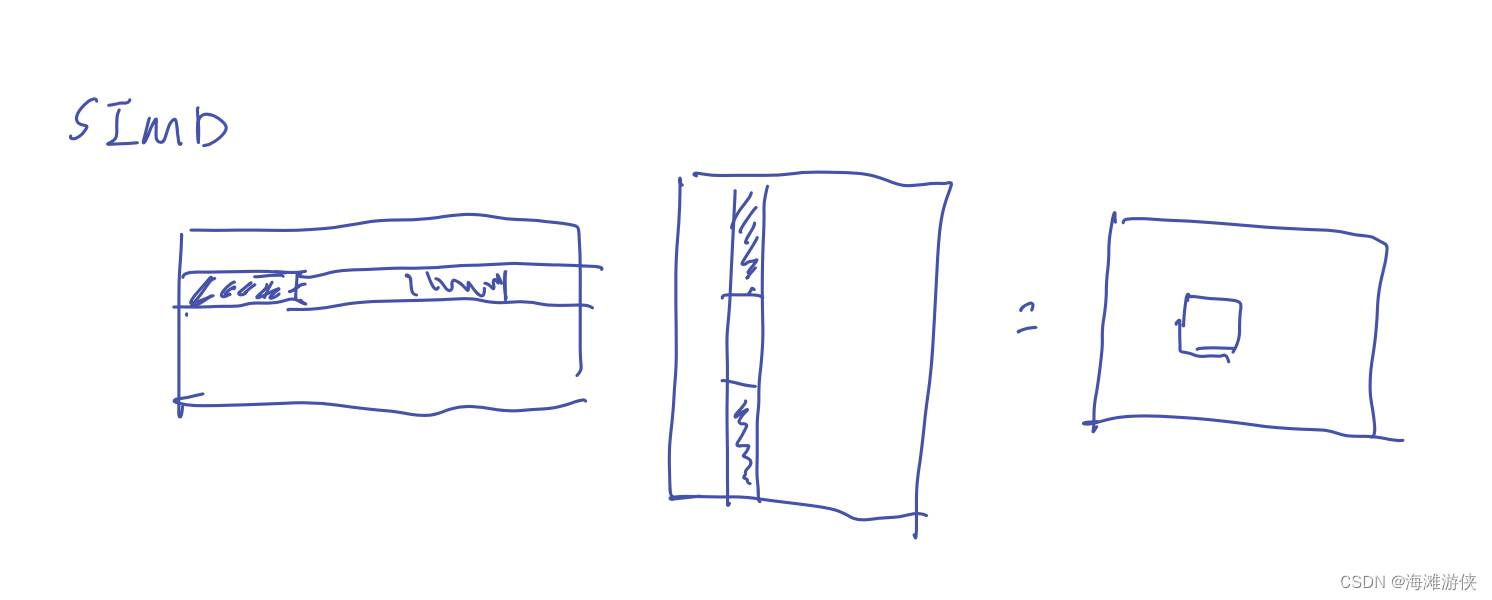
从下图可以看到,loop unrolling并没有看到有效的效果提升,然后,也没有cuda对应的加速策略。
而最后,相比于原始的方法,速度提高了10倍,还是一个相对比较满意的量级。
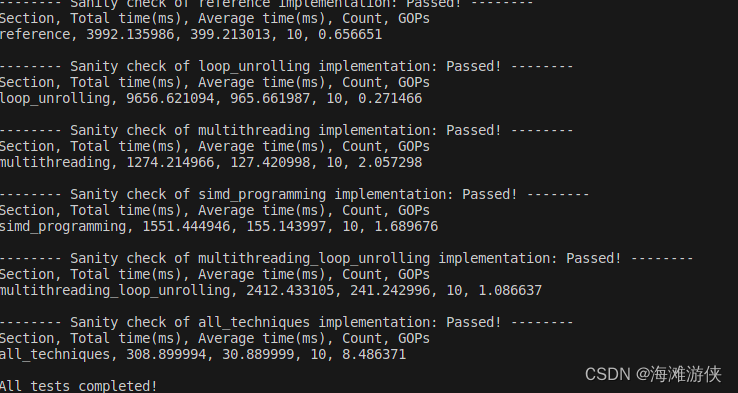
但是,在实际使用./chat时,还是感觉其慢无比,这需要我进一步改进。















 52
52











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









