






 Google新开源的Magika是一款采用深度学习的文件类型识别工具,能快速准确识别文件,弥补传统方法的不足。它通过理解文件内容而非仅依赖扩展名或MagicNumber,提高了安全性并广泛应用于Google内部系统,提升了50%的文件识别准确率。
Google新开源的Magika是一款采用深度学习的文件类型识别工具,能快速准确识别文件,弥补传统方法的不足。它通过理解文件内容而非仅依赖扩展名或MagicNumber,提高了安全性并广泛应用于Google内部系统,提升了50%的文件识别准确率。
01 引言
Magika Github地址:https://github.com/google/magika
近日,google开源了一款文件类型识别工具,霸榜了Github头条,而且star一直在上升(目前已经有4.1k了),它就是 Magika。
也许很多人会说,这不是一款很普通的工具吗?有啥特别的。其实我们都小看它了,它采用了一种 定制高度优化的深度学习模型,能在几毫秒内精确识别文件类型,并弥补了传统文件识别方法的局限,提供了更准确和高效的解决方案,通过标准的命令行pip install magika命令就能安装。
也许这么说,还不能提现的它的特别之处,本文演示操作下。
02 演示
首先新建一个test.txt文件,然后在里面随便写入几行文本,接着修改test.txt文件的后缀名为png格式:
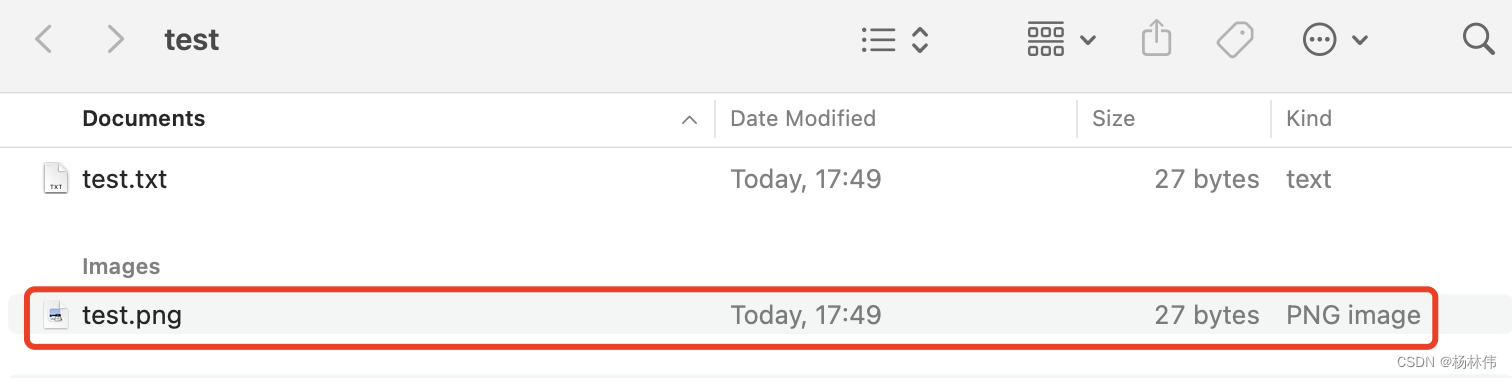
从上图可以看到连mac操作系统都把test.png识别为图片类型了,实际为txt类型,我们也可以在线去识别:
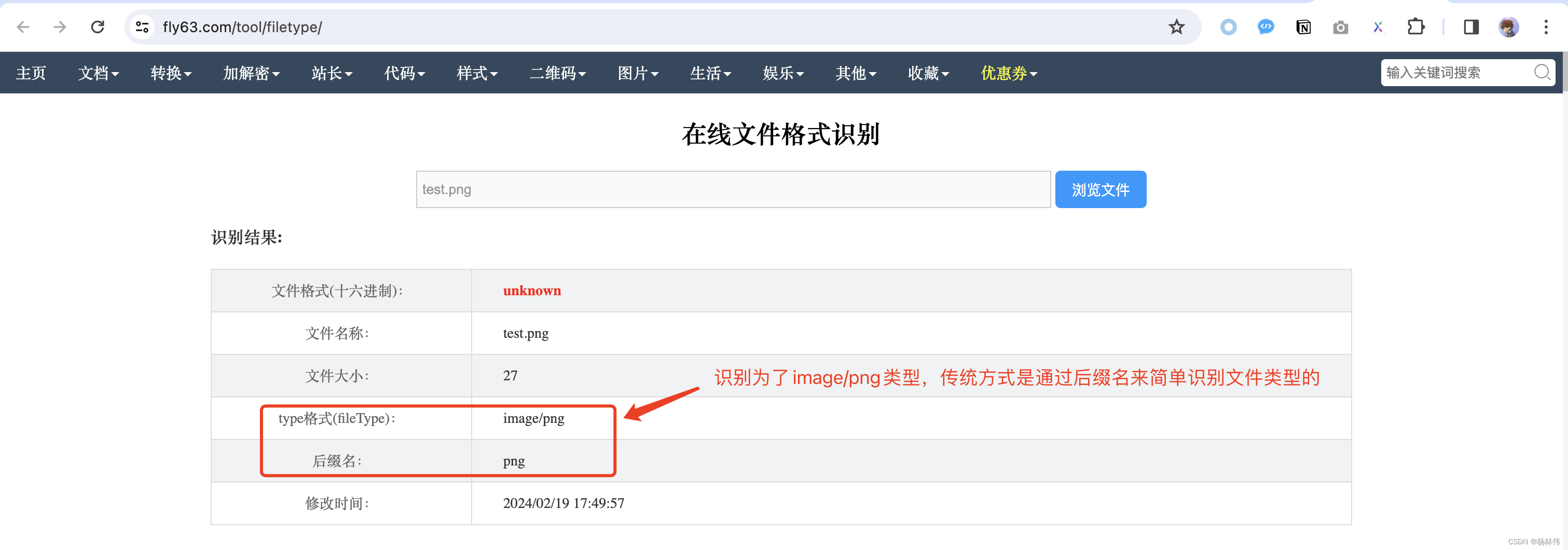
可以知道,通过传统的方式,无法真实地识别到文件的实际类型,那么在线使用Magika,会不会有不一样的结果呢?在线地址:https://google.github.io/magika,例如:
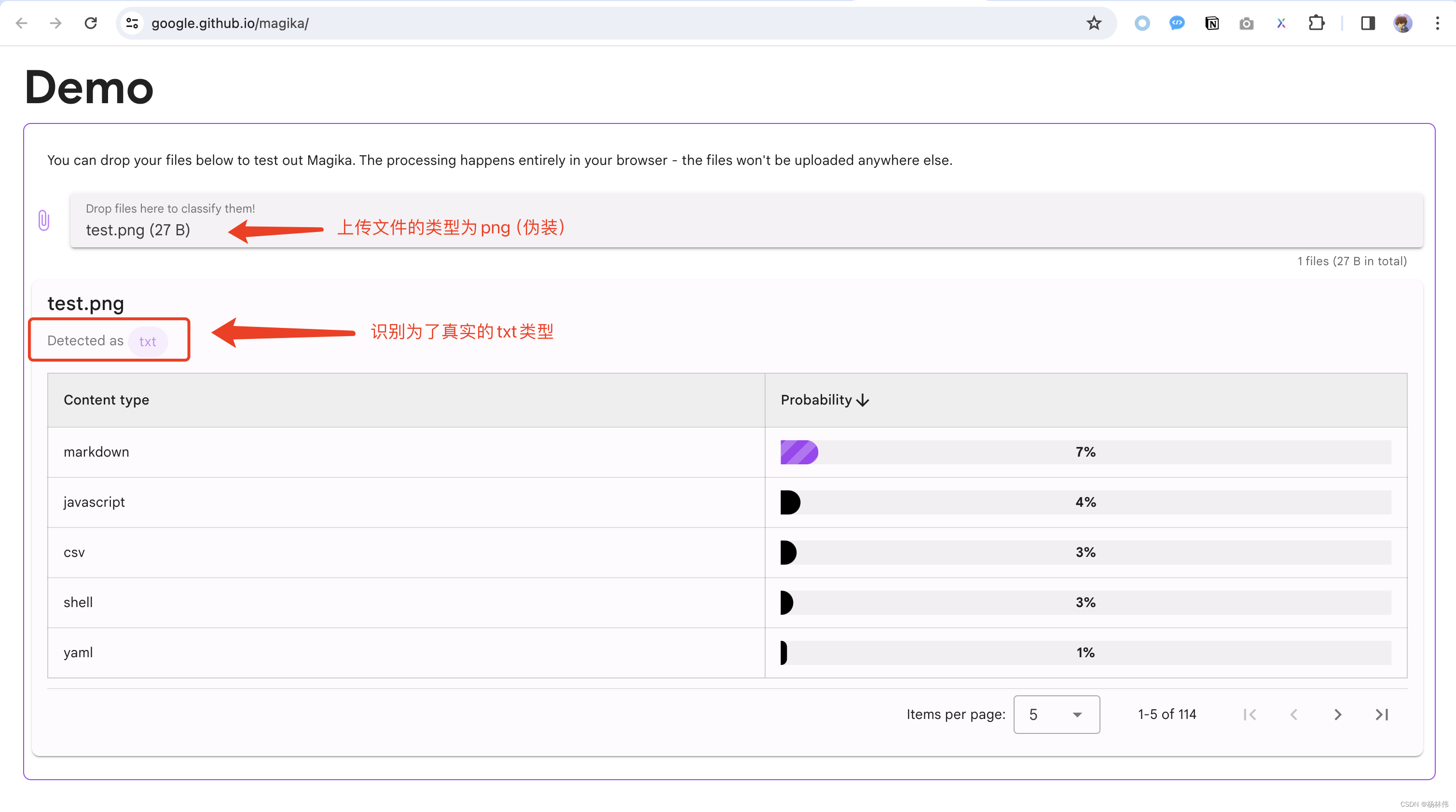
可以看到Magika把文件识别为真实的类型,为txt而不是png。
以前的工具主要是通过查看文件的扩展名,或者文件的"magic number"(这是文件开头的一段特定数字,用来标识文件类型)来确定文件的类型,这种方法有时候可能会出错。比如,如果文件被恶意修改,或者"magic number"被错误的定义,那么文件类型识别就可能发生错误。
而Magika采用的是 基于深度学习的方法,它会去理解文件的整体内容,而不仅仅是文件的开始部分,这就意味着Magika能够更准确地识别复杂或者模糊的文件类型,减轻了人工介入的需要,提高了识别的准确性和效率。
03 小结
可以知道Magika相对于其他类似的软件,有如下优势:
- 高度准确:Magika采用深度学习的方法进行文件类型识别,这意味着无论文件类型有多复杂或模糊,Magika都能准确地识别出来。
- 节省时间:Magika可以自动并快速地识别大量文件,这大大节省了人工分类和识别的时间。
- 学习能力强:Magika能够自动学习和适应新出现的文件类型,这意味着即使面对未知的新文件类型,Magika也能自如应对。
- 易于集成:Magika提供了友好的API接口,可以轻易地集成到其他系统或应用中,提供文件识别服务。
- 安全性高:Magika只需要读取文件的内容进行识别,不会修改文件,也不会存储文件,保证了文件的安全性。
- …
下面是一张官网贴出的Magika对比其它软件的性能比分图:
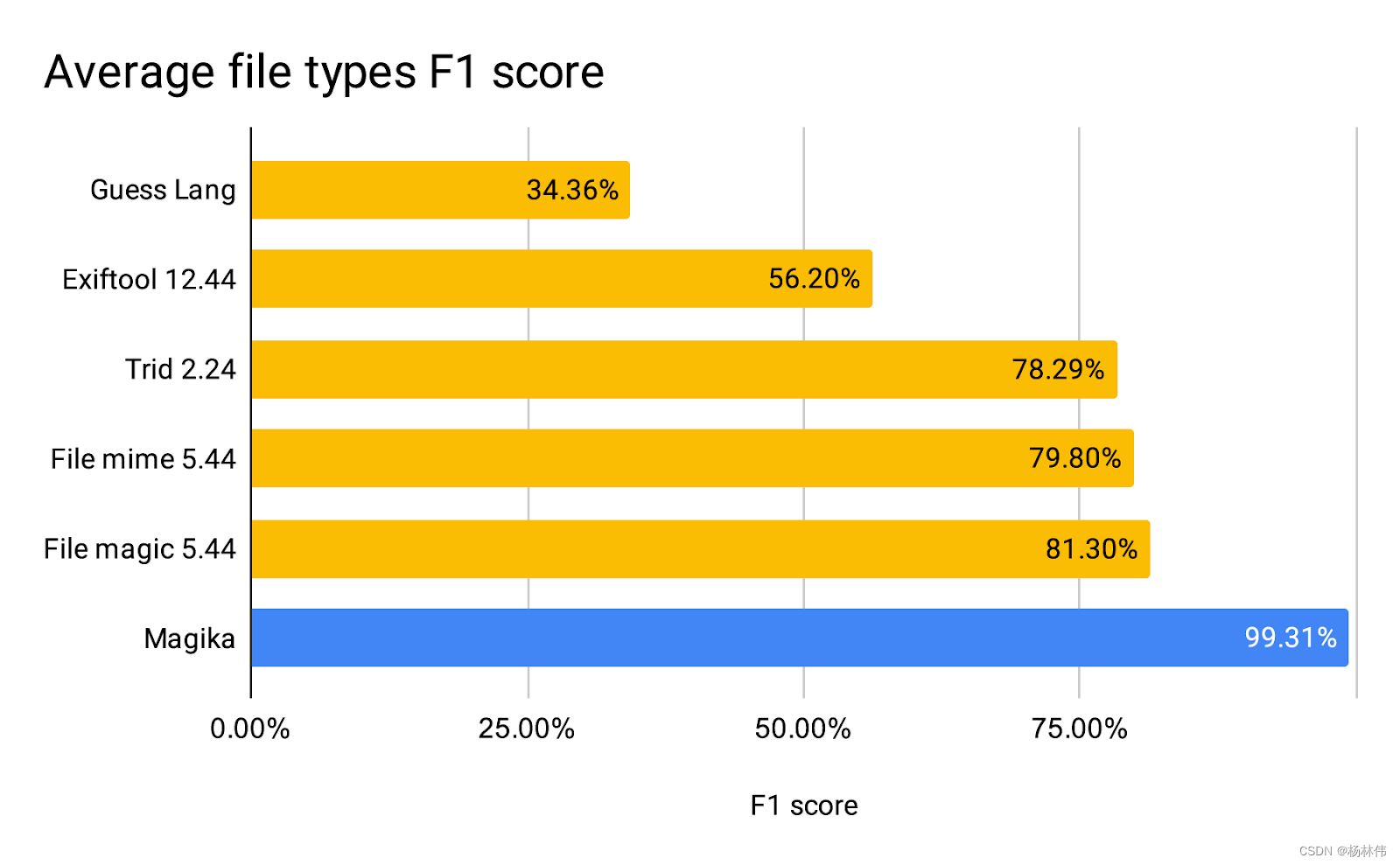
在Google内部,Magika目前已被大规模地用来提高Google用户的安全性,通过将Gmail、Drive和Safe Browsing文件路由到正确的安全和内容策略扫描器,Magika比以前依赖于手工规则的系统提高了50%的文件类型识别的准确率。
如果想更深入的了解,有兴趣的童鞋可以参考Google发布的博客:https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html

















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









