










完整代码:
import re
import urllib.request
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
import time
from lxml import etree
t ,urls ,names = [],[],[]
INDEX_URL = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2022/" #初始url
res = {'代码':[],'区域':[]}
res = pd.DataFrame(res)
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
#获取省份页面
province_response = urllib.request.urlopen(INDEX_URL + "index.html").read().decode("utf-8")
# 获取省份列表
province_data = re.findall(r"<td><a href=\"(.*?)\">(.*?)<br /></a></td>", province_response)
for url, name1 in province_data:
# 获取省份名称 与 代码
code1 = url.replace(".html", "") + "0" * 10
if url not in urls:
urls.append(url)
names.append(name1)
res = res.append({'代码':code1,'区域':name1},ignore_index = True)
def get_province_code(i):
#爬取每个省份的城市
if urls ==[]:
if i >0:
print('执行开始')
global res
get_city_code(urls[i],names[i])
return res
def get_city_code(province_url,names):
# 获取城市初始页
print(INDEX_URL + province_url)
print('爬取省份-----------------{}'.format(names))
global res
try:
city_response = urllib.request.urlopen(INDEX_URL + province_url).read().decode("utf-8")
except Exception as a:
city_response = urllib.request.urlopen(INDEX_URL + province_url).read().decode("utf-8")
print(a)
# 获取地区名称 + 地区代码
city_data = etree.HTML(city_response)
for i in city_data.xpath('//tr[@class="citytr"]'):
code2 = i.xpath('td[1]//text()')[0]
name2 = i.xpath('td[2]//text()')[0]
res = res.append({'代码':code2,'区域':name2},ignore_index = True)
try:
url = i.xpath('td[1]/a/@href')[0]
get_area_code(url)
except:
print('异常城市:',name2)
def get_area_code(city_url):
# 获取区县
# print('请求城市',INDEX_URL + city_url)
global res
try:
area_response = urllib.request.urlopen(INDEX_URL + city_url).read().decode("utf-8")
# print('请求成功')
except Exception as a:
area_response = urllib.request.urlopen(INDEX_URL + city_url).read().decode("utf-8") #错误后重新调用方法
# 获取街道名称 + 街道代码
area_data = etree.HTML(area_response)
if len(area_data)==0:
print("---------------------区县异常------------------------------",name2,city_url)
for i in area_data.xpath('//tr[@class="countytr"]'):
code3 = i.xpath('td[1]//text()')[0]
name3 = i.xpath('td[2]//text()')[0]
res = res.append({'代码':code3,'区域':name3},ignore_index = True)
try:
url = i.xpath('td[1]/a/@href')[0]
get_street_code(url)
except:
continue
def get_street_code(area_url):
global res
# 获取街道初始页
try:
street_response = urllib.request.urlopen(INDEX_URL + area_url[3:5] + "/" + area_url).read().decode("utf-8")
except Exception as a:
street_response = urllib.request.urlopen(INDEX_URL + area_url[3:5] + "/" + area_url).read().decode("utf-8")
print(a)
# print(street_data)
street_data = etree.HTML(street_response)
if len(street_data)==0:
print("---------------------------------------------------",name3,area_url)
# 获取街道名称 + 街道代码
for i in street_data.xpath('//tr[@class="towntr"]'):
code4 = i.xpath('td[1]//text()')[0]
name4 = i.xpath('td[2]//text()')[0]
res = res.append({'代码':code4,'区域':name4},ignore_index = True)
#后面的代码未:获取乡镇级别的行政代码,乡镇数量较多,爬取时间较长
# url = i.xpath('td[1]/a/@href')[0]
# get_community_code(url)
# def get_community_code(street_url):
# """
# 获取社区名称+代码
# :return:
# """
# # 获取社区初始页
# try:
# community_response = urllib.request.urlopen(INDEX_URL + street_url[3:5] + "/" + street_url[5:7] + "/" + street_url)\
# .read().decode("utf-8")
# except:
# community_response = urllib.request.urlopen(INDEX_URL + street_url[3:5] + "/" + street_url[5:7] + "/" + street_url)\.read().decode("utf-8")
# community_data = etree.HTML(community_response)
# for i in community_data.xpath('//tr[@class="villagetr"]'):
# code5 = i.xpath('td[1]//text()')[0]
# name5 = i.xpath('td[3]//text()')[0]
# res = res.append({'代码':code5,'区域':name5},ignore_index = True)
from concurrent.futures import ThreadPoolExecutor, as_completed
from concurrent import futures
import concurrent
thread_pool = ThreadPoolExecutor(max_workers=2) #线程不能太多,会被反爬
for i in range(0,31): # 循环向线程池中提交任务
futures = thread_pool.submit(get_province_code, i)
t.append(futures)
res1 = []
for future in as_completed(t): # 每完成一个线程响应一个结果,直到work_list中线程全部结束
res1.append(future.result())
响应结果(31个省份):

数据:
df = res1[-1]
df = df.sort_values(by='代码')
df = df[~(df['代码'].str.contains(r'\s+',regex=True))]
df一个4万多条数据
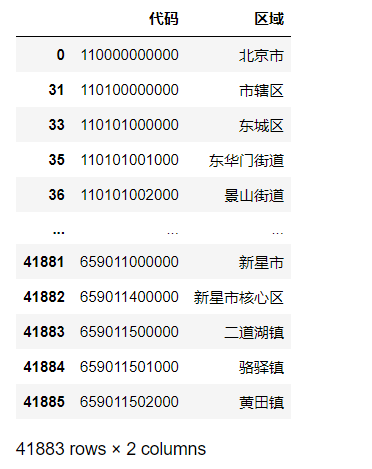
保存为excel文件:
df.to_excel(paht,index=False) #paht为保存地址excel查看

完整代码:https://download.csdn.net/download/qq_20163065/87433457
(本文仅供学习)
















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











