






在现代企业中,质量管理已成为提升竞争力和确保可持续发展的关键环节。作为质量管理的核心角色,质量经理的绩效评估至关重要。通过科学的绩效考核体系,企业能够有效评估质量经理在各项质量工作中的表现,及时发现潜在问题并进行优化。
本文将重点介绍如何通过KPI指标拆解和数据分析,提升质量经理绩效考核的精度与效能,从而推动企业质量管理水平的提升。
指标拆解
质量经理绩效考核表主要聚焦于质量管理工作中的核心要素,评估质量经理在不同维度上的绩效表现。该表格通过设定多个KPI(关键绩效指标),覆盖了产品质量、质量管理、费用控制、培训计划等方面,以确保质量经理在实际工作中能够有效推动质量标准的落实,提升企业整体质量管理水平。每个KPI指标都有明确的目标值与权重,考核周期为一个固定时间段。通过这些具体的评估标准,确保各项质量工作目标能够精准量化,且与企业的整体质量战略相一致。
质检工作及时完成率
质检工作的及时完成是确保产品质量控制的重要环节。质量经理需要确保在考核期内,所有质检任务都能按时完成。这不仅影响产品的合格率,还关系到生产周期的稳定性。若未按时完成质检工作,可能导致质量问题的延迟发现,从而影响后续生产和交付。
| KPI 指标名称 | 质检工作及时完成率 |
|---|---|
| 考核周期 | 每季度或年度 |
| 指标定义与计算方式 | 质检工作按时完成的比例=按时完成的质检任务数 ÷ 总质检任务数 |
| 指标解释与业务场景 | 反映质检人员完成工作的及时性,确保生产过程中的所有质检工作都能按时结束,从而保障生产计划的顺利执行。 |
| 评价标准 | 100%按时完成;未按时完成时需进行整改和改进 |
| 权重参考 | 15% |
| 数据来源 | 质检工作记录及生产计划表 |
原辅材料现场使用合格率
确保投入生产过程的原辅材料和外协产品的质量合格性,是质量管理的基础。质量经理需要确保原辅材料及外协产品达到100%的合格率。这一指标不仅影响生产效率,还直接关系到产品最终质量和生产成本。
| KPI 指标名称 | 原辅材料现场使用合格率 |
|---|---|
| 考核周期 | 每季度或年度 |
| 指标定义与计算方式 | 生产中使用的原辅材料合格率=合格的原辅材料数量 ÷ 总投入的原辅材料数量 |
| 指标解释与业务场景 | 确保生产中所有的原辅材料和外协产品都符合质量要求,避免因不合格材料导致的质量问题或生产中断。 |
| 评价标准 | 100%合格;若发现不合格原辅材料,需进行整改和更换 |
| 权重参考 | 10% |
| 数据来源 | 采购记录、材料检验报告 |
产品质量合格率
产品质量合格率是评估产品质量是否符合公司标准的重要指标。质量经理需要确保在考核期内,生产的所有产品均符合质量标准。如果质量合格率低,可能会影响客户满意度和市场竞争力。
| KPI 指标名称 | 产品质量合格率 |
|---|---|
| 考核周期 | 每季度或年度 |
| 指标定义与计算方式 | 产品质量合格率=合格产品数量 ÷ 总生产产品数量 |
| 指标解释与业务场景 | 产品质量合格率反映了生产中产品的整体质量水平。质量经理需确保各生产环节严格把关,避免不合格产品流入市场。 |
| 评价标准 | 根据产品类型设定的合格率标准,通常为90%以上 |
| 权重参考 | 10% |
| 数据来源 | 生产记录、产品检验报告 |
产品质量原因退货率
质量原因退货率反映了因质量问题而导致的退货情况。质量经理需控制退货率,以降低公司损失,并确保产品的质量水平持续提升。较高的退货率会影响客户满意度,增加售后成本。
| KPI 指标名称 | 产品质量原因退货率 |
|---|---|
| 考核周期 | 每季度或年度 |
| 指标定义与计算方式 | 质量原因退货率=因质量问题退货的产品数量 ÷ 总销售产品数量 |
| 指标解释与业务场景 | 退货率高表示产品质量存在问题,可能影响公司声誉。质量经理需通过提升生产与检验标准来控制这一指标。 |
| 评价标准 | 低于行业标准或预定目标;退货率高时需分析原因并改进生产流程。 |
| 权重参考 | 10% |
| 数据来源 | 售后服务记录、退货单据 |
质量会签率
质量会签率体现了不同部门和团队对质量管理的协作情况。质量经理需要确保在生产和质量控制过程中,各相关部门的参与度和配合度,以确保质量管理工作的顺利推进。
| KPI 指标名称 | 质量会签率 |
|---|---|
| 考核周期 | 每季度或年度 |
| 指标定义与计算方式 | 质量会签率=完成会签的质量管理文件数 ÷ 总会签文件数 |
| 指标解释与业务场景 | 质量会签反映了跨部门合作的有效性,确保各方对质量问题达成共识并共同推动改进。 |
| 评价标准 | 会签完成率100%;如果会签率低,需优化跨部门沟通和协作流程 |
| 权重参考 | 10% |
| 数据来源 | 会签记录、项目文件 |
教学案例
在质量管理中,绩效考核是一项至关重要的工作,通过精确的指标和分析,质量经理可以更好地了解各个方面的质量水平,从而制定优化策略。通过本案例展示的三种不同方法,展示了如何利用统计学、机器学习和深度学习技术,针对不同的质量管理KPI(如质检工作及时完成率、退货率、会签率等)进行预测、分析和优化。
第一个案例使用统计学方法,展示了如何通过分析历史KPI数据来评估质量经理的绩效。这种方法可以帮助质量经理了解在不同质量指标上的表现,并为后续的质量改进提供数据支持。第二个案例则应用了机器学习中的回归模型,预测质量原因退货率。这为质量经理提供了提前识别潜在问题的能力,帮助其更好地控制产品质量并优化生产流程。最后,第三个案例使用深度学习方法,通过神经网络模型预测质量会签率,以此优化跨部门合作的效率。通过深度学习模型的训练和预测,可以更准确地评估会签率,并发现提升质量管理协作的关键因素。
| 案例标题 | 主要技术 | 目标 | 适用场景 |
|---|---|---|---|
| 基于统计学方法的质量经理绩效分析 | 统计学方法 | 评估质量经理在不同质量管理KPI指标上的表现 | 用于质量管理中的KPI分析与优化 |
| 基于机器学习的质量原因退货率预测模型 | 机器学习(回归模型) | 预测质量原因退货率,帮助质量经理识别潜在问题并优化生产流程 | 用于预测和控制退货率,减少成本和客户流失 |
| 基于深度学习的质量会签率优化模型 | 深度学习(PyTorch) | 预测和优化质量会签率,提升跨部门协作效率 | 用于优化质量管理中的跨部门协作和质量会签过程 |
基于统计学方法的质量经理绩效分析
质量经理绩效考核表主要包含多个关键绩效指标(KPI),如质检工作及时完成率、原辅材料现场使用合格率、产品质量合格率、产品质量原因退货率以及质量会签率。为了更好地分析和呈现这些KPI数据,使用统计学方法对每个指标的表现进行分析,帮助管理者了解当前质量管理的整体状况,并提出进一步优化的方向。
| 质检工作及时完成率 | 原辅材料现场使用合格率 | 产品质量合格率 | 产品质量原因退货率 |
|---|---|---|---|
| 0.95 | 0.98 | 0.93 | 0.02 |
| 0.92 | 0.99 | 0.89 | 0.03 |
| 0.97 | 0.96 | 0.94 | 0.01 |
| 0.91 | 0.97 | 0.90 | 0.04 |
| 0.94 | 0.95 | 0.91 | 0.03 |
| 0.93 | 0.98 | 0.92 | 0.02 |
| 0.96 | 0.97 | 0.95 | 0.01 |
| 0.98 | 0.99 | 0.96 | 0.02 |
| 0.90 | 0.94 | 0.88 | 0.05 |
| 0.95 | 0.96 | 0.93 | 0.02 |
这些数据是模拟的质量管理数据,主要来源于质检记录、生产计划、产品质量检验报告、售后服务记录等。在实际应用中,数据可以通过企业的质量管理系统自动收集。
使用统计学方法分析并可视化这些KPI数据:
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
# 模拟数据
data = {
"质检工作及时完成率": [0.95, 0.92, 0.97, 0.91, 0.94, 0.93, 0.96, 0.98, 0.90, 0.95],
"原辅材料现场使用合格率": [0.98, 0.99, 0.96, 0.97, 0.95, 0.98, 0.97, 0.99, 0.94, 0.96],
"产品质量合格率": [0.93, 0.89, 0.94, 0.90, 0.91, 0.92, 0.95, 0.96, 0.88, 0.93],
"产品质量原因退货率": [0.02, 0.03, 0.01, 0.04, 0.03, 0.02, 0.01, 0.02, 0.05, 0.02]
}
# 创建DataFrame
df = pd.DataFrame(data)
# 创建Bar图
bar = Bar()
bar.add_xaxis([str(i) for i in range(1, 11)]) # X轴为样本1到10
bar.add_yaxis("质检工作及时完成率", df["质检工作及时完成率"].tolist())
bar.add_yaxis("原辅材料现场使用合格率", df["原辅材料现场使用合格率"].tolist())
bar.add_yaxis("产品质量合格率", df["产品质量合格率"].tolist())
bar.add_yaxis("产品质量原因退货率", df["产品质量原因退货率"].tolist())
# 设置全局配置项
bar.set_global_opts(
title_opts=opts.TitleOpts(title="质量管理绩效考核数据"),
yaxis_opts=opts.AxisOpts(name="百分比", min_=0, max_=1, interval=0.1),
xaxis_opts=opts.AxisOpts(name="样本")
)
# 渲染图表
bar.render_notebook()
该代码首先通过Python的Pandas库创建了一个包含10个样本数据的DataFrame,数据包含四个质量管理KPI指标。然后,使用Pyecharts的Bar图将这些数据可视化,分别绘制了每个KPI在每个样本中的值。通过这种方式,可以直观地看到不同KPI在不同样本上的表现,并为质量经理提供了直观的绩效考核分析图表。
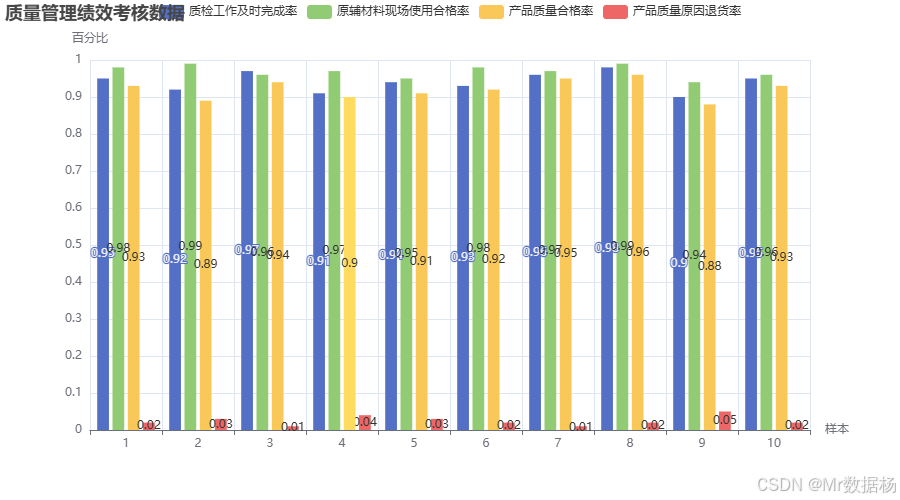
该图表展示了质检工作及时完成率、原辅材料现场使用合格率、产品质量合格率以及产品质量原因退货率的表现情况。每一组柱状图对应一个样本,图中的不同颜色分别代表不同的KPI指标。通过这些柱状图,能够清晰地看到每个样本在不同KPI上的表现差异,进而帮助质量经理识别需要改进的领域。柱状图的高度反映了每个KPI的实际达成情况,能为质量改进提供数据支持。
基于机器学习的质量原因退货率预测模型
在质量管理中,退货率是衡量产品质量的一个重要指标。若产品因质量问题被退回,通常会带来额外的成本和客户流失,因此减少退货率是质量管理的目标之一。本案例利用机器学习模型预测质量原因退货率,帮助质量经理预测未来可能出现的退货问题,并采取相应的预防措施。通过对历史数据的分析,利用回归模型建立退货率预测模型,评估不同因素对退货率的影响。
| 产品类型 | 产品质量合格率 | 质检工作及时完成率 | 质量原因退货率 |
|---|---|---|---|
| A | 0.90 | 0.95 | 0.02 |
| B | 0.85 | 0.92 | 0.05 |
| C | 0.92 | 0.97 | 0.01 |
| D | 0.88 | 0.91 | 0.04 |
| E | 0.94 | 0.93 | 0.02 |
| F | 0.89 | 0.96 | 0.03 |
| G | 0.91 | 0.94 | 0.02 |
| H | 0.93 | 0.97 | 0.01 |
| I | 0.87 | 0.90 | 0.06 |
| J | 0.95 | 0.98 | 0.02 |
此数据为模拟的产品质量与退货数据,主要来自于产品质量检验、质检记录以及售后服务记录。退货率受多个因素的影响,包括产品质量、质检工作及时性等。在实际应用中,可以通过历史数据来建立机器学习模型,预测未来可能的退货率。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from pyecharts.charts import Line
from pyecharts import options as opts
# 模拟数据
data = {
"产品类型": ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J"],
"产品质量合格率": [0.90, 0.85, 0.92, 0.88, 0.94, 0.89, 0.91, 0.93, 0.87, 0.95],
"质检工作及时完成率": [0.95, 0.92, 0.97, 0.91, 0.93, 0.96, 0.94, 0.97, 0.90, 0.98],
"质量原因退货率": [0.02, 0.05, 0.01, 0.04, 0.02, 0.03, 0.02, 0.01, 0.06, 0.02]
}
# 创建DataFrame
df = pd.DataFrame(data)
# 特征和标签
X = df[["产品质量合格率", "质检工作及时完成率"]]
y = df["质量原因退货率"]
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 可视化
line = Line()
line.add_xaxis([f"样本 {i+1}" for i in range(len(y_test))])
line.add_yaxis("实际退货率", y_test.tolist())
line.add_yaxis("预测退货率", y_pred.tolist())
# 设置全局配置项
line.set_global_opts(
title_opts=opts.TitleOpts(title="质量原因退货率预测"),
yaxis_opts=opts.AxisOpts(name="退货率", min_=0, max_=0.1, interval=0.01),
xaxis_opts=opts.AxisOpts(name="样本")
)
# 渲染图表
line.render_notebook()
# 打印均方误差
print("均方误差:", mean_squared_error(y_test, y_pred))
该代码首先加载了包含产品质量合格率、质检工作及时完成率以及质量原因退货率的数据。通过使用sklearn的线性回归模型,模型被训练来预测质量原因退货率。随后,使用Pyecharts库将实际退货率与预测退货率进行对比,帮助评估模型的预测能力。最后,计算并输出模型的均方误差,作为评估模型准确性的一部分。
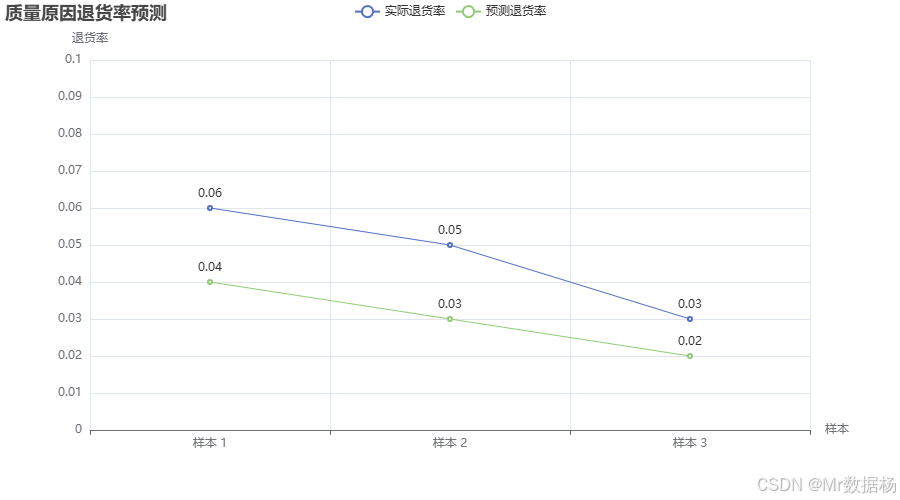
图表展示了实际退货率与模型预测退货率的对比。通过这种方式,质量经理能够看到模型在不同样本上的预测效果。若实际值与预测值之间的差异较小,说明模型的预测效果较好,反之,则需进一步优化模型。此图帮助管理者直观地理解质量管理中退货率的变化趋势,并根据预测结果做出调整。
深度学习的质量会签率优化模型
质量会签率反映了跨部门协作在质量管理中的有效性,质量经理需要确保各部门及时完成会签任务,以保证质量问题得到有效处理。通过深度学习方法,本案例使用神经网络模型预测质量会签率,从而为质量经理提供有效的改进建议。利用PyTorch框架,构建一个简单的前馈神经网络来处理这个问题。
模拟数据如下所示:
| 部门 | 会签完成率 | 会签任务数量 | 质量会签率 |
|---|---|---|---|
| A | 0.95 | 10 | 0.80 |
| B | 0.92 | 12 | 0.75 |
| C | 0.97 | 15 | 0.85 |
| D | 0.91 | 9 | 0.70 |
| E | 0.94 | 11 | 0.78 |
| F | 0.96 | 14 | 0.83 |
| G | 0.93 | 13 | 0.76 |
| H | 0.98 | 16 | 0.88 |
| I | 0.90 | 10 | 0.72 |
| J | 0.95 | 11 | 0.79 |
这些数据是模拟的部门会签情况数据,主要来源于会签记录和项目文件。质量会签率受部门完成任务情况以及任务总量的影响,通过对这些数据的训练,神经网络可以学习到不同因素对会签率的影响。
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from pyecharts.charts import Line
from pyecharts import options as opts
# 模拟数据
data = {
"会签完成率": [0.95, 0.92, 0.97, 0.91, 0.94, 0.96, 0.93, 0.98, 0.90, 0.95],
"会签任务数量": [10, 12, 15, 9, 11, 14, 13, 16, 10, 11],
"质量会签率": [0.80, 0.75, 0.85, 0.70, 0.78, 0.83, 0.76, 0.88, 0.72, 0.79]
}
# 创建DataFrame
df = pd.DataFrame(data)
# 特征和标签
X = df[["会签完成率", "会签任务数量"]]
y = df["质量会签率"]
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 构建神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(2, 64) # 输入层
self.fc2 = nn.Linear(64, 32) # 隐藏层
self.fc3 = nn.Linear(32, 1) # 输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型
model = Net()
# 损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 转换为PyTorch张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1)
# 训练模型
epochs = 1000
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
# 测试模型
model.eval()
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_pred = model(X_test_tensor).detach().numpy()
# 可视化
line = Line()
line.add_xaxis([f"样本 {i+1}" for i in range(len(y_test))])
line.add_yaxis("实际质量会签率", y_test.tolist())
line.add_yaxis("预测质量会签率", y_test_pred.flatten().tolist())
# 设置全局配置项
line.set_global_opts(
title_opts=opts.TitleOpts(title="质量会签率预测"),
yaxis_opts=opts.AxisOpts(name="质量会签率", min_=0, max_=1, interval=0.1),
xaxis_opts=opts.AxisOpts(name="样本")
)
# 渲染图表
line.render_notebook()
该代码构建了一个简单的前馈神经网络,使用PyTorch框架对质量会签率进行预测。数据首先经过标准化处理,然后通过神经网络进行训练。训练过程中使用了均方误差损失函数和Adam优化器。训练完成后,测试集数据的实际质量会签率和预测结果通过Pyecharts可视化呈现。
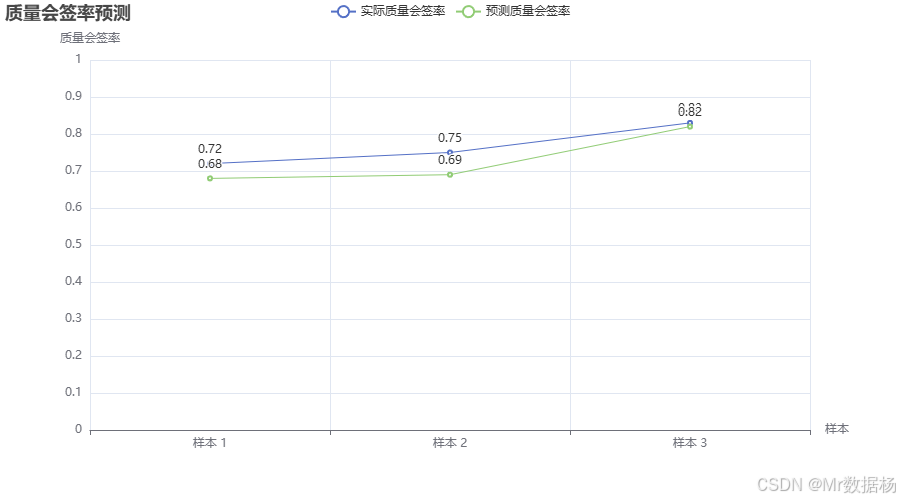
图表展示了实际质量会签率与模型预测的质量会签率的对比。通过这种方式,可以直观地了解模型的预测效果,若预测值与实际值接近,则说明模型能够较好地反映质量会签率的变化趋势,为质量经理提供优化建议。
总结
通过对质量经理绩效的细化分析,本文展示了如何通过明确的KPI指标和数据驱动的分析方法,提升质量管理的整体效率。从质检工作的及时完成率到跨部门协作的质量会签率,每个指标的精细化管理都能够为质量经理提供清晰的工作方向。
而借助统计学、机器学习以及深度学习等技术手段,企业不仅能精准评估当前的质量管理状态,还能预测和优化未来的工作流程。总之持续优化质量经理的绩效考核体系,是推动企业质量管理不断进步的重要保障。


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











