







1 聚合函数
ClickHouse 中的聚合函数,因为和关系型数据库的相似性,本来聚合函数不打算说的,但是 ClickHouse 提供了很多关系型数据库中没有的函数,所以我们还是从头了解一下。
1.1 count
count:计算数据的行数,有以下几种方式:
count(字段):计算该字段中不为 Null 的元素数量
count()、count(*):计算数据集的总行数
一、所以如果某个字段中不包含 Null,那么对该字段进行 count 得到的结果和 count()、count(*) 是相等的。
SELECT count(), count(*), count(product) FROM sales_data;
二、这里再提一下聚合函数,聚合函数针对的是多行结果集,而不是数组。
-- 这里得到的是 1,原因在于这里只有一行数据
SELECT count([1, 2, 3]);
/*
┌─count()─┐
│ 1 │
└─────────┘
*/
-- 如果将其展开的话,那么会得到 3,因为展开之后变成了 3 行数据
SELECT count(arrayJoin([1, 2, 3]));
/*
┌─count(arrayJoin([1, 2, 3]))─┐
│ 3 │
└─────────────────────────────┘
*/
三、当然使用 count 计算某个字段的元素数量时,还可以进行去重。
SELECT count(DISTINCT product) FROM sales_data;
/*
┌─uniqExact(product)─┐
│ 3 │
└────────────────────┘
*/
-- 根据返回的字段名,我们发现 ClickHouse 在底层实际上调用的是 uniqExact 函数
SELECT uniqExact(product) FROM sales_data;
/*
┌─uniqExact(product)─┐
│ 3 │
└────────────────────┘
*/
-- 也就是 count(DISTINCT) 等价于 uniqExact
-- 不过还是建议像关系型数据库那样使用 count(DISTINCT) 比较好,因为更加习惯
1.2 sum
min、max、sum、avg:计算每组数据的最小值、最大值、总和、平均值
SELECT min(amount), max(amount), sum(amount), avg(amount)
FROM sales_data GROUP BY product, channel;
1.3 least和greatest
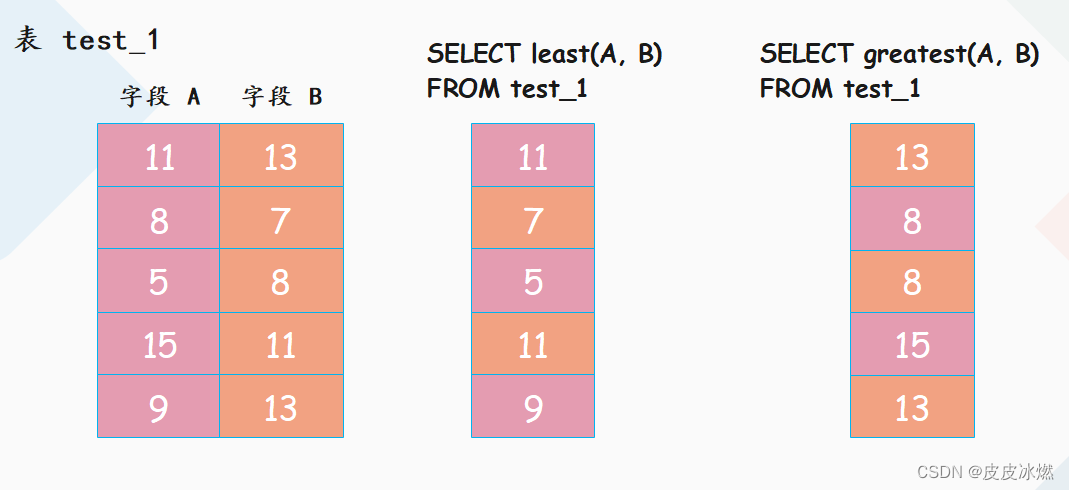
除此之外还有两个非聚合函数 least、greatest 也比较实用,那么这两个函数是干什么的呢?看一张图就明白了。
SELECT least(A, B), greatest(A, B) FROM test_1;
问题来了,如果 ClickHouse 没有提供 least 和 greatest 这两个函数,那么我们要如何实现此功能呢?首先我们可以使用 arrayMap:
-- 由于 arrayMap 针对的是数组,不是多行结果集,所以需要借助 groupArray 将多行结果集转成数组
-- 另外在比较大小的时候也要将两个元素组合成数组 [x, y],然后使用 arrayMin 比较
-- 或者使用 least(x, y) 也可以对两个标量进行比较,不过这里我们是为了实现 least,所以就不用它了
SELECT arrayMap(x, y -> arrayMin([x, y]), groupArray(A), groupArray(B)) arr FROM test_1;
/*
┌─arr───────────┐
│ [11,7,5,11,9] │
└───────────────┘
*/
-- 结果确实实现了,但结果是数组,我们还要再将其展开成多行
-- 这里我们使用 WITH,注意 WITH 子句里的查询只可以返回一行结果集
WITH (
SELECT arrayMap(x, y -> arrayMin([x, y]), groupArray(A), groupArray(B)) FROM test_1
) AS arr SELECT arrayJoin(arr);
/*
┌─arrayJoin(arr)─┐
│ 11 │
│ 7 │
│ 5 │
│ 11 │
│ 9 │
└────────────────┘
*/
以上就实现了 least,至于 greatest 也是同理。那么除了使用数组的方式,还可以怎么做呢?如果将这个问题的背景再改成关系型数据库的话,你一定能想到,没错,就是 CASE WHEN。
SELECT CASE WHEN A < B THEN A ELSE B END FROM test_1;
/*
┌─multiIf(less(A, B), A, B)─┐
│ 11 │
│ 7 │
│ 5 │
│ 11 │
│ 9 │
└───────────────────────────┘
*/
整个过程显然变得简单了,所以也不要忘记关系型数据库的语法在 ClickHouse 中也是可以使用的,另外我们看到返回的结果集的字段名叫 multiIf…,虽然我们使用的是 CASE WHEN,但是 ClickHouse 在底层会给语句进行优化,在功能不变的前提下,寻找一个在 ClickHouse 中效率更高的替代方案。因此你直接使用 multiIf… 也是可以的,比如:
SELECT multiIf(less(A, B), A, B) FROM test_1
而至于上面的 multiIf,它的功能和 CASE WHEN 是完全类似的。只不过这里个人有一点建议,既然 ClickHouse 会进行语句的优化,那么能用关系型数据库语法解决的问题,就用关系型数据库语法去解决。这么做的原因主要是为了考虑 SQL 语句的可读性,因为相比 ClickHouse,大部分人对关系型数据库语法显然更熟悉一些。如果使用这里的 mulitIf…,那么当别人阅读时,可能还要查阅一下 multiIf 函数、或者 mulitIf 里面又调用的 less 函数是做什么的;但如果使用 CASE WHEN,绝对的一目了然。
1.4 any
any:选择每组数据中第一个出现的值
-- 按照product, channel进行分组之后,我们可以求每组的最小值、最大值、平均值等等
-- 而这里的 any 则表示获取每组第一个出现的值
SELECT any(amount) FROM sales_data GROUP BY product, channel;
当然 any 看起来貌似没有实际的意义,因为聚合之后每组第一个出现的值并不一定能代表什么。
一、那么问题来了,如果想选择分组中的任意一个值,该怎么办呢?
-- 使用 groupArray 变成一个数组,然后再通过索引选择即可
-- 因为我们选择的是第 1 个元素,所以此时等价于 any
SELECT groupArray(amount)[1] FROM sales_data
GROUP BY product, channel;
二、如果想分组之后选择,选择每个组的最小值该怎么做呢?
-- 在上面的基础上再调用一下 arrayMin 即可
SELECT arrayMin(groupArray(amount)) FROM sales_data
GROUP BY product, channel;
三、如果想分组之后选择,选择每个组的第 N 大的值该怎么做呢?比如我们选择第 3 大的值。
-- 从小到大排个序即可,然后选择索引为 -3 的元素
-- 或者从大到小排个序,然后选择索引为 3 的元素
SELECT arraySort(groupArray(amount))[-2] rank3_1, arrayReverseSort(groupArray(amount))[2] rank3_2
FROM sales_data GROUP BY product, channel;
/*
┌─rank3_1─┬─rank3_2─┐
│ 2784 │ 2784 │
│ 2804 │ 2804 │
│ 2650 │ 2650 │
│ 2856 │ 2856 │
│ 2865 │ 2865 │
│ 2610 │ 2610 │
│ 2632 │ 2632 │
│ 2754 │ 2754 │
│ 2694 │ 2694 │
└─────────┴─────────┘
*/
确实给人一种 pandas 的感觉,之前做数据分析主要用 pandas。但是 pandas 有一个致命的问题,就是它要求数据能全部加载到内存中,所以在处理中小型数据集的时候确实很方便,但是对于大型数据集就无能为力了,只能另辟蹊径。但是 ClickHouse 则是通过分片机制支持分布式运算,所以个人觉得它简直就是分布式的 pandas。
1.5 varPop方差
四、varPop:计算方差;stddevPop:计算标准差,等于方差开根号
SELECT varPop(amount) v1, stddevPop(amount) v2, v2 * v2
FROM sales_data;
问题来了,如果我们想手动实现方差的计算该怎么办?试一下:
-- 将结果集转成数组,并先计算好平均值
WITH (SELECT groupArray(amount) FROM sales_data) AS arr,
arraySum(arr) / length(arr) AS amount_avg
-- 通过arrayMap将数组中的每一个元素都和平均值做减法,然后再平方,得到新数组
-- 最后再用arrayAvg对新数组取平均值,即可计算出方差
SELECT arrayAvg(
arrayMap(x -> pow(x - amount_avg, 2), arr)
)
1.6 covarPop协方差
五、covarPop:计算协方差
比较少用,这里不演示的了,可以自己测试一下。
1.7 anyHeavy
anyHeavy:使用 heavy hitters 算法选择每组中出现频率最高的值
SELECT anyHeavy(amount) FROM sales_data;
1.8 anyLast
anyLast:选择每组中的最后一个值
SELECT anyLast(amount) FROM sales_data GROUP BY product, channel;
-- 同样可以借助数组实现
SELECT groupArray(amount)[-1] FROM sales_data
GROUP BY product, channel;
1.9 argMin和argMax
argMin:接收两个列,根据另一个列选择当前列的最小值,我们画一张图,通过和 min 进行比对,就能看出它的用法了
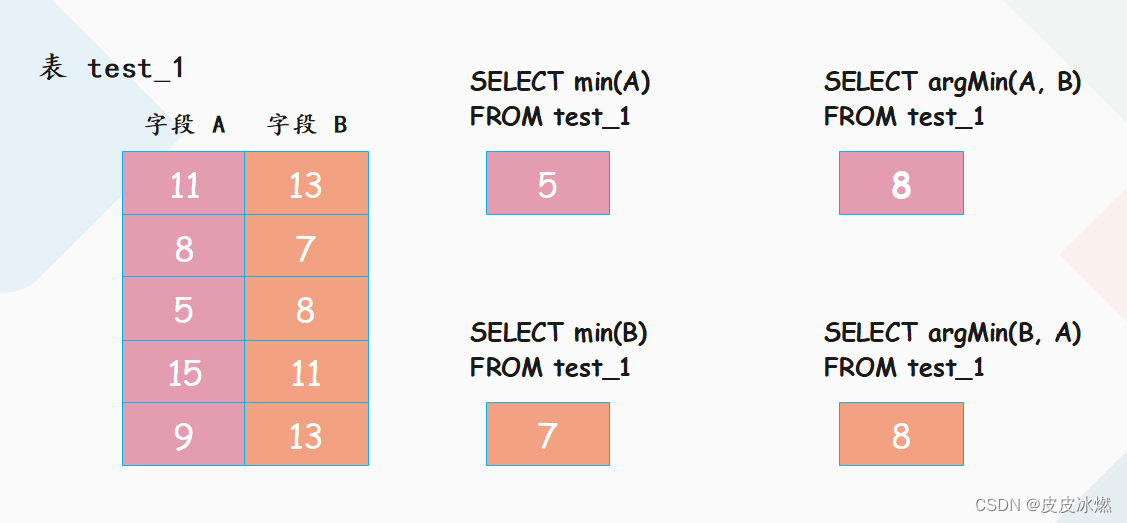
首先 min(A) 和 min(B) 分别返回 5 和 7 无需解释,而 argMin(A, B) 表示根据 B 的最小值选择 A,B 的最小值是 7,对应 A 就是 8;同理 argMin(B, A) 表示根据 A 的最小值选择 B,A 的最小值是 5,对应 B 就是 8。
以上就是 argMin,同理还有 argMax。
1.10 topK
topK:选择出现频率最高的 K 个元素
-- 这里选择出现频率最高的两个元素
SELECT topK(2)(arrayJoin([1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3]));
/*
┌─topK(2)(arrayJoin([1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3]))─┐
│ [1,3] │
└──────────────────────────────────────────────────────────┘
*/
我们看到以数组的形式返回,因为聚合函数最终每个组只会对应一行数据,所以得到的是数组。
topK 也是非常常见的,如果让我们自己实现,虽然可以做到,但会比较麻烦,ClickHouse 替我们考虑的还是很周到的。
1.11 groupArrayMovingSum
groupArrayMovingSum:滑动窗口,每个窗口内的数据进行累和。
SELECT groupArray(number), groupArrayMovingSum(4)(number)
FROM (SELECT number FROM numbers(10));
/*
┌─groupArray(number)────┬─groupArrayMovingSum(4)(number)─┐
│ [0,1,2,3,4,5,6,7,8,9] │ [0,1,3,6,10,14,18,22,26,30] │
└───────────────────────┴────────────────────────────────┘
*/
画一张图,来解释一下:首先 groupArrayMovingSum(4) 表示窗口的长度为 4,然后不断的向下滑动,计算包含当前元素在内往上的四个元素之和。如果元素的个数不够窗口的长度,那么有几个算几个,比如前三个元素。

那么试想一下,如果窗口长度等于数组的长度,那么会发生什么呢?
-- 不指定窗口长度,那么窗口长度就等于数组长度
SELECT groupArray(number), groupArrayMovingSum(number)
FROM (SELECT number FROM numbers(10));
/*
┌─groupArray(number)────┬─groupArrayMovingSum(number)─┐
│ [0,1,2,3,4,5,6,7,8,9] │ [0,1,3,6,10,15,21,28,36,45] │
└───────────────────────┴─────────────────────────────┘
*/
-- 显然相当于进行了累和
这就是 ClickHouse 提供的窗口函数,但关系型数据库中的窗口函数语法在 ClickHouse 还没有得到完美的支持,但很明显通过这些强大的函数我们也可以实现相应的功能。
除了 groupArrayMovingSum 之外,还有一个 groupArrayMovingAvg,用法完全一样,只不过计算的是平均值,这里就不单独说了。
1.12 groupArraySample
groupArraySample:随机选择 N 个元素
-- 随机选择 3 个元素
SELECT groupArraySample(3)(amount) FROM sales_data;
/*
┌─groupArraySample(3)(amount)─┐
│ [1268,2246,1606] │
└─────────────────────────────┘
*/
我们还可以绑定一个随机种子,如果种子一样,那么每次随机选择的数据也是一样的。
SELECT groupArraySample(3, 666)(amount) FROM sales_data;
/*
┌─groupArraySample(3, 666)(amount)─┐
│ [635,1290,1846] │
└──────────────────────────────────┘
*/
SELECT groupArraySample(3, 666)(amount) FROM sales_data;
/*
┌─groupArraySample(3, 666)(amount)─┐
│ [635,1290,1846] │
└──────────────────────────────────┘
*/
SELECT groupArraySample(3, 661)(amount) FROM sales_data;
/*
┌─groupArraySample(3, 661)(amount)─┐
│ [2011,2125,1542] │
└──────────────────────────────────┘
*/
1.13 deltaSum
deltaSum:对相邻的行进行做差,然后求和,注意:小于 0 不会计算在内
-- 3 - 1 = 2
-- 4 - 3 = 1
-- 1 - 4 = -3
-- 8 - 1 = 7
-- 所以结果为 2 + 1 + 7
SELECT deltaSum(arrayJoin([1, 3, 4, 1, 8]));
/*
┌─deltaSum(arrayJoin([1, 3, 4, 1, 8]))─┐
│ 10 │
└──────────────────────────────────────┘
*/
















 3920
3920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











