







上次写的裸服务器上语音AI部署指南-CSDN博客主要聚焦于 PaddleSpeech 和 ChatChat 框架功能的安装和使用,虽然框架功能可以正常运行,但与项目的结合可能存在版本依赖问题。本文基于项目的实际使用场景,深入剖析该项目的部署细节,适配cpu和gpu以及linux和window。帮助有同样问题的伙伴们更好地完成环境搭建和问题解决。
项目概述
项目名称:语音互动AI
技术架构:PaddlePaddle、PaddleSpeech、LangChain-chatchat
环境配置指南
-
创建虚拟环境
使用conda创建隔离的运行环境,确保与主机环境的依赖隔离:conda create -n ai-service-python python==3.10.15 conda activate ai-service-python -
确认
pip版本
保证pip工具的版本为 24.2:python -m pip install pip==24.2 -
安装必要依赖
安装核心框架及依赖:
gpu版本安装需要先安装好cuda和cudnn,当前项目测试的版本是:
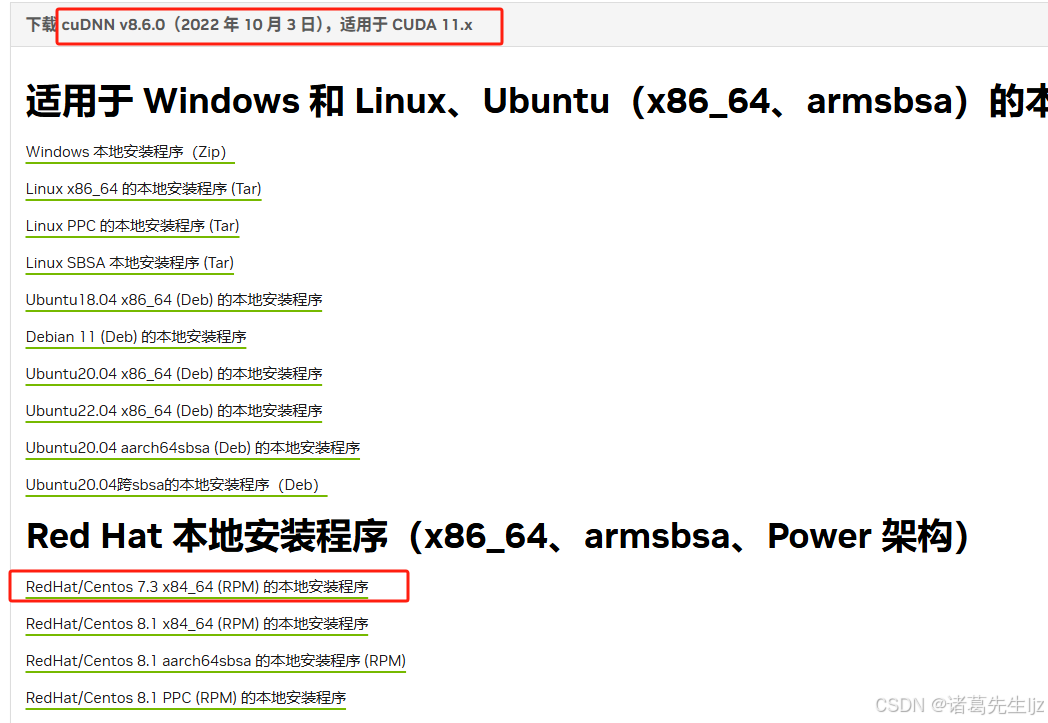 CUDA与cuDNN历史版本对照查看:cuDNN 历史版本 | NVIDIA 开发者
CUDA与cuDNN历史版本对照查看:cuDNN 历史版本 | NVIDIA 开发者
在项目运行时,paddle会去加载/usr/local/cuda/lib64/libcudnn打头的相关文件,确保目录下有这些文件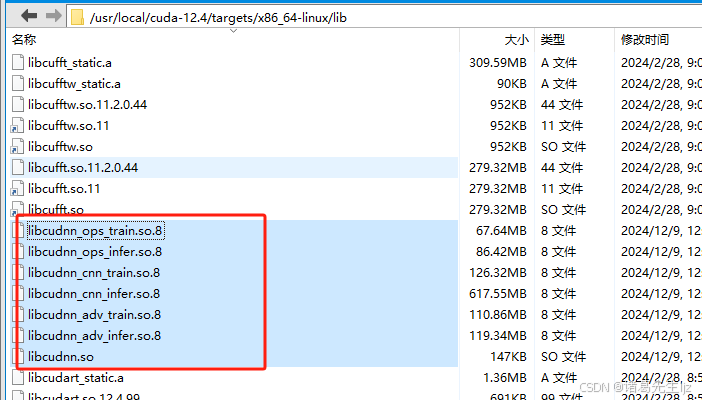
#有出现由于opencc版本太高无法启动的情况,可将版本降到1.1.0
pip show opencc
pip install opencc==1.1.0
pip install pytest-runner
# cpu版本安装
pip install paddlepaddle==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
# gpu版本安装
python -m pip install paddlepaddle-gpu==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddlespeech==1.4.1
pip install -r requirements.txt
# requirements.txt文件中的依赖(这是项目中使用到的依赖项,大家根据自身项目情况调整):
aiofiles==24.1.0
numpy==1.23.5
openpyxl~=3.0.9
faiss-cpu==1.8.0.post1
eyed3~=0.9.6
scipy==1.10.1
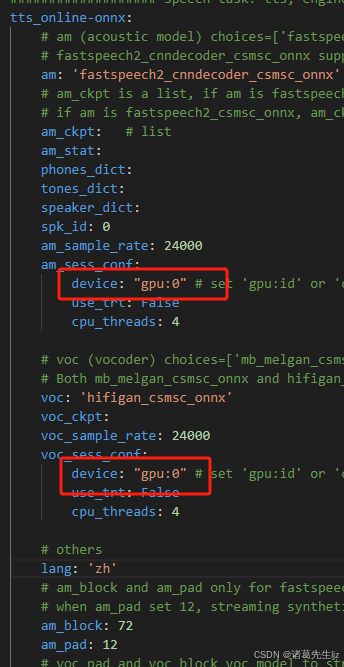
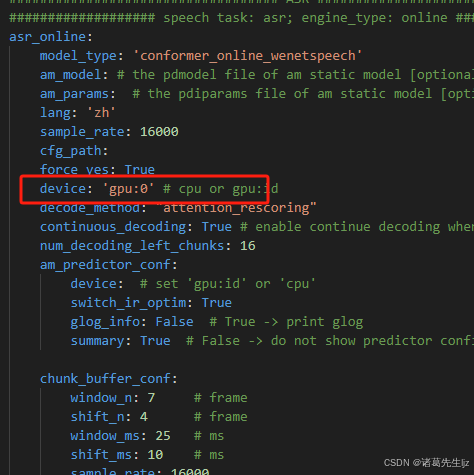
python-multipart==0.0.19安装gpu版本时,需要修改device配置为gpu:id,cpu则配置为cpu
查看cpu ID:
nvidia-smi 
常见异常及解决方案
异常 1:window中可能会遇到error: Microsoft Visual C++ 14.0 or greater is required异常
原因:webrtcvad 需要 C++ 编译器。
解决方案:下载并安装 Microsoft C++ Build Tools。安装时勾选 C++ 生成工具(C++ Build Tools)。
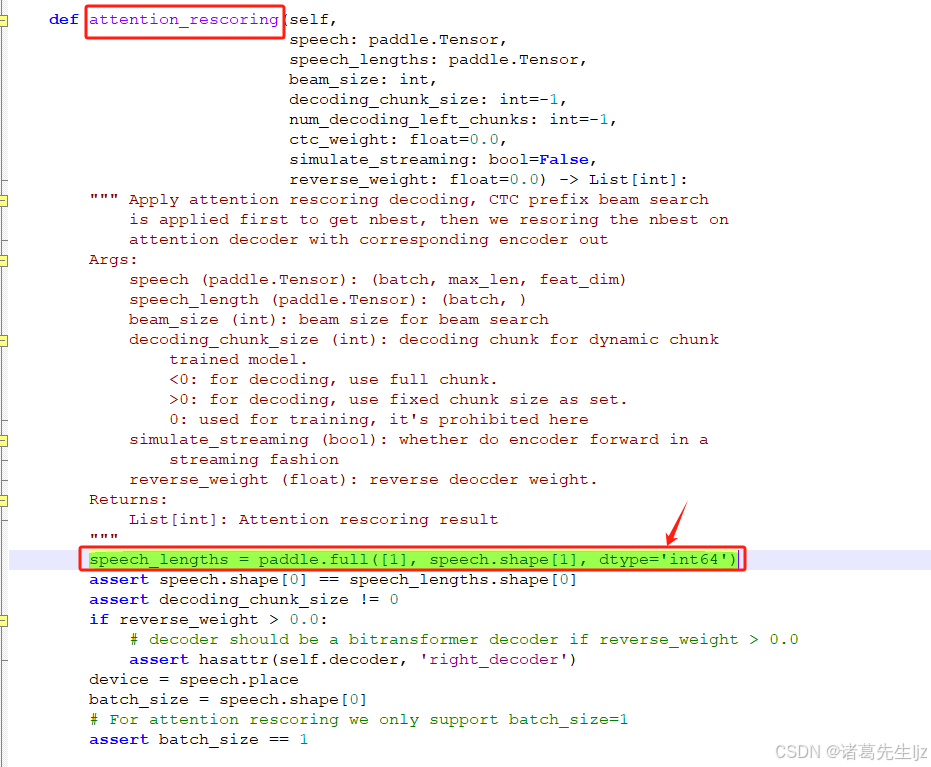
异常 2:IndexError: list index out of range KeyError: 'result'
原因:PaddleSpeech 中部分代码需要调整。
解决方案:window在路径 \anaconda3\envs\ai-service-python\Lib\site-packages\paddlespeech\s2t\models\u2 中编辑u2.py文件,linux在路径/root/anaconda3/envs/ai-service-python/lib/python3.10/site-packages/paddlespeech/s2t/models/u2中编辑u2.py文件,搜索:attention_rescoring函数,添加以下代码:
speech_lengths = paddle.full([1], speech.shape[1], dtype='int64')
异常 3:TabError: inconsistent use of tabs and spaces in indentation
原因:代码缩进不一致。
解决方案:确保新增代码及其上下文缩进一致。
项目打包与测试
Windows平台
-
安装 PyInstaller
pip install pyinstaller -
打包项目
运行以下命令,生成项目的独立可执行文件:#可配置输出到指定目录下 pyinstaller --onedir main.py -
执行完上面命令后,会产生main.spec文件,pyinstaller打包方式会丢失一些项目中需要使用到的格式文件或依赖目录,需要对main.spec文件内容进行调整,让它能够动态收集 site-packages下所有内容,这样可以避免要不断的调试,不断的添加:
# -*- mode: python ; coding: utf-8 -*- # 获取 site-packages 路径 site_packages_path = "E:/soft/anaconda3/envs/ai-service-python/Lib/site-packages" # 动态收集 site-packages 下所有内容 datas = [ (os.path.join(root, file), os.path.relpath(root, site_packages_path)) for root, _, files in os.walk(site_packages_path) for file in files ] a = Analysis( ['main.py'], pathex=[], binaries=[], datas=datas, hiddenimports=[], hookspath=[], hooksconfig={}, runtime_hooks=[], excludes=[], noarchive=False, optimize=0, ) pyz = PYZ(a.pure) exe = EXE( pyz, a.scripts, [], exclude_binaries=True, name='main', debug=False, bootloader_ignore_signals=False, strip=False, upx=True, console=True, disable_windowed_traceback=False, argv_emulation=False, target_arch=None, codesign_identity=None, entitlements_file=None, ) coll = COLLECT( exe, a.binaries, a.datas, strip=False, upx=True, upx_exclude=[], name='main', )#调整完main.spec再执行 pyinstaller main.spec -
执行程序
打包完成后,运行生成的可执行文件:dist/main/main.exe
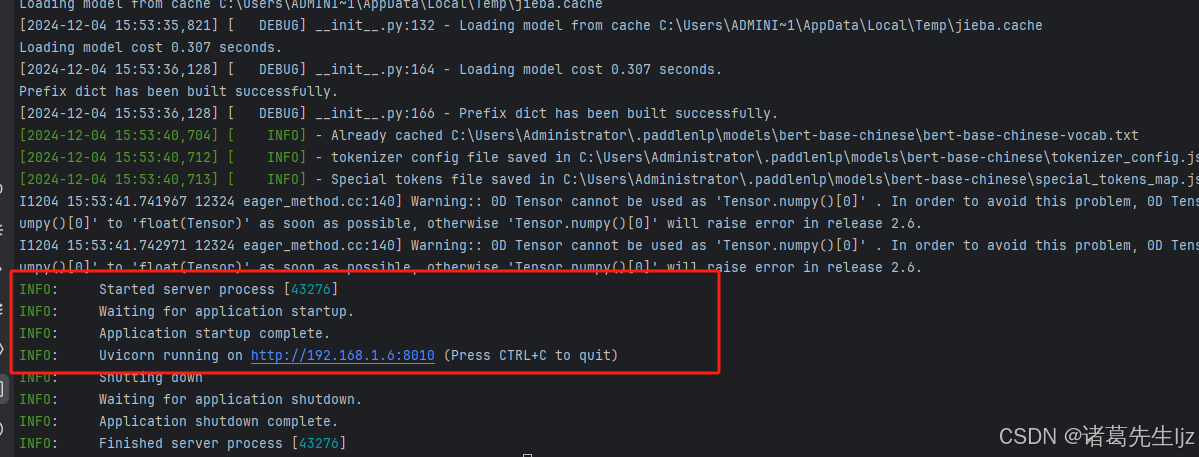
#防火墙添加8010端口
firewall-cmd --zone=public --add-port=8010/tcp --permanent
#防火墙重新加载配置
firewall-cmd --reloadLinux平台
linux部署方式与window类似,如果在运行时遇到 opencc 版本问题,安装 opencc 的 1.1.0 版本即可。已经过实操验证!
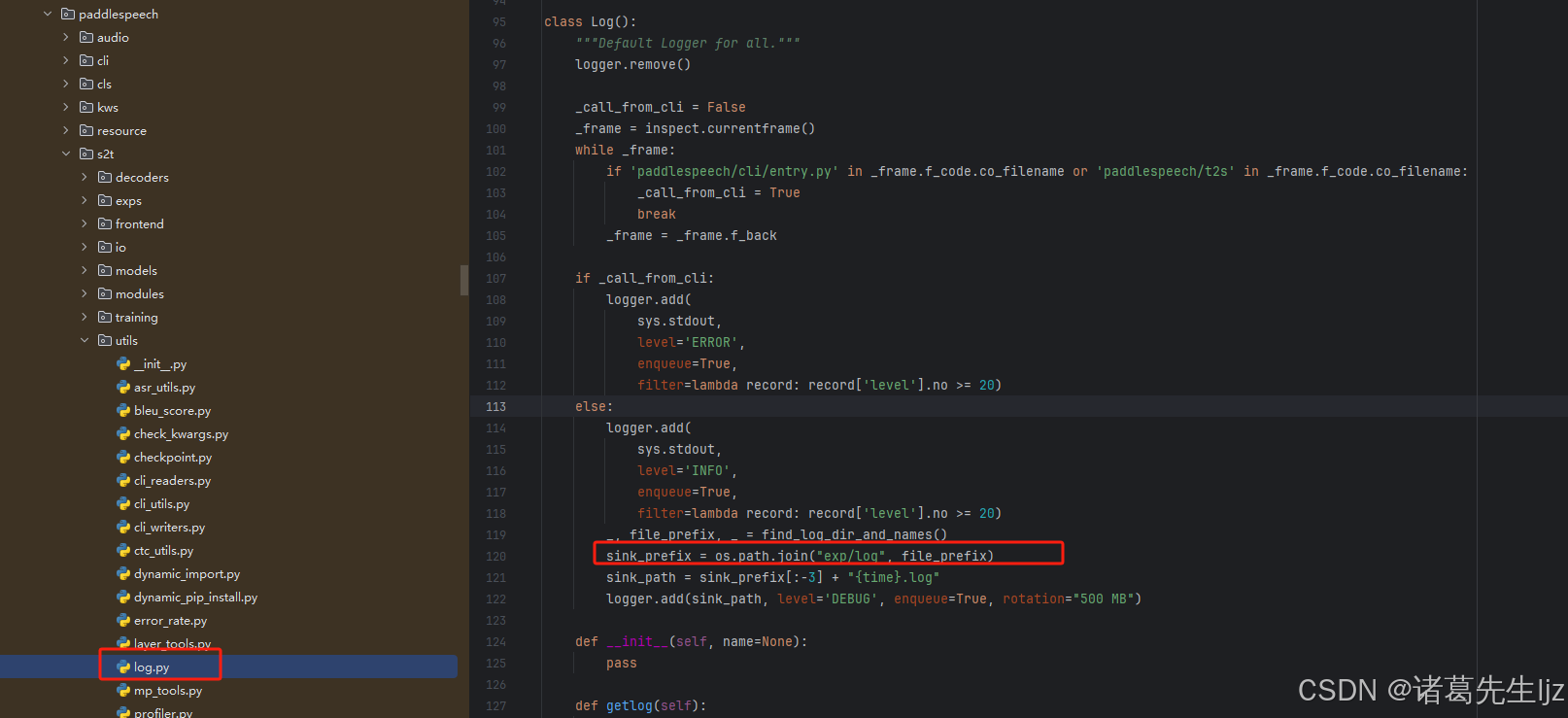
日志路径调整
PaddleSpeech 默认将日志输出到 exp/log 目录。如果需要调整日志路径,可以编辑以下文件:
路径:anaconda3\envs\ai-service-python\Lib\site-packages\paddlespeech\s2t\utils\log.py
具体修改方式参考项目文档。
结语
通过本文的部署指南,希望能帮助伙伴们轻松完成语音互动AI项目的搭建。如果在部署过程中遇到其他问题,欢迎在评论区交流探讨!
【持续更新~】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









