







效果展示
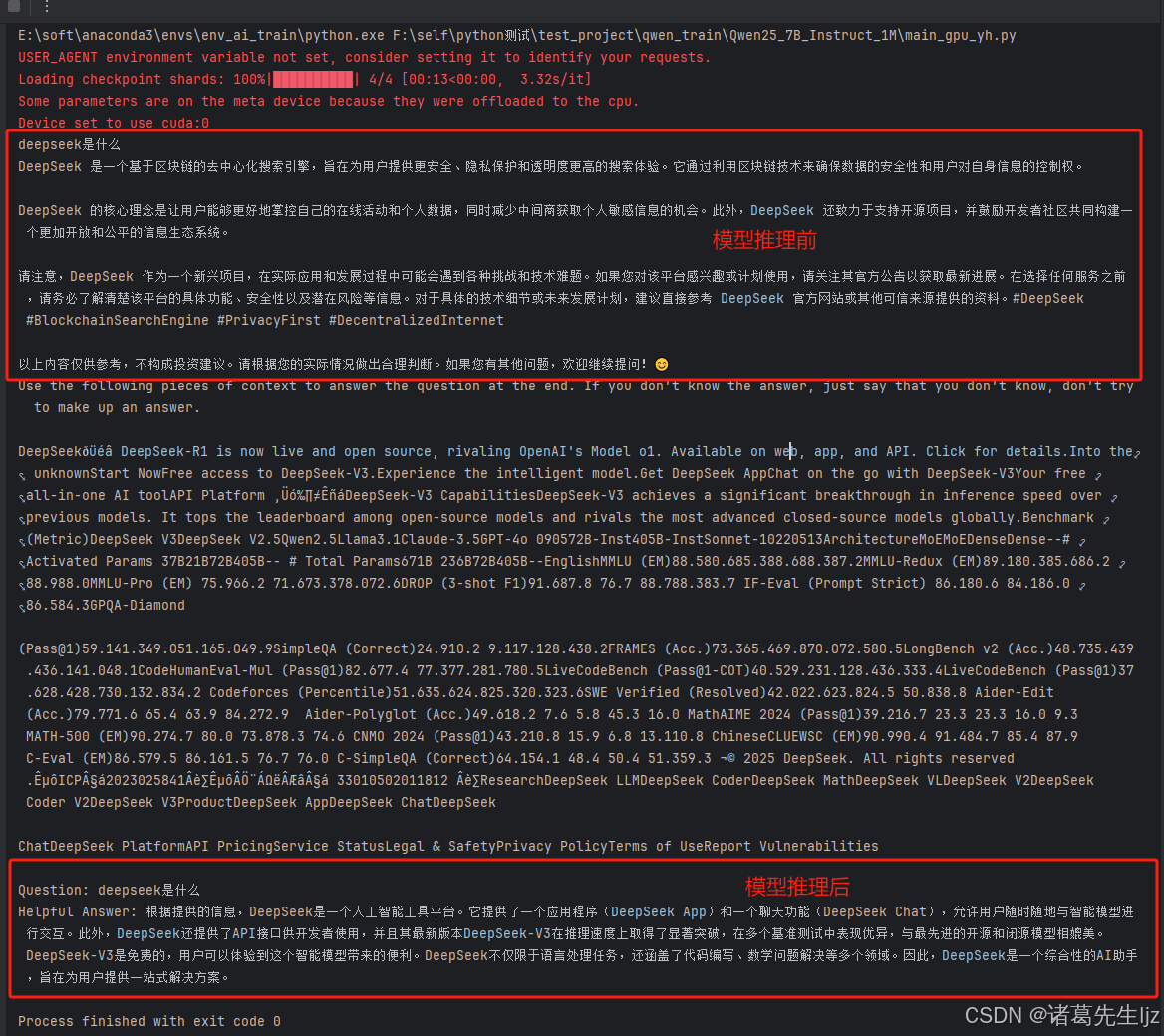
说明
本代码的主要目标是使用 Qwen2.5-7B 进行推理,就是让模型在给定输入的情况下,生成合理的文本输出,而非训练模型。
为什么选择推理而非训练?
在实际应用开发过程中,我们都希望模型具备特定领域的专业知识。然而,直接训练一个大语言模型需要大量的数据、计算资源和时间,对于大多数应用来说并不现实。所以推理更适用于实际开发场景。推理是指直接使用已经预训练好的模型来处理输入数据,并获取输出结果,而不是对模型进行参数更新。
如何让模型具备专业知识?
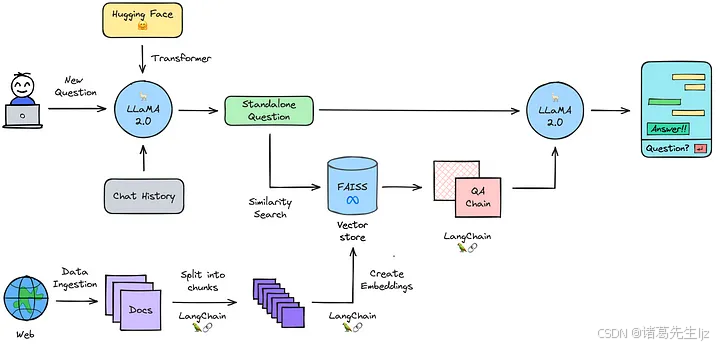
在推理过程中,我们通常结合 知识库检索(RAG),让大模型具备领域知识,而无需重新训练。
本次通过 LangChain 框架,实现了以下流程:
- 加载模型:从
Hugging Face下载Qwen2.5-7B模型,并加载到 GPU。 - 文本生成:使用
transformers.pipeline进行推理。 - 知识增强:
- 爬取网页数据(如 DeepSeek 官网内容),构建知识库。
- 文本切割:使用
RecursiveCharacterTextSplitter处理文本,使其适合索引。 - 生成 Embeddings:使用
HuggingFaceEmbeddings将文本转换为向量。 - 存入 FAISS 索引:建立高效的向量检索数据库。
- 对话检索链:通过
ConversationalRetrievalChain,让 LLM 结合知识库进行查询。
环境配置
在开始之前,请确保环境满足以下要求:
- Python 版本:3.10.16
- 依赖库安装:
pip install --no-cache-dir torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -U transformers accelerate huggingface_hub
pip install -U langchain langchain_huggingface
获取 Hugging Face Access Token
在使用 Hugging Face 模型时,需要进行身份认证,获取 access token。
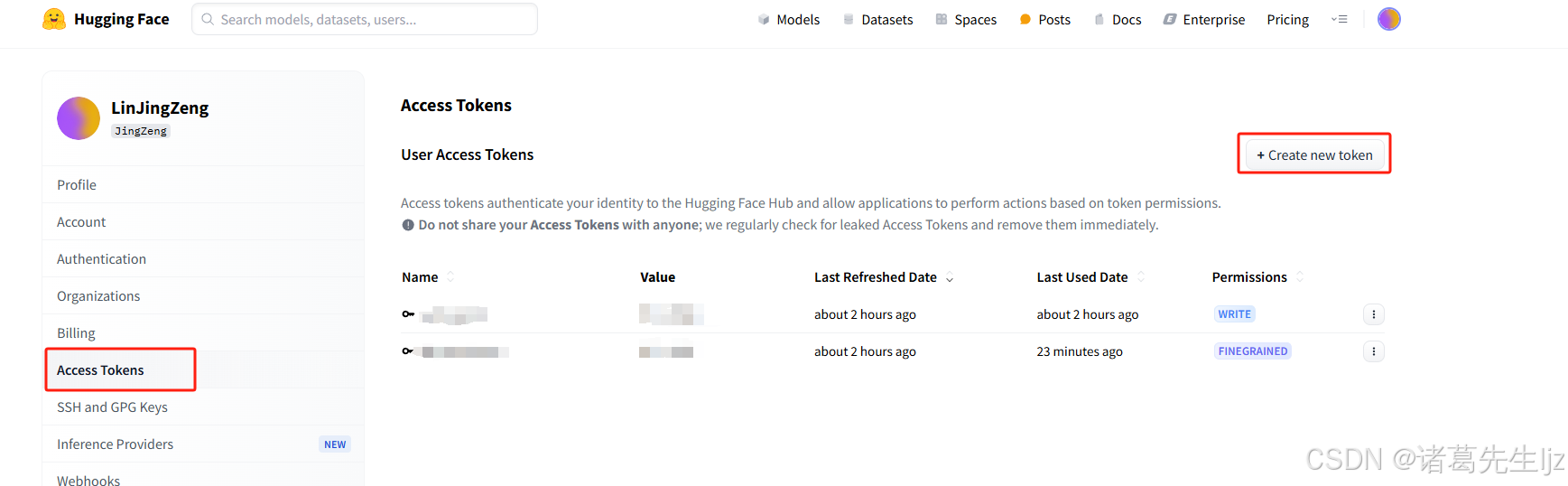
- 访问 Hugging Face 官网:https://huggingface.co
- 登录或注册账号。
- 进入 Settings 页面。
- 在 Access Tokens 部分,点击 New Token 按钮。
- 选择适当的权限(通常选择
read权限即可),然后创建 token。 - 复制生成的 token,并在代码中使用:
import os os.environ["HF_TOKEN"] = "your_huggingface_token_here"
代码核心实现
1. 加载模型
我们将 Qwen2.5-7B-Instruct-1M 加载到 GPU,并设置推理参数。
import os
import torch
import transformers
from transformers import StoppingCriteria, StoppingCriteriaList
# 确保 Hugging Face 认证
os.environ["HF_TOKEN"] = "your_huggingface_token"
# 选择模型
model_id = "Qwen/Qwen2.5-7B-Instruct-1M"
# 确保 GPU 可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载模型
torch_dtype = torch.float16 # 推荐 float16 以减少显存占用
model = transformers.AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch_dtype,
device_map="auto"
)
model.eval()
# 加载分词器
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
2. 定义停止条件
为了优化对话流畅性,我们定义一个 StoppingCriteria,确保生成文本在遇到特定的停止词时终止。
stop_list = ['\nHuman:', '\n```\n']
stop_token_ids = [tokenizer(x)["input_ids"] for x in stop_list]
stop_token_ids = [torch.tensor(x, dtype=torch.long, device=device) for x in stop_token_ids]
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
for stop_ids in stop_token_ids:
if input_ids.shape[1] >= len(stop_ids) and torch.all(input_ids[0, -len(stop_ids):] == stop_ids):
return True
return False
stopping_criteria = StoppingCriteriaList([StopOnTokens()])
3. 创建 pipeline 进行推理
使用 transformers.pipeline 创建生成文本的 pipeline,并测试一个简单的输入。
generate_text = transformers.pipeline(
task="text-generation",
model=model,
tokenizer=tokenizer,
return_full_text=True,
stopping_criteria=stopping_criteria,
temperature=0.1,
max_new_tokens=512,
repetition_penalty=1.1
)
res = generate_text("deepseek是什么")
print(res[0]["generated_text"])
4. 爬取网页数据并构建知识库
使用 LangChain 读取网页数据,并创建 FAISS 向量数据库。
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import ConversationalRetrievalChain
# 爬取网页数据
web_links = ["https://www.deepseek.com/"]
try:
loader = WebBaseLoader(web_links)
documents = loader.load()
except Exception as e:
print(f"WebBaseLoader 错误: {e}")
documents = []
# 文本切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
all_splits = text_splitter.split_documents(documents)
# 加载 Embeddings
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs={"device": device})
# 构建 FAISS 索引
vectorstore = FAISS.from_documents(all_splits, embeddings)
5. 创建对话检索链
我们将 generate_text 适配到 LangChain,并结合 FAISS 索引实现知识检索。
from langchain_huggingface import HuggingFacePipeline
# 创建 LLM 接口
llm = HuggingFacePipeline(pipeline=generate_text)
# 创建对话检索链
chain = ConversationalRetrievalChain.from_llm(
llm, retriever=vectorstore.as_retriever(), return_source_documents=True
)
# 进行查询
chat_history = []
query = "deepseek是什么"
result = chain.invoke({"question": query, "chat_history": chat_history})
# 输出结果
print(result["answer"])
总结
- 直接训练 LLM 需要高昂的计算资源,通常不适用于实际开发。
- 采用推理结合 RAG(知识增强)的方法,可以让模型回答特定领域的问题。
- 通过爬取网页等方式构建向量数据库(FAISS),我们可以动态扩展模型的知识范围。
- 这种方法适用于问答机器人、知识管理系统等场景,能够提供更符合业务需求的回答。
这种方式不仅高效,而且成本远低于重新训练一个大模型。如果你有更深层次的需求,也可以尝试 Fine-tuning,但一般情况下,推理 + RAG 已经能解决大部分问题。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









