







摘要
在超过十年的研究中,人们一直在探索如何有效地利用循环模型和注意力机制。循环模型旨在将数据压缩到固定大小的内存(称为隐藏状态),而注意力允许关注整个上下文窗口,捕捉所有标记之间的直接依赖关系。然而,这种对依赖关系更准确的建模伴随着二次成本,限制了模型的上下文长度。我们提出了一种新的神经长期记忆模块,能够学习记忆历史上下文,并帮助注意力在利用长期过去信息的同时关注当前上下文。我们表明,这种神经记忆具有快速并行训练的优势,同时保持快速推理。从记忆的角度来看,我们认为由于其有限的上下文但准确的依赖关系建模,注意力表现为短期记忆,而神经记忆由于其记忆数据的能力,表现为更持久的长期记忆。基于这两个模块,我们引入了一组新的架构,称为Titans,并介绍了三种变体,以解决如何有效地将记忆整合到架构中的问题。我们在语言建模、常识推理、基因组学和时间序列任务上的实验结果表明,Titans比Transformer和最近的现代线性循环模型更有效。它们还可以有效地扩展到超过200万的上下文窗口大小,并在与基线相比的“针在草堆”任务中表现出更高的准确性。
该篇文章的研究目的
-
探索记忆机制的改进:文章旨在通过设计新型记忆模块,克服现有Transformer和循环神经网络(RNN)的局限性,特别是处理长序列时的效率和效果问题。
-
提出高效记忆架构:目标是开发一种能够结合短期记忆和长期记忆优势的神经网络架构,以实现更高效、更有效的长序列数据处理。
-
验证模型的优越性:通过一系列实验,证明所提出的模型在长序列任务中相比现有模型具有更高的准确性和更强的扩展能力,尤其是在处理极长的上下文窗口时。
该篇文章的研究方法
短期记忆与长期记忆结合
-
短期记忆模拟:通过有限窗口大小的注意力机制模拟短期记忆,专注于处理当前上下文窗口内的信息。
-
长期记忆设计:提出一种神经长期记忆模块,利用梯度下降、动量和权重衰减机制更新记忆,将数据的抽象编码到模型参数中,实现对长期历史信息的有效存储和检索,并引入遗忘机制防止记忆溢出。
模型架构设计
-
Titans架构:构建包含核心模块(短期记忆)、长期记忆模块和持久记忆模块的Titans架构,探索三种变体(记忆作为上下文、门控和层)以高效整合记忆模块。
-
记忆更新与检索:使用基于惊讶度量的机制更新记忆,并通过前向传播检索与查询相关的信息,以指导模型关注重要信息。
并行化训练
-
高效训练算法:通过张量化操作和矩阵乘法优化记忆模块的训练过程,实现高效并行化训练,提高训练速度。
该篇文章的研究内容
记忆模块的创新设计
-
惊讶度量与记忆更新:将输入数据的惊讶程度作为记忆更新的依据,通过梯度衡量输入的意外性,并结合动量项考虑历史信息的影响,实现更精细化的记忆管理。
-
遗忘机制的引入:借鉴现代循环模型的遗忘门机制,设计数据依赖的遗忘机制,动态调整记忆的保留与遗忘,避免记忆饱和,提高模型的适应性。
Titans架构
在设计神经长期记忆之后,一个重要的剩余问题是如何有效地将记忆整合到深度学习架构中。我们提出了Titans,一组深度模型,包含三个超头:
(1)核心:这个模块包含短期记忆,负责处理数据的主要流程(我们使用有限窗口大小的注意力);
(2)长期记忆:这个分支是我们的神经长期记忆模块,负责存储/记住长期过去;
(3)持久记忆:这是一组可学习的但与数据无关的参数,编码关于任务的知识。最后,作为概念验证,我们提出了Titans的三种变体,其中将记忆整合为:(i)上下文,(ii)层,和(iii)门控分支。
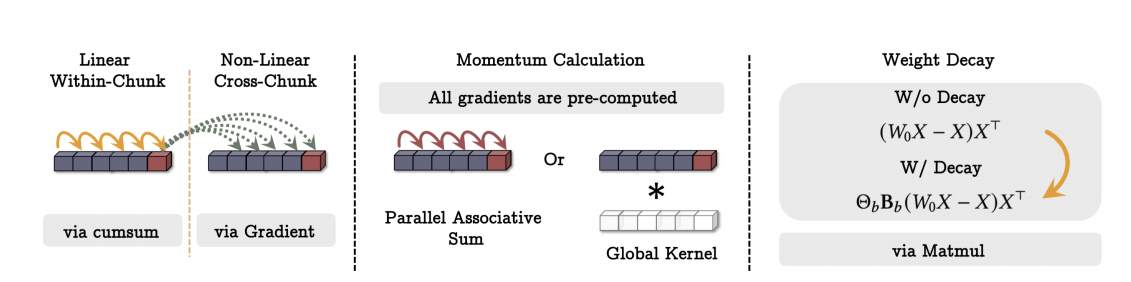
神经记忆训练的并行化方式说明
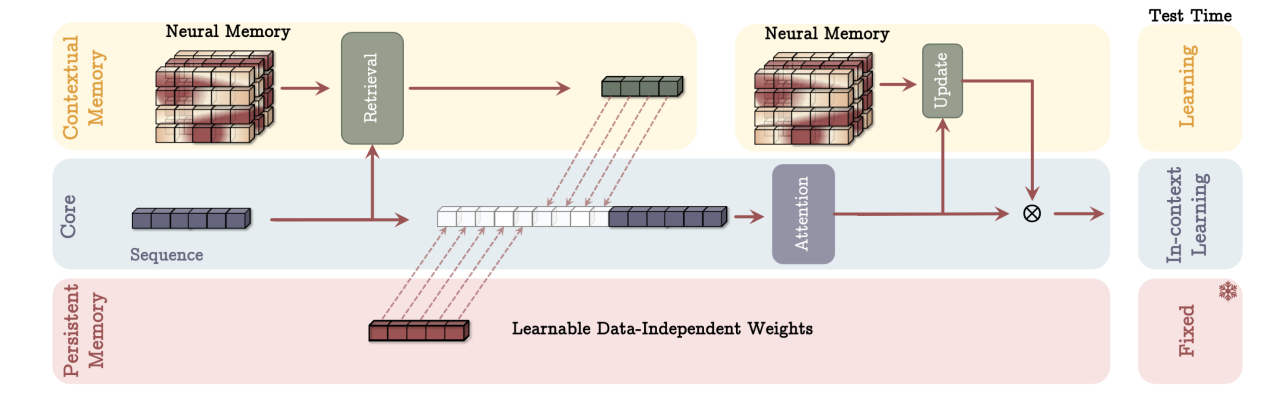
记忆作为上下文(MAC)架构。该架构包含三个分支:核心分支、上下文(长期)记忆分支和持久记忆分支。核心分支将相应的长期记忆和持久记忆与输入序列拼接。注意力在序列上运行,决定哪些信息应存储在长期记忆中。在测试时,对应于上下文记忆的参数仍在学习,核心分支的参数负责上下文内学习,而持久记忆分支的参数负责存储任务相关知识,因此保持不变。
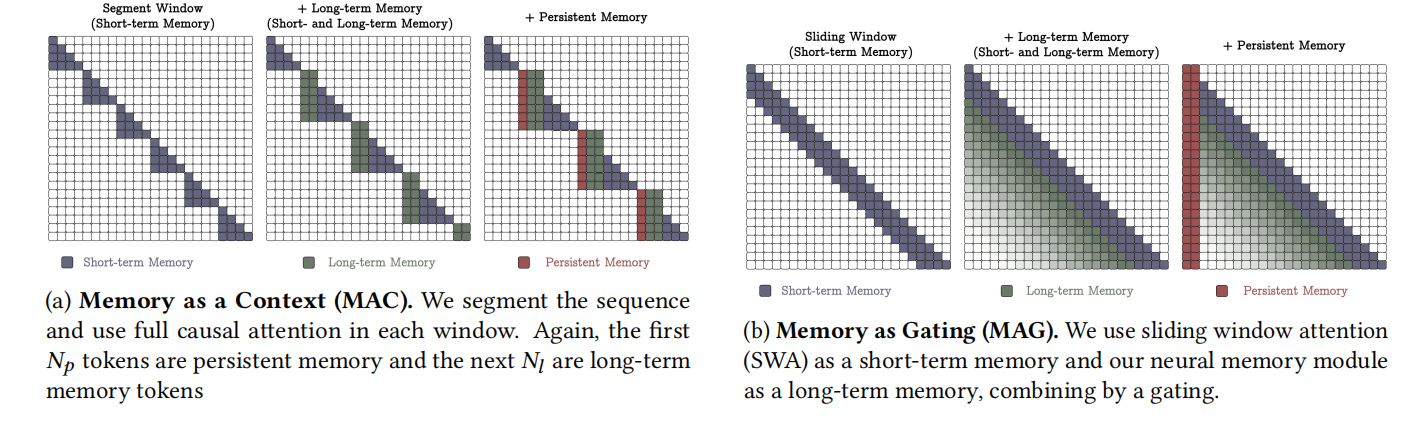
Titans不同变体的注意力掩码。(a)记忆作为上下文(MAC)。(b)记忆作为门控(MAG)。图中展示了滑动窗口注意力(SWA)和长期记忆的结合方式。
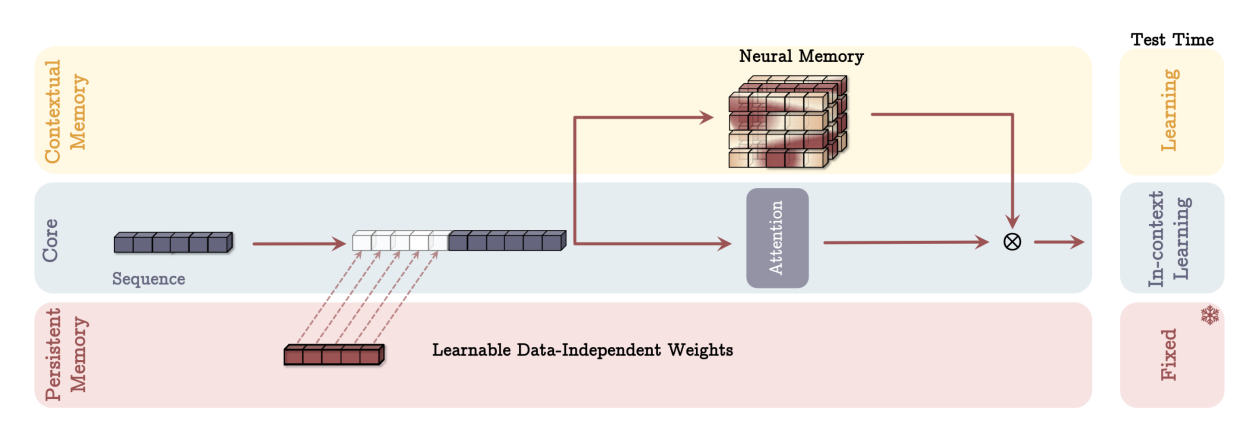 记忆作为门控(MAG)架构。与图2类似,但仅将持久记忆整合到上下文中,并通过门控机制将记忆与核心分支结合。在测试时,行为与图2相同。
记忆作为门控(MAG)架构。与图2类似,但仅将持久记忆整合到上下文中,并通过门控机制将记忆与核心分支结合。在测试时,行为与图2相同。
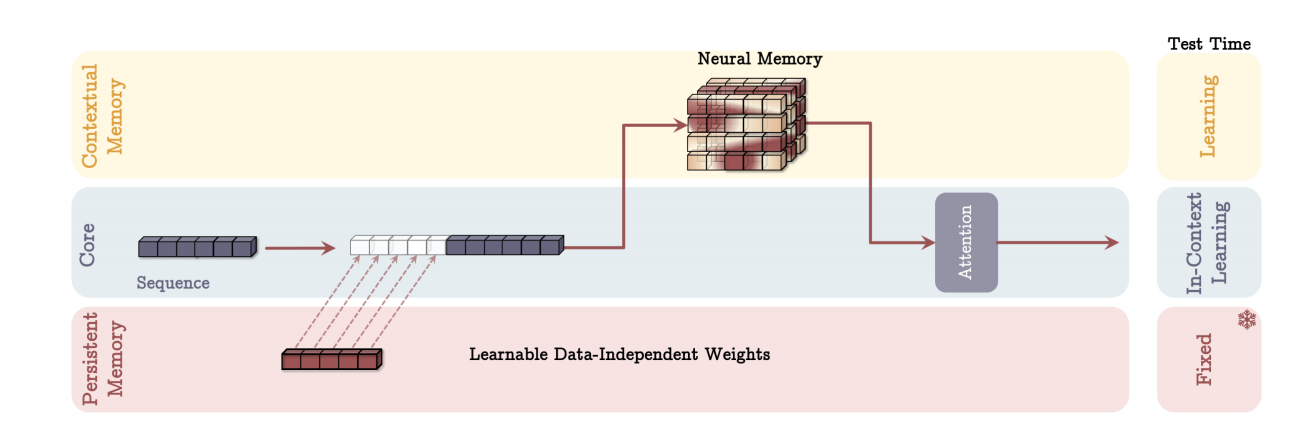
记忆作为层(MAL)架构。记忆层负责在注意力模块之前压缩过去和当前上下文。
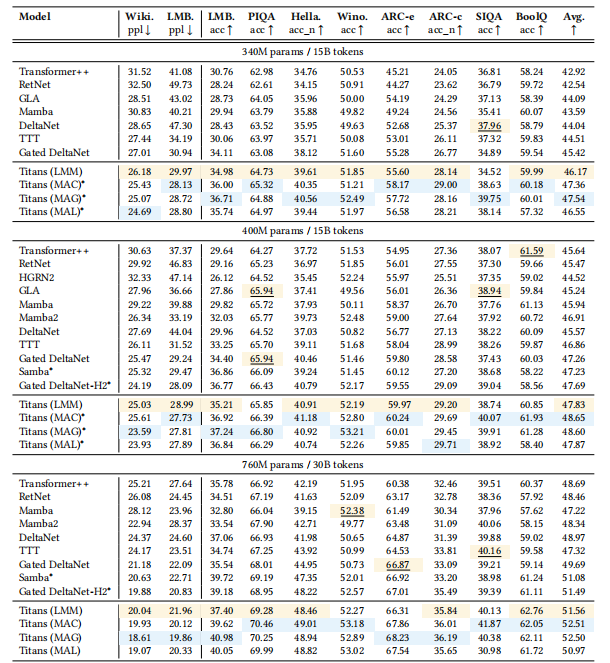
在语言建模和常识推理任务上,Titans及其变体与基线模型的性能对比。
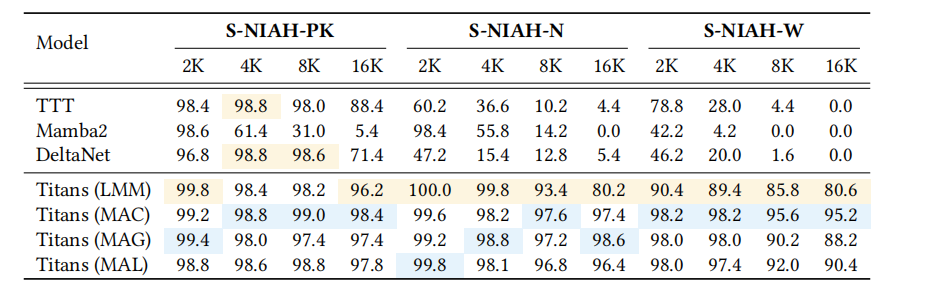
在单针搜索(S-NIAH)任务中,Titans及其变体与基线模型的性能对比。
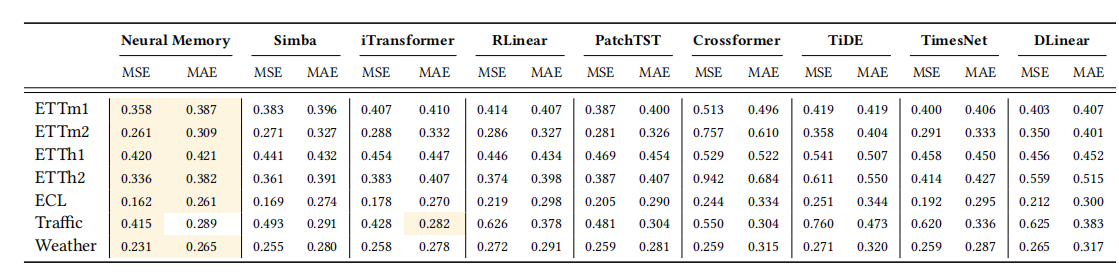 在时间序列预测任务上,神经记忆模块与基线模型的性能对比。
在时间序列预测任务上,神经记忆模块与基线模型的性能对比。
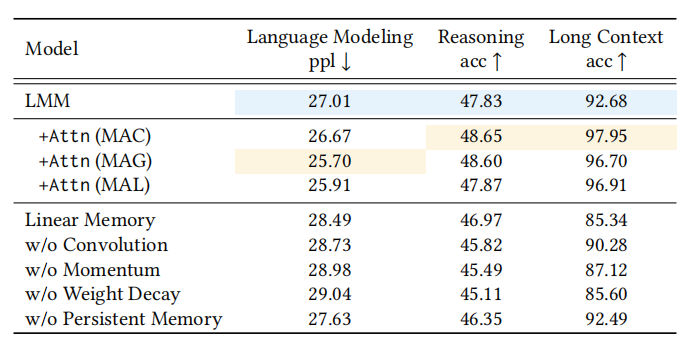
Titans架构的消融研究结果,展示了不同组件对模型性能的影响。
该篇文章的最大创新点
记忆机制的革新
-
首次提出结合短期与长期记忆的架构:创新性地将短期记忆(注意力机制)与长期记忆(神经长期记忆模块)相结合,形成互补的记忆系统,既捕捉当前上下文的细节,又保留长期历史信息的摘要。
-
动态记忆管理:引入基于惊讶度量的动态记忆更新和遗忘机制,使模型能够主动学习和适应数据的分布变化,有效管理有限的记忆资源。
模型架构的创新
-
多变体架构设计:提出Titans架构的三种变体,分别为记忆作为上下文、门控和层的整合方式,为不同任务和需求提供灵活的架构选择。
-
高效并行训练算法:通过张量化操作优化记忆模块的训练,使其能够在保持高效训练的同时扩展到极长的序列长度,显著提高训练和推理速度。
理论与实验的双重支持
-
理论分析:从记忆和学习的角度深入分析模型的结构和机制,为模型设计提供理论依据。
-
实验验证:通过广泛的实验验证了模型在多个领域的优越性能,特别是在长序列任务中的扩展能力和准确性提升,证明了模型设计的有效性。
该篇文章给我们的启发
记忆机制的重要性
-
强调记忆的多维度:文章提醒我们,记忆不仅是简单的数据存储,还涉及信息的筛选、更新和遗忘,这对于模型处理复杂任务和长序列数据至关重要。
-
启发未来记忆模块设计:未来的研究可以进一步探索如何根据不同的任务需求设计更精细的记忆管理策略,例如动态调整记忆容量、优化记忆检索方式等。
模型架构的灵活性
-
模块化设计的优势:Titans架构的多变体设计展示了模块化架构的灵活性和优势,提示我们在构建复杂模型时可以考虑多种组件的组合方式,以适应不同的应用场景。
-
促进跨领域应用:文章证明了所提出的记忆模块在多个领域的有效性,鼓励研究人员将类似的记忆增强机制应用于其他领域,如医疗保健、金融预测等,以解决长序列数据处理的挑战。
效率与效果的平衡
-
关注计算资源优化:文章通过高效的并行训练算法实现了模型在长序列上的快速处理,提醒我们在追求模型性能提升的同时,也要关注计算资源的优化和利用。
-
推动大规模模型部署:为大规模模型的部署和应用提供了新的思路,特别是在需要处理大量长序列数据的场景中,如何在保持高性能的同时降低计算成本是一个值得深入研究的方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









