







LLaMA-Factory 简介
LLaMA-Factory 是一个强大的深度学习模型训练和微调平台,支持多种先进的语言模型,如 LLaMA、LLaVA、Mistral、ChatGLM 等。该工具不仅支持传统的语言模型训练,还集成了多种前沿技术和算法,旨在帮助开发者高效构建和优化模型。
主要特性
- 多样化模型支持:可以训练的模型包括 Baichuan、BLOOM、ChatGLM3、Llama 以及更多主流和新兴模型,覆盖从小型到超大规模的多种选择。
- 集成方法:支持持续预训练、多模态监督微调、奖励建模等多种训练方法,为模型的提升提供灵活选择。
- 可扩展资源:提供 16-bit 完全微调、冻结微调、LoRA 等多种调优方式,兼容 QLoRA 的多种比特位选项。
- 先进算法:实现了 GaLore、BAdaM、LongLoRA 等优化算法,提升训练效率和效果。
- 实用技巧:集成 FlashAttention-2、Liger Kernel 等技术,显著加速训练过程。
- 实验监控:通过 LlamaBoard、TensorBoard、Wandb 和 MLflow 等工具,实时监控实验进展。
- 快速推理:提供 OpenAI 风格的 API、Gradio UI 和 CLI,结合 vLLM worker 提高推理速度。
安装 LLaMA-Factory
要安装 LLaMA-Factory,请按照以下步骤操作:
- 克隆源码:使用 Git 克隆 LLaMA-Factory 的最新版本。
- 创建 Conda 环境:创建一个新的 Conda 环境,以确保项目依赖不会与其他项目冲突。
- 激活环境:激活刚创建的 Conda 环境。
- 进入项目目录:切换到 LLaMA-Factory 项目的目录。
- 安装依赖:安装项目所需的依赖项,包括 PyTorch 和其他必要的库。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e ".[torch,metrics,qwen]" -i https://mirrors.aliyun.com/pypi/simple/
#清华大学镜像:https://pypi.tuna.tsinghua.edu.cn/simple
#阿里云镜像:https://mirrors.aliyun.com/pypi/simple/可用的额外依赖项
LLaMA-Factory 还支持多种额外依赖项,以扩展其功能和性能:
- torch:PyTorch库,用于深度学习和张量计算。
- torch-npu:华为Ascend NPU的PyTorch扩展,优化深度学习训练。
- metrics:用于评估模型性能的库。
- deepspeed:用于大规模模型训练的优化库。
- liger-kernel:高性能计算内核,用于加速训练过程。
- bitsandbytes:用于模型量化和内存管理的库。
- hqq:特定工具,具体用途需确认。
- eetq:特定模型优化或训练工具,具体信息需查找。
- gptq:量化GPT模型的工具。
- awq:特定量化方法或工具,具体信息需确认。
- aqlm:针对量化语言模型的库。
- vllm:优化大规模语言模型推理的库。
- galore:与模型训练、优化或数据处理相关的工具。
- badam:特定的优化算法或框架,具体信息需查找。
- adam-mini:Adam优化算法的简化版本。
- qwen:特定模型或优化工具。
- modelscope:提供预训练模型和框架的库。
- openmind:与开源深度学习框架或工具集相关。
- quality:用于评估模型质量的工具或库。
防火墙配置与启动微调
在使用 LLaMA-Factory 进行微调时,确保防火墙开放 7860 端口,以便访问 GUI 界面。可以使用以下命令进行配置:
# 7860是LLaMA Board GUI的端口,需要开放
sudo firewall-cmd --zone=public --add-port=7860/tcp --permanent
sudo firewall-cmd --reload
# 启动微调
llamafactory-cli webui

LLaMA-Factory微调模型
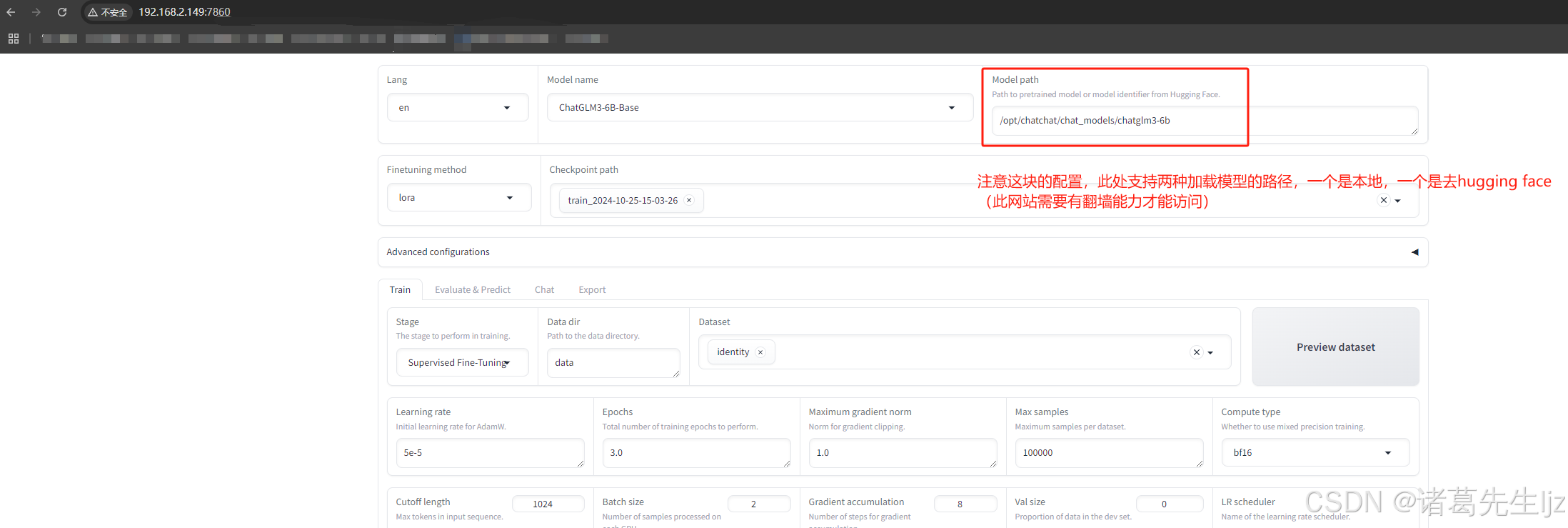
在成功安装 LLaMA-Factory 后,就可以通过 LLaMA Board GUI 进行模型微调。以下是微调的基本过程以及配置说明:
-
选择模型: 在 GUI 中,选择要微调的模型。LLaMA-Factory 支持多种模型,可以根据需求选择相应的模型。
-
配置微调参数: 在微调界面中,可以设置多种参数,常见的配置包括:
- 学习率(Learning Rate):设置模型更新的步长,通常建议从较小的值开始,例如
1e-5,根据实际情况逐步调整。 - 批次大小(Batch Size):选择每次训练迭代的数据量。较大的批次大小可能需要更多的显存,建议从小值开始,如
8或16。 - 训练轮次(Epochs):设置微调的轮次,根据数据集大小和模型复杂性选择合适的轮次,通常为
3到10。 - 优化器(Optimizer):选择用于训练的优化算法,如 Adam、SGD 等。
- 学习率(Learning Rate):设置模型更新的步长,通常建议从较小的值开始,例如
-
数据集准备: 上传或指定用于微调的数据集。数据集应经过适当格式化,确保与选定模型的输入要求相匹配。
-
监控与日志: 在微调过程中,可以通过 GUI 实时监控训练进度,查看损失函数(Loss)、准确率(Accuracy)等指标。可以将训练日志导出,便于后续分析。
-
保存与导出模型: 微调完成后,用户可以选择将训练好的模型保存到指定目录:
- 在 GUI 中找到“保存模型”或“导出模型”的选项。
- 选择保存路径,并命名模型文件。
- 确认导出设置后,点击“保存”按钮,完成导出。
确保记录微调的参数,以便在未来进行复现。
-
模型评估: 微调后,使用测试集对模型进行评估,查看模型性能,并根据需要进行进一步调整。
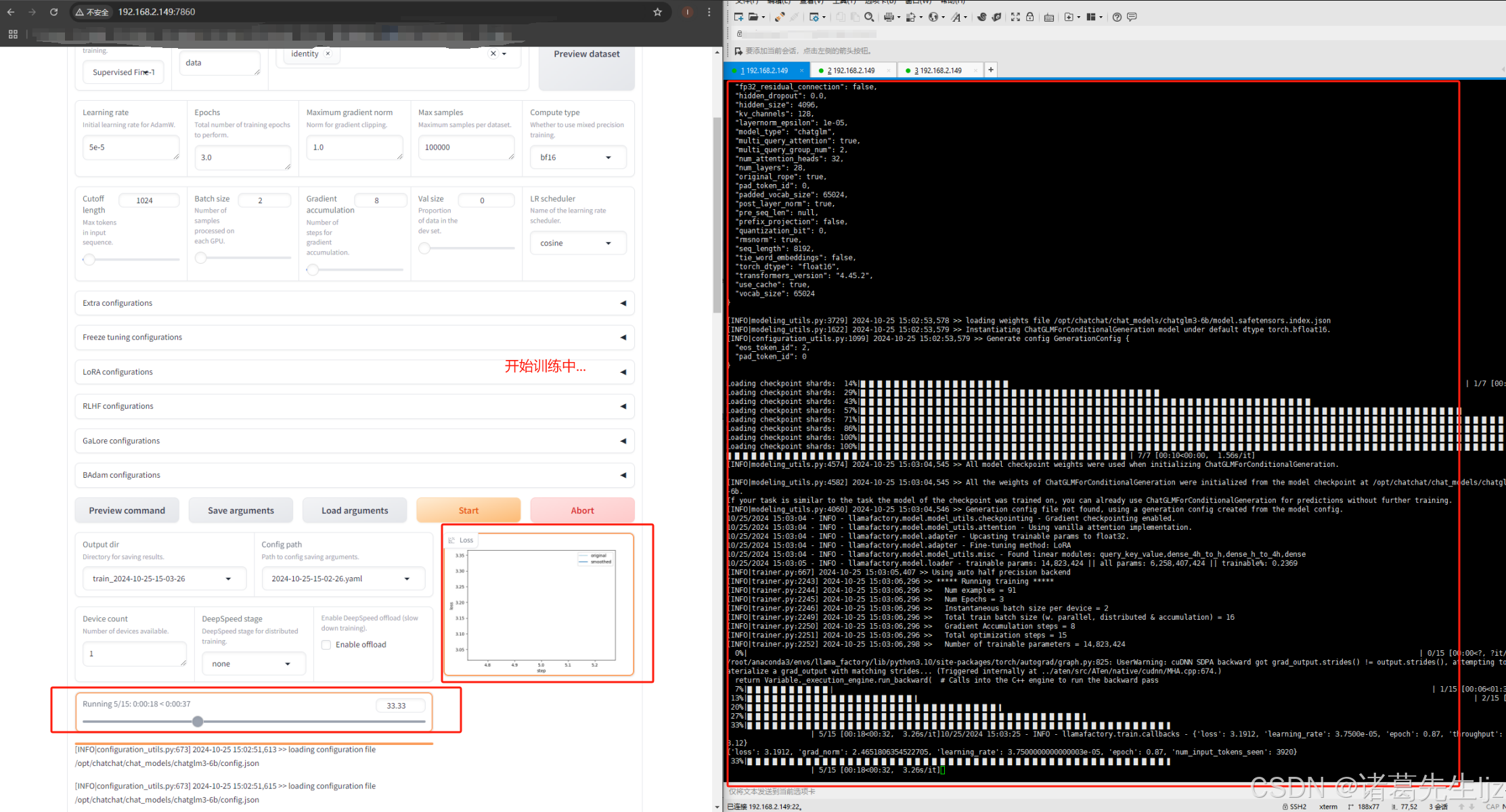
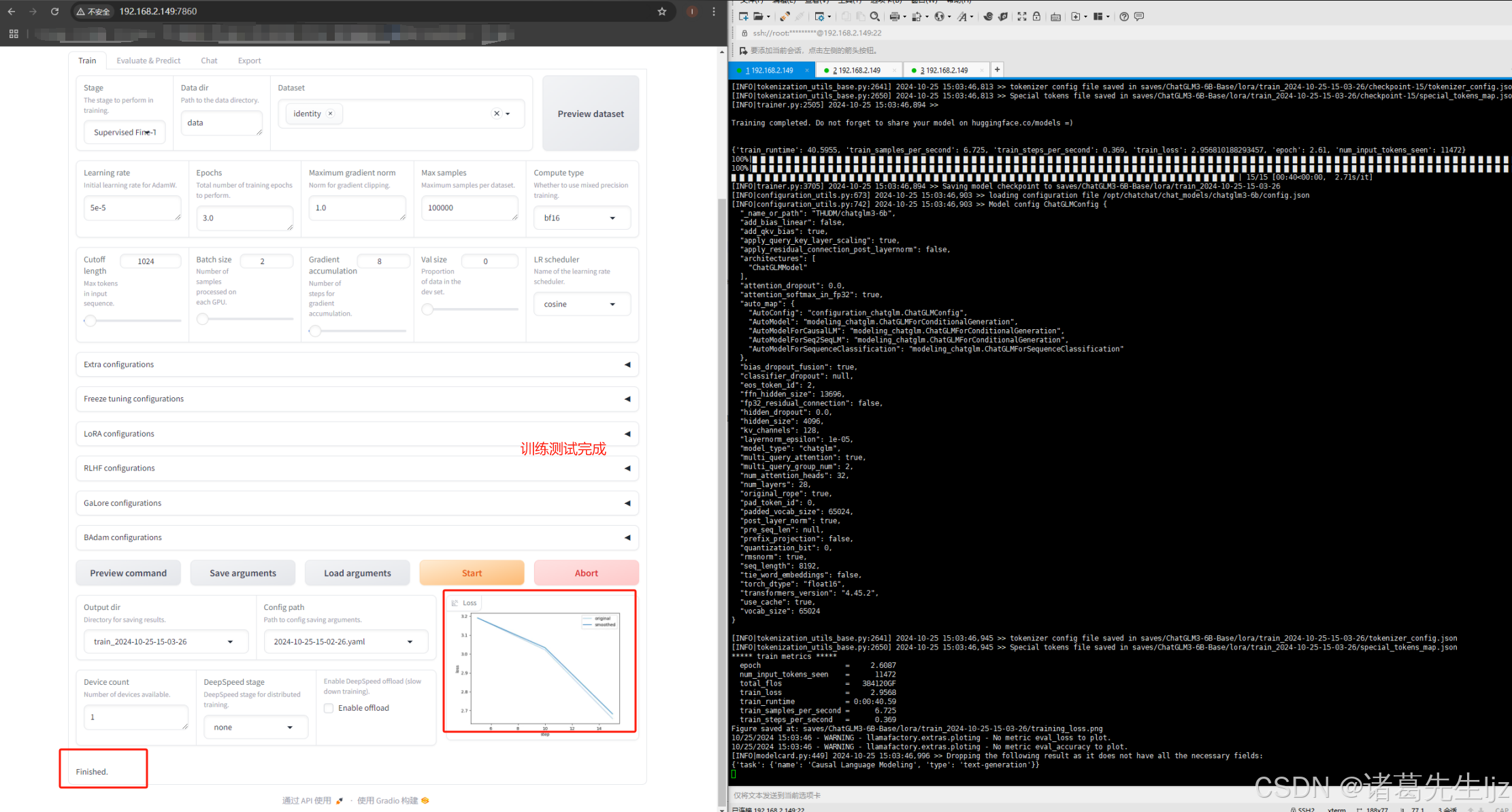
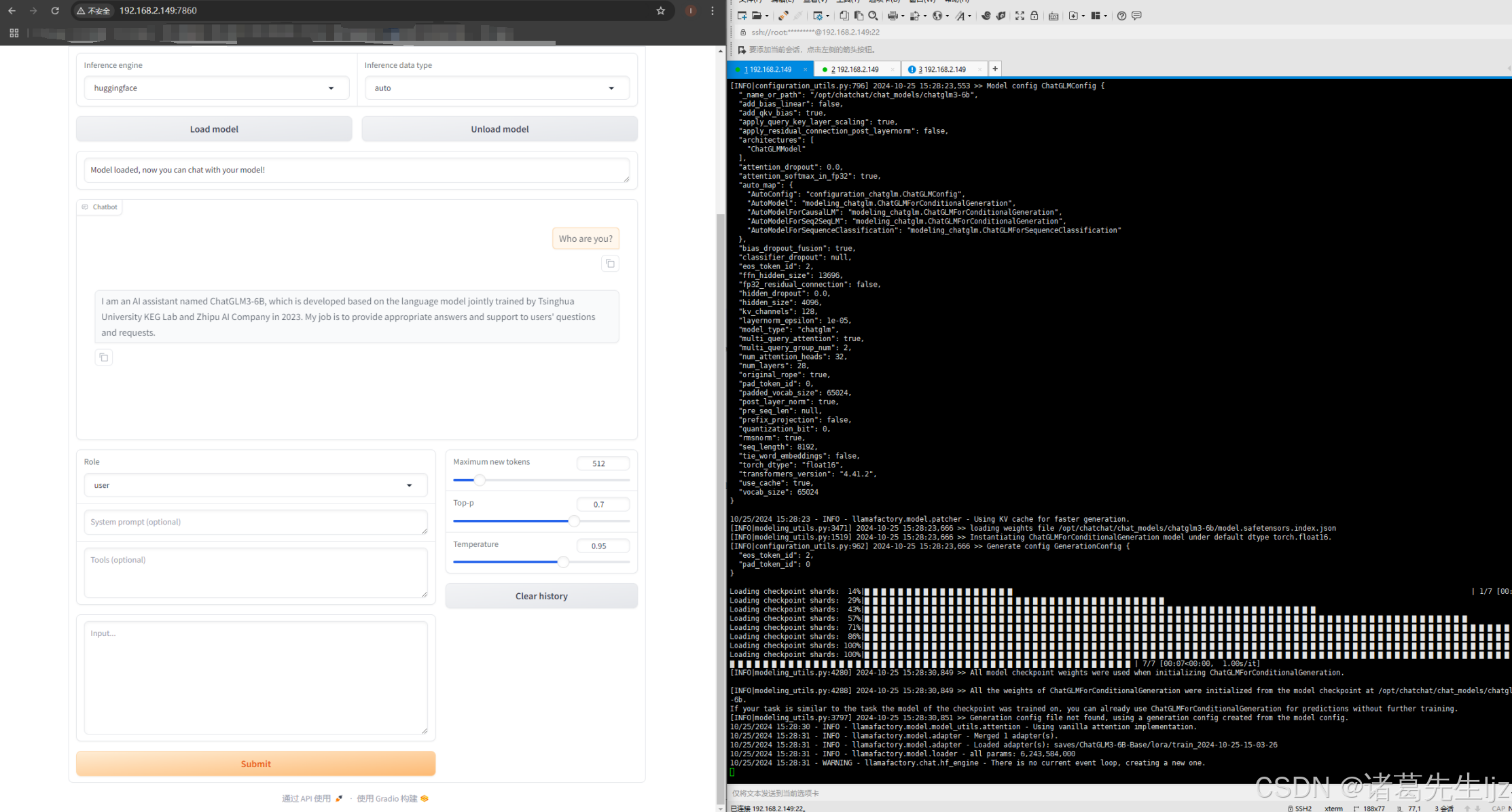
模型对话验证
加载训练后的模型进行对话验证:
遇到的问题
问题1:OSError: We couldn't connect to 'https://huggingface.co' to load this file
原因:无法连接到 Hugging Face 网站,且找不到缓存文件,导致无法加载模型配置。该网站需要翻墙。
解决方案:使用本地模型替代,运行以下命令克隆模型:
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git问题2:在过程中由于服务器只装了NVIDIA 驱动,却未安装CUDA,导致异常出现。
解决方案:运行 nvidia-smi 检查版本,若需要下载 CUDA Toolkit,执行以下命令进行安装:
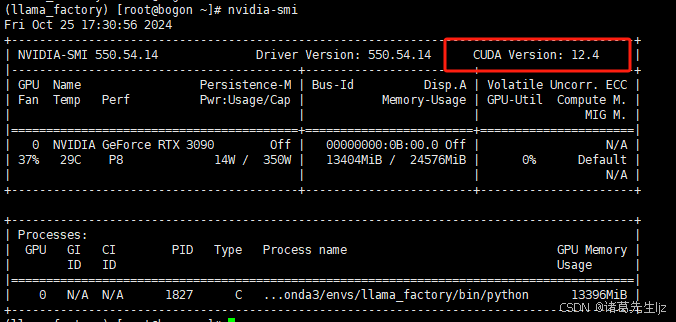
cuda历史版本下载地址:https://developer.nvidia.com/cuda-toolkit-archive
sudo rpm --install https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda-repo-rhel7-12-4-local-12.4.0_550.54.14-1.x86_64.rpm
# 安装CUDA Toolkit更新仓库并安装CUDA:
sudo yum clean expire-cache
sudo yum install cuda
#设置环境变量,安装完成后,添加CUDA的路径到环境变量中。编辑~/.bashrc或~/.bash_profile文件,添加以下行:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# 然后使改动生效:
source ~/.bashrc
#重启计算机后,验证CUDA是否安装成功:
nvcc --version问题3:TypeError: GenerationMixin._extract_past_from_model_output() got an unexpected keyword argument 'standardize_cache_format'
原因:所用的模型(如 ChatGLM3-6B)与当前的 Transformers 库版本不兼容。
解决方案:降级 Transformers 库到 4.41.2,运行以下命令:
pip install transformers==4.41.2 -i https://mirrors.aliyun.com/pypi/simple/参考官方资源
- GitHub 源码路径:LLaMA-Factory GitHub
- 官方参考文档:LLaMA-Factory 文档


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









