






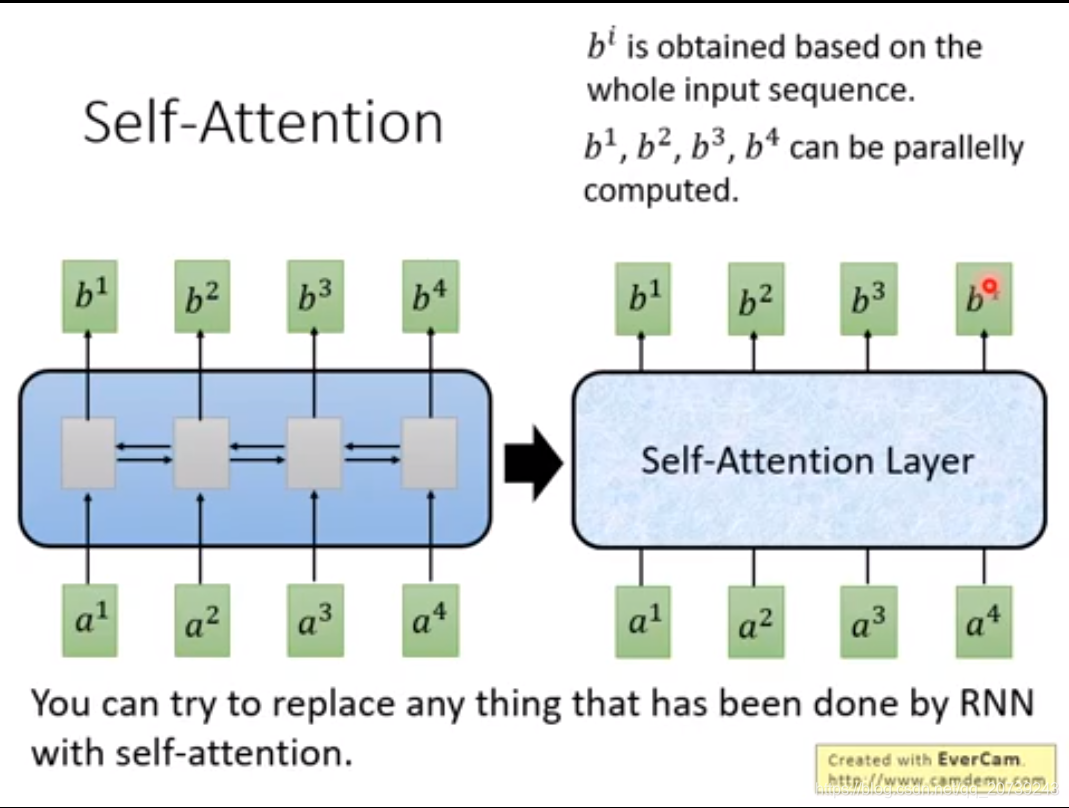
RNN不容易被平行化,先计算得到b1,再计算得到b2,再b3,再b4
Self-attention输入和输出也和RNN一样都是sequence,每一个输出和Bi-RNN一样,都由所有的输入序列得到。但是不同之处在于输出是同时得到的,不需要再按照顺序得到。
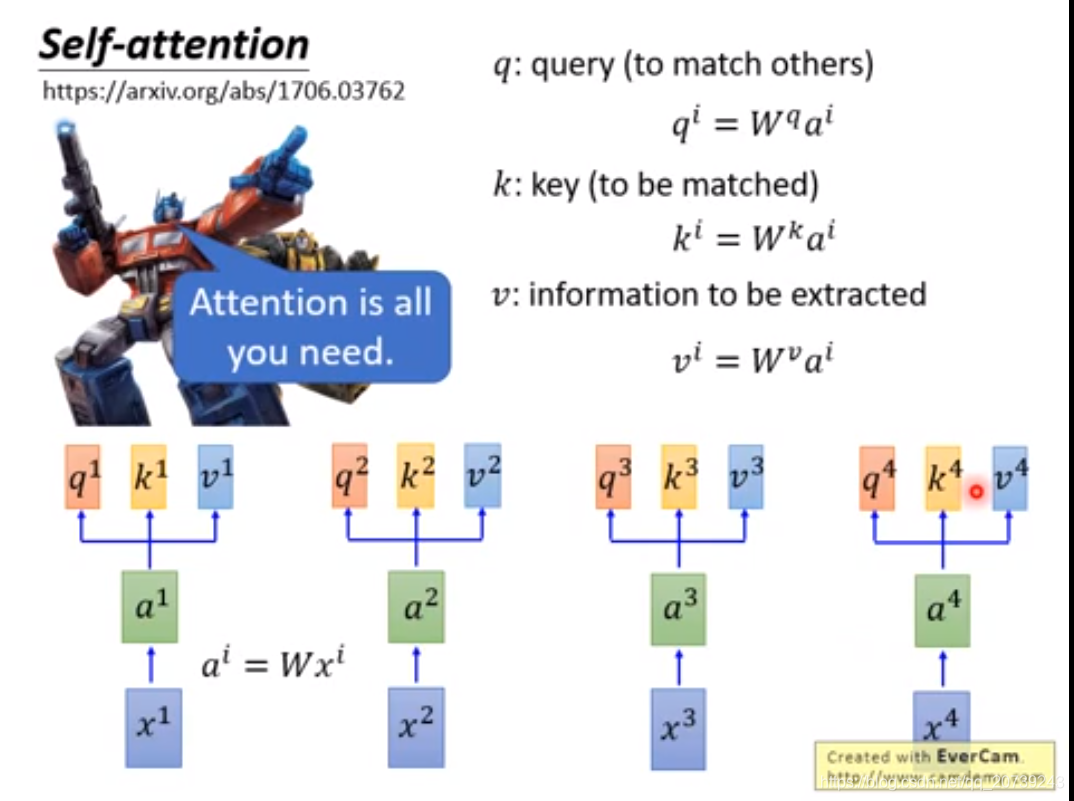
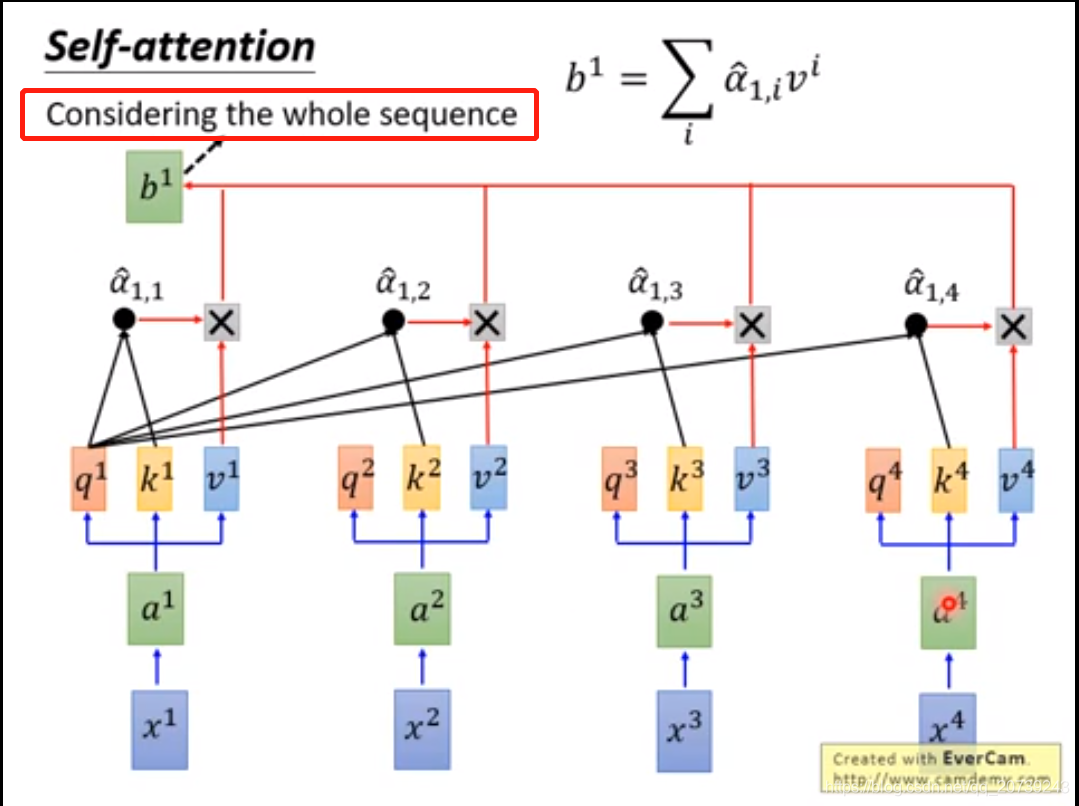
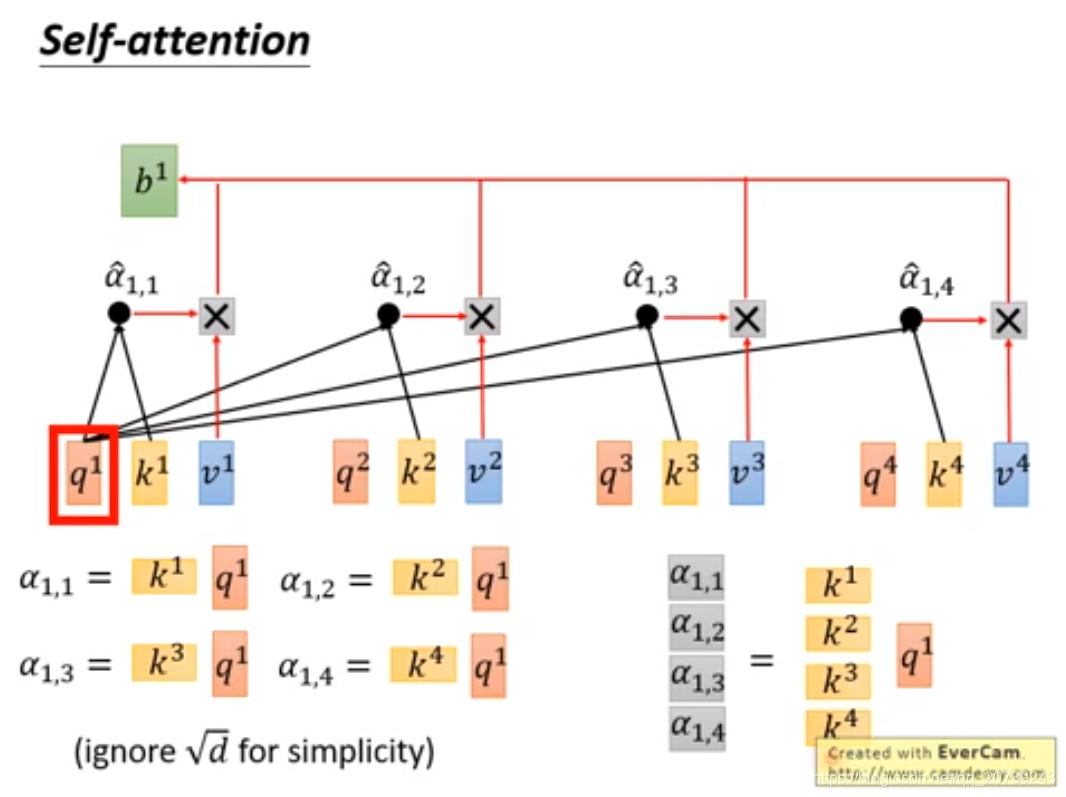
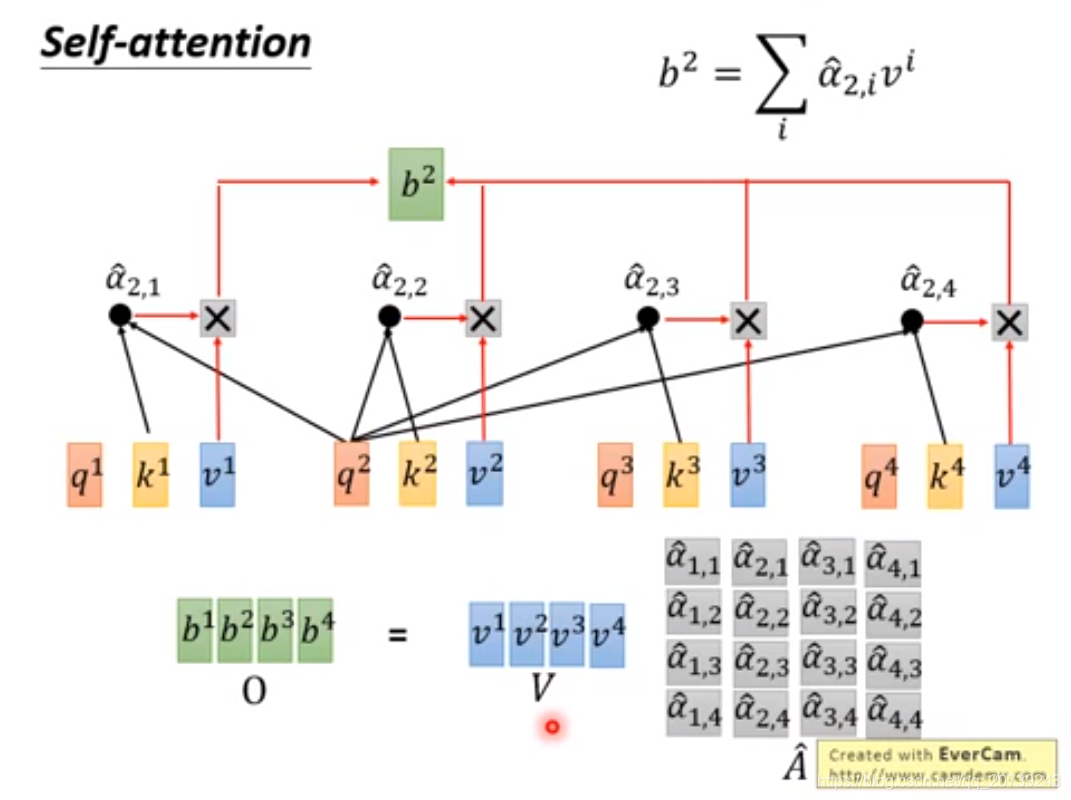
每一个q和所有k做一次attention得到对应的值。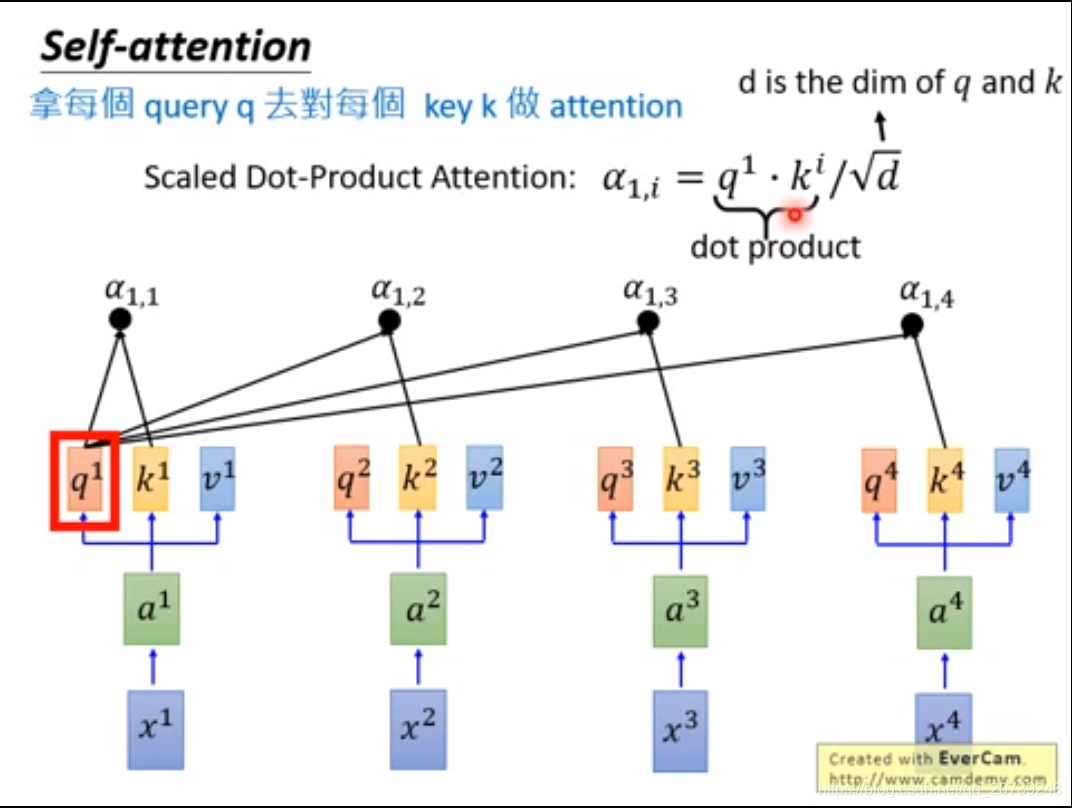
把值经过softmax:
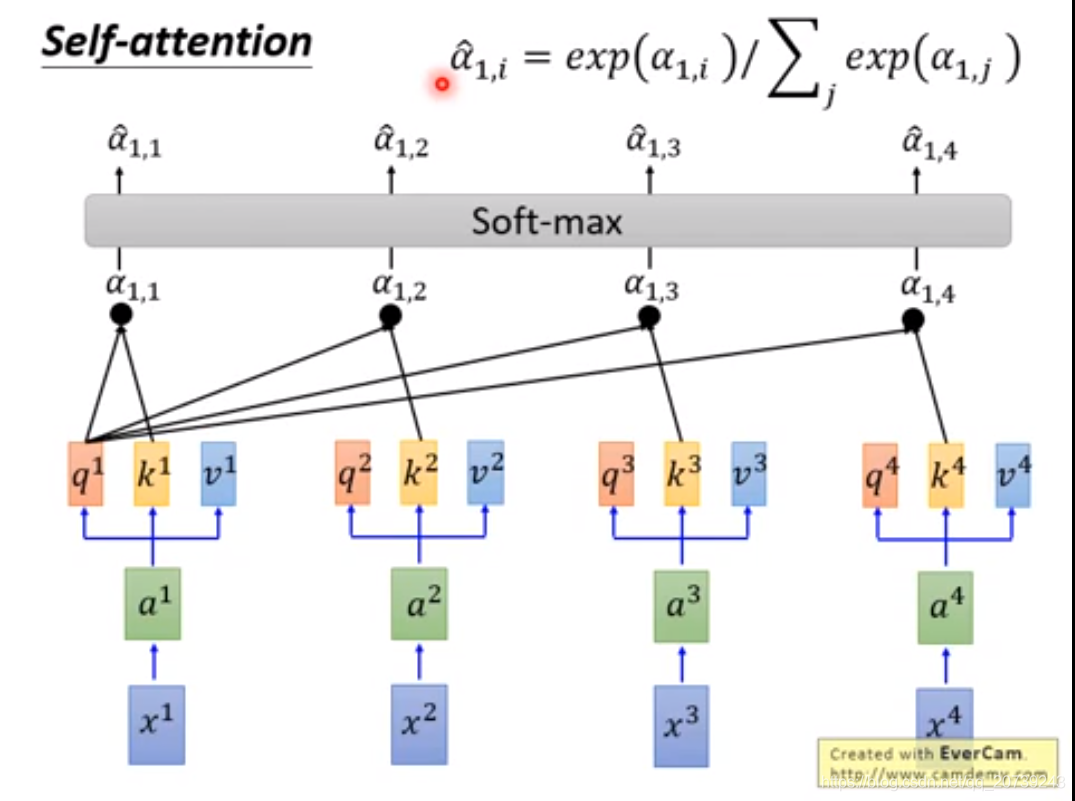
得到α^与对应的v相乘,再累加得到b,可以看到b是把所有的输入值都利用到了。
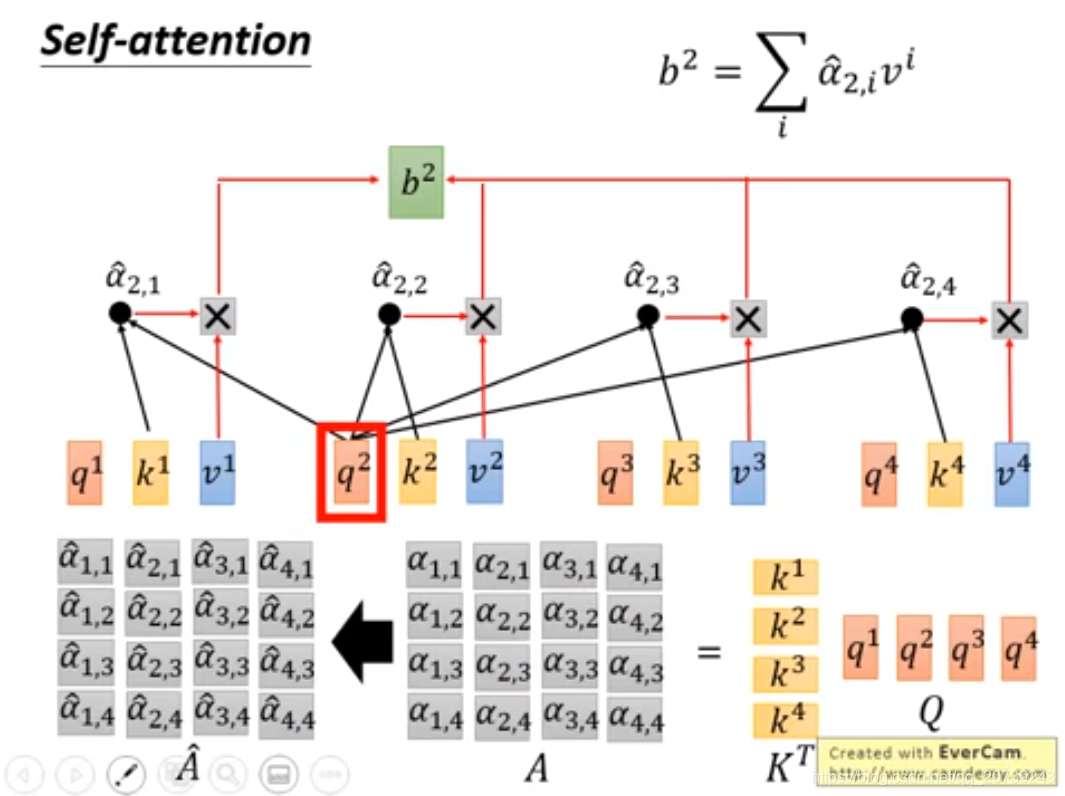
要得到b2:只需要用q2与每一个k做乘积:

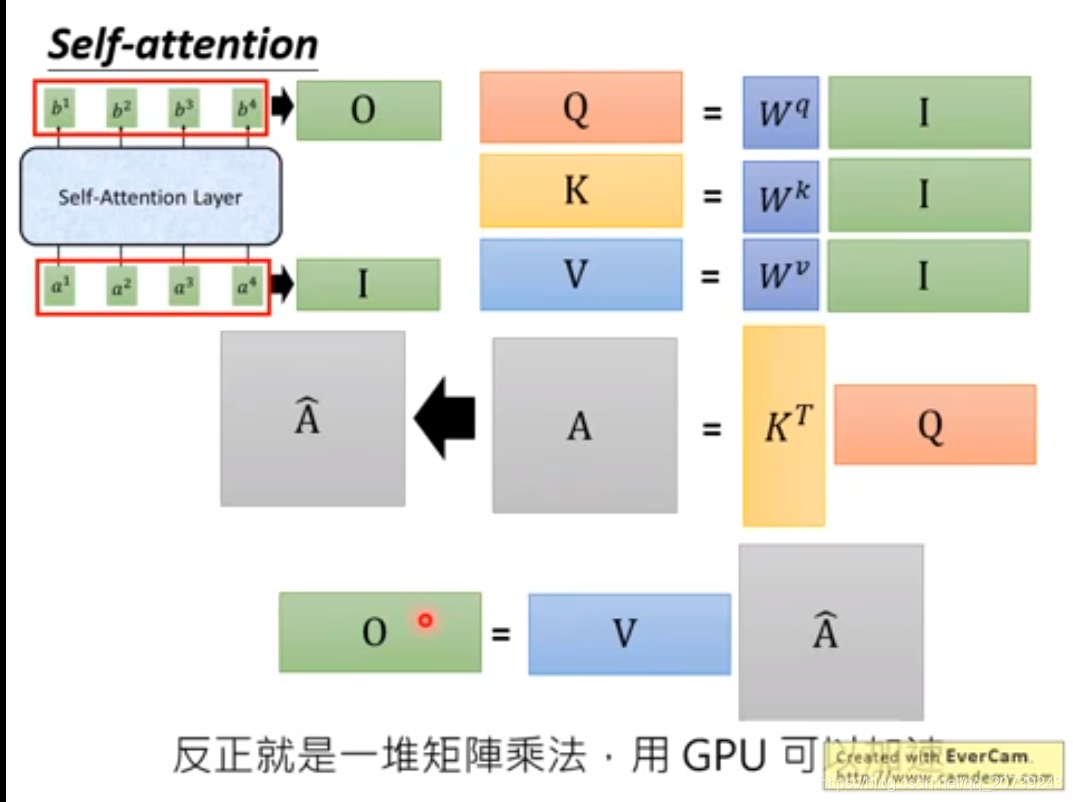
矩阵表示:
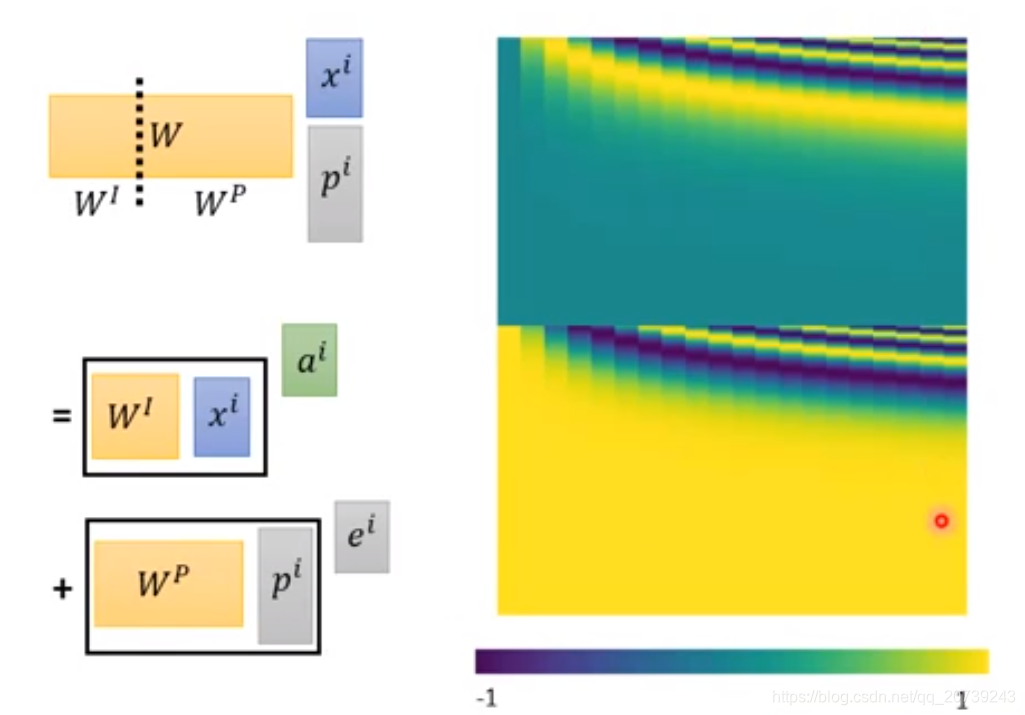
但是这个网络没有关于输入的位置信息,它不考虑哪一个和它更近,哪一个更远。所以在得到的ai还要加上一个代表位置信息的值ei

等同于是我把xi后面接一个pi,pi代表目前的xi处于哪个位置:

但是Wp是手动设置的:
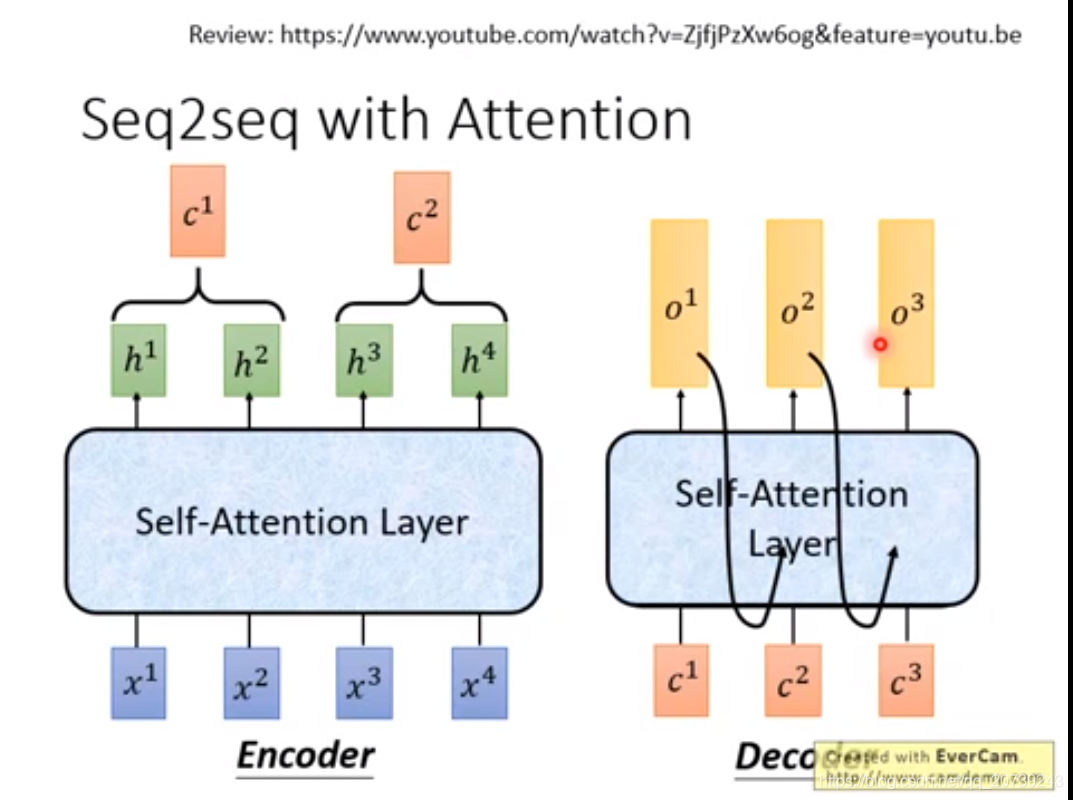
对于Seq2seq我们是直接把里面的RNN部分给取代掉,都变成self-attention:
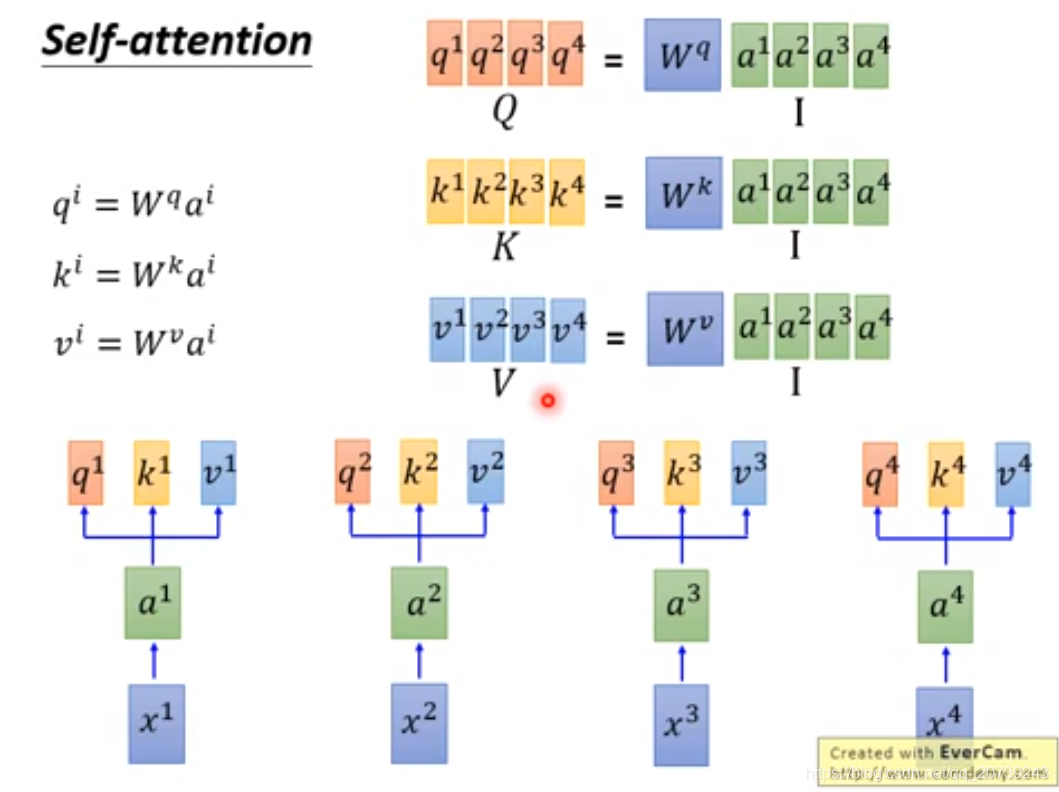
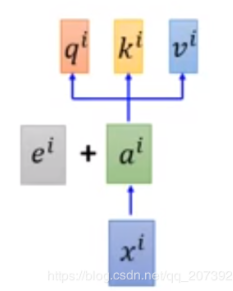
首先第一步:每一个词的输入xi被编码为词向量ai,加上其位置信息ei,得到的向量乘上不同的权值W得到三个被称为查询向量、键向量和值向量向量的向量,它们都是有助于计算和理解注意力机制的抽象概念,因为每一组不同的q,k,v关注的点不一样,得到的attention不同。
下面的步骤进行N次:
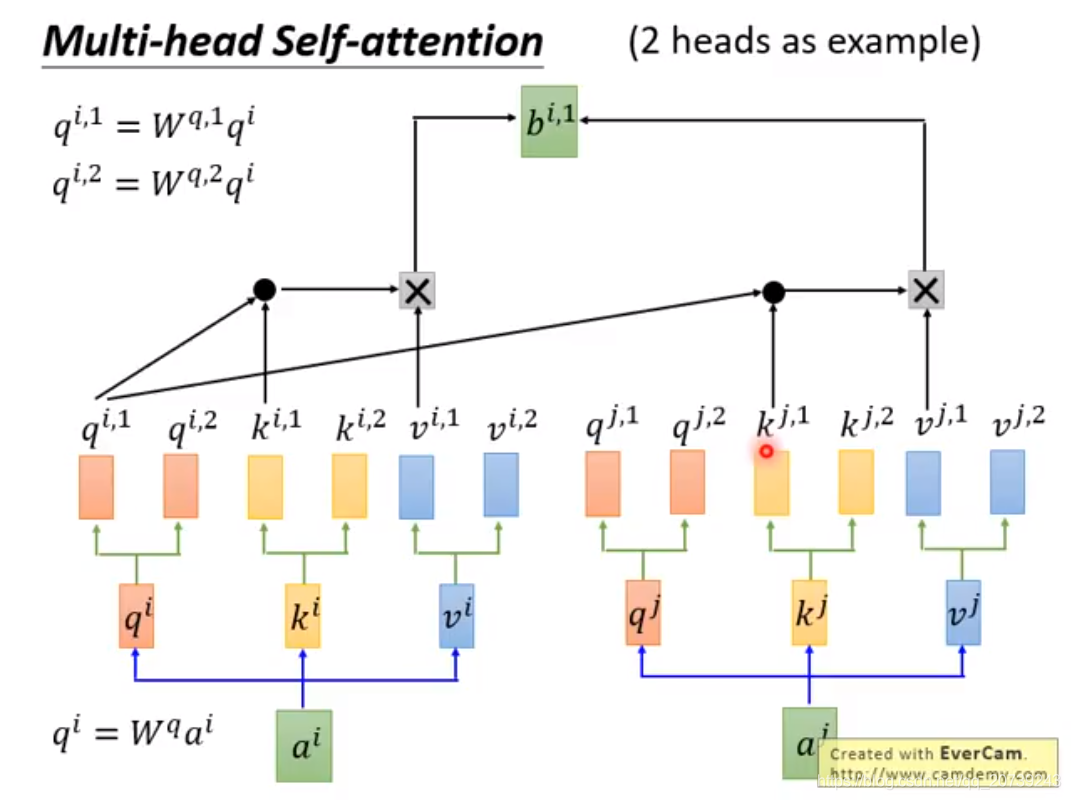
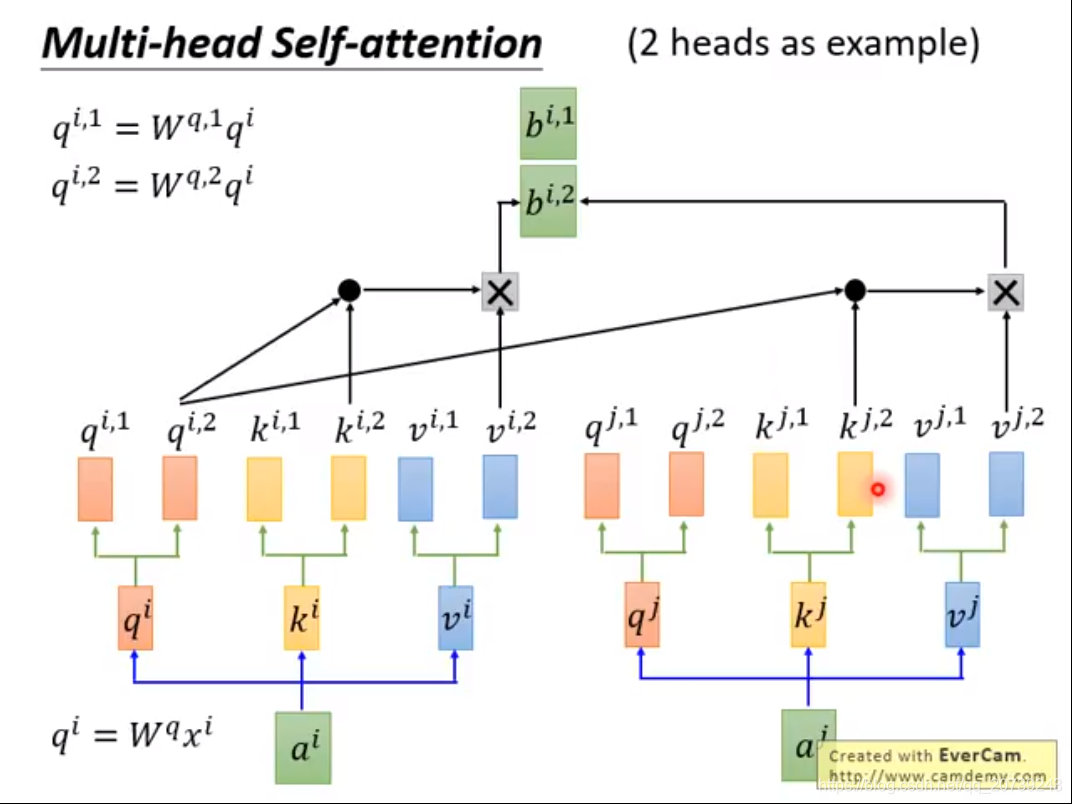
降维:
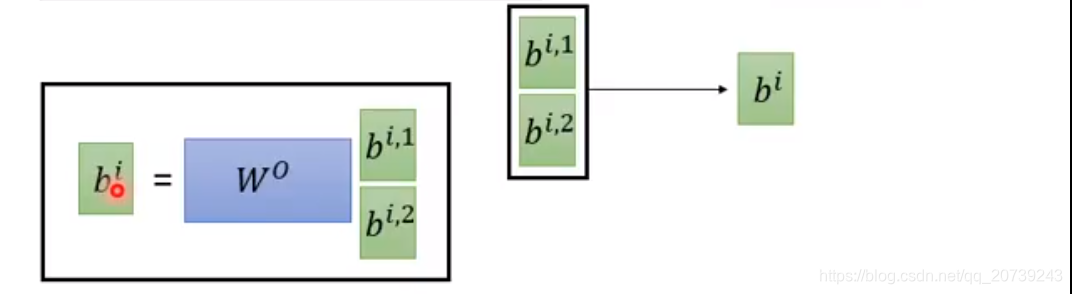
这样做的好处是不同的head关注的点不一样,会各司其职。
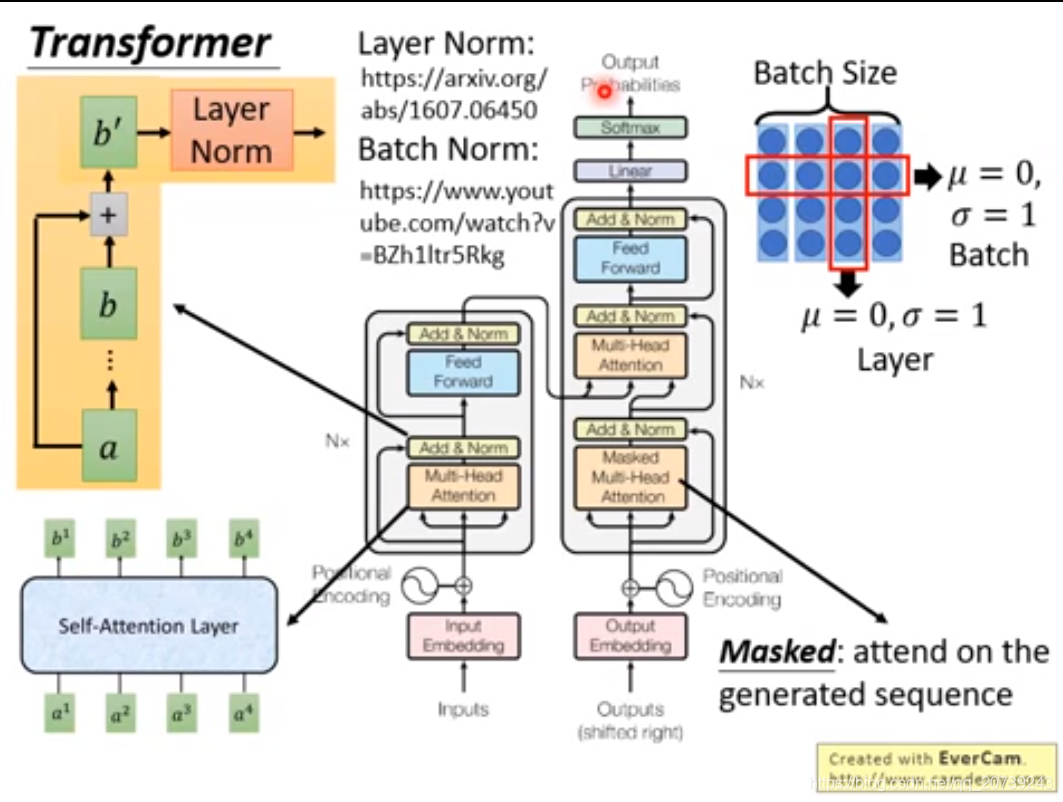
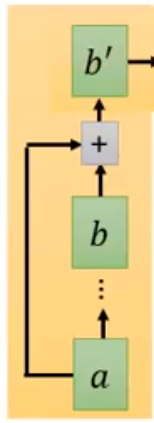
接下来add&norm:把Multi-head的输出和输入加起来,也就是ai+bi
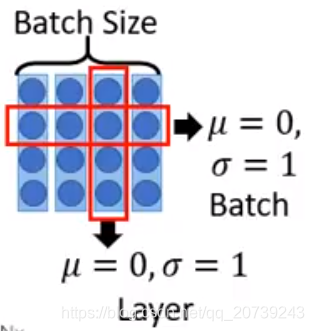
再做layer norm:让b‘不同维的均值为0,方差为1
之后再送入feed forward层(前馈神经网络),再经过一层add&norm:
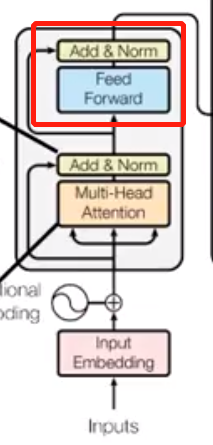
解码阶段:
输入的是之前得到的隐含状态,加上位置编码,之后的步骤循环N次:
Masked multi-head attention让解码器只关注已经产生的序列,而把未产生的序列忽略掉,得到的值和输入值进行add&norm。然后把这个值和之前编码结果一起经过multi-head attention层,之后的步骤就看图啦:
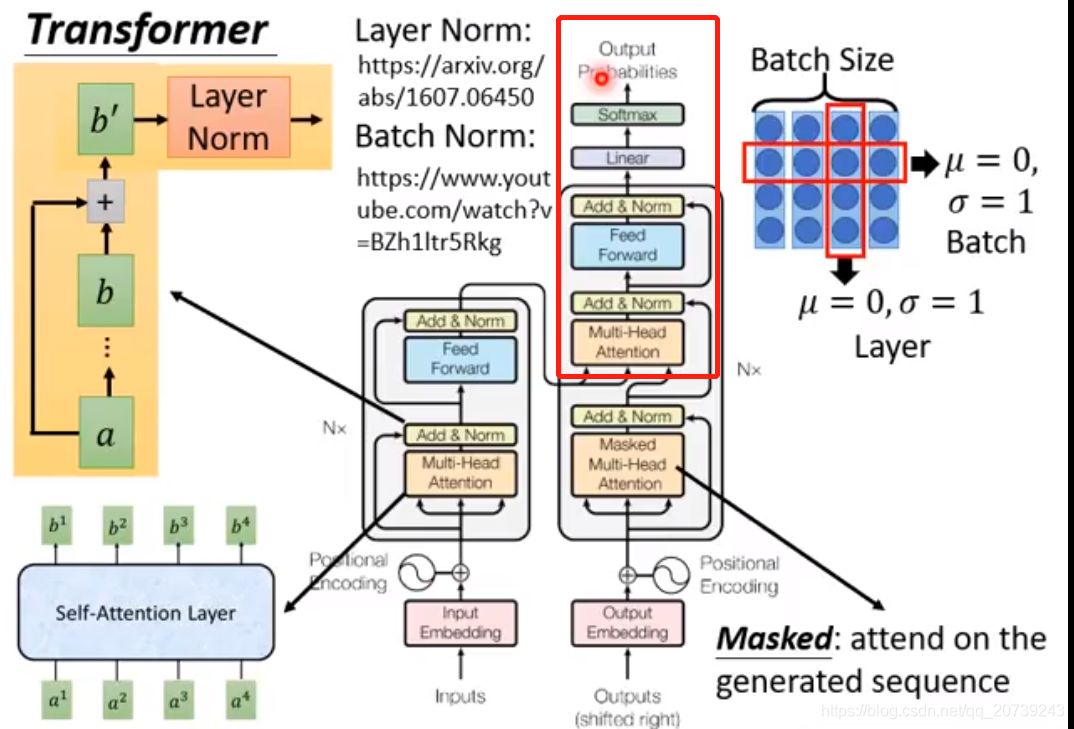
整体理解每一步到底在做什么:词向量+位置信息,送入multi-head是从不同角度去理解句子,add操作是把每一个角度理解的信息追加原始的句子,然后通过前馈神经网络去拟合,也就是从整体上对句子的理解做了一次修正。解码器也和这一过程类似,只不过是从c解码到对应的另一种语言。















 6642
6642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









