







 注意力模型(AM)在计算机视觉和自然语言处理中起关键作用,改善了Encoder-Decoder模型的局限性。通过赋予不同输入不同的注意力权重,AM能更精确地聚焦于关键信息,提高翻译和其他任务的性能。
注意力模型(AM)在计算机视觉和自然语言处理中起关键作用,改善了Encoder-Decoder模型的局限性。通过赋予不同输入不同的注意力权重,AM能更精确地聚焦于关键信息,提高翻译和其他任务的性能。
引言
Attention model(AM)最先在计算机视觉中被应用于图片识别的问题,之后在自然语言处理(NLP)和计算机视觉(CV)中经常结合递归神经网络结构RNN、GRU、LSTM等深度学习算法,被称之为Recurrent Attention Model(RAM),其核心就是一个Encoder-Decoder的过程。
传统的Encoder-Decoder模型例如RNN在做文本翻译是把一个输入语句( x1,x2,...,xi )全部输入之后得到一个语义C,然后根据这个C得到翻译的文本( y1,y2,...,yj ),文本中每一个单词都是利用了同一个语义C,也就是说输入文本的每一个单词 xi 都对输出文本的单词 yj 的贡献是一样的,显然这一点是不合理的。例如 Cat eats food 翻译成“猫吃食物”时cat 显然对于猫这个词有更大的贡献。所以attention model的作用就在于能够根据序列的变化一直更新最关心的部分。
Encoder-Decoder模型
传统RNN的Encoder-Decoder模型是没有注意力权重的,下图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示:
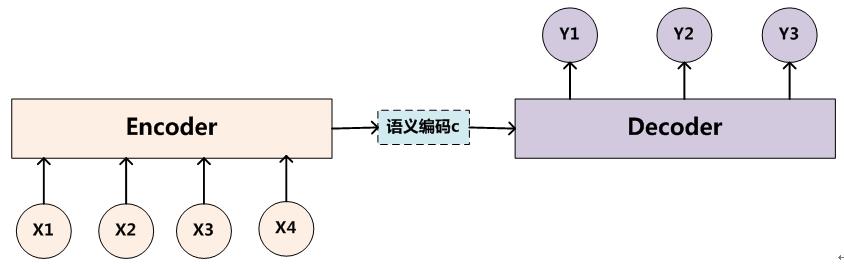
Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对
X=<x1,x2,...xi>
Y=<y1,y2,...yj>
Encoder过程中,对输入的X进行语义编码得到中间语义 C的公式为,其中F为非线性编码函数,在RNN中为其网络结构及其参数:
C=F(x1,x2,...,xi)
Decoder过程中,利用得到的中间语义 C,和之前输出的单词
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









