






上一篇:【Kaggle】Intermediate Machine Learning(缺失值+文字特征处理)
下一篇:【Kaggle】Intermediate Machine Learning(XGBoost + Data Leakage)
4. Pipelines 管道
该模块可以把数据前处理+建模整合起来
好处:
- 更清晰的代码:在预处理的每个步骤中对数据的核算都可能变得混乱。使用管道,您无需在每个步骤中手动跟踪训练和验证数据。
- 错误更少:错误地使用步骤或忘记预处理步骤的机会更少。
- 易于生产部署
- 对模型验证也有好处
步骤1: 定义前处理步骤
- 对缺失的数字数据,进行插值
- 对文字特征进行one-hot编码
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# Preprocessing for numerical data 数字数据插值
numerical_transformer = SimpleImputer(strategy='constant')
# Preprocessing for categorical data 文字特征处理,插值+编码转换
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Bundle preprocessing for numerical and categorical data
# 上面两者合并起来,形成完整的数据处理流程
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])
步骤2: 定义模型
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state=0)
步骤3: 创建和评估管道
我们使用Pipeline类来定义将预处理和建模步骤捆绑在一起的管道。
管道会在生成预测之前自动对数据进行预处理(如果没有管道,我们必须在进行预测之前先对数据进行预处理)。
# Bundle preprocessing and modeling code in a pipeline
# 将 前处理管道 + 模型管道,再次叠加形成新管道
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('model', model)
])
# Preprocessing of training data, fit model
my_pipeline.fit(X_train, y_train)
# Preprocessing of validation data, get predictions
preds = my_pipeline.predict(X_valid)
# 用定义好的pipeline 对test进行预测,提交,代码很简洁,不易出错
preds_test = my_pipeline.predict(X_test)
# Save test predictions to file
output = pd.DataFrame({'Id': X_test.index,
'SalePrice': preds_test})
output.to_csv('submission.csv', index=False)
You advanced 5,020 places on the leaderboard!
Your submission scored 16459.13640, which is an improvement of your previous score of 16619.07644. Great job!
误差有点提升,哈哈,加油!🚀
5. Cross-Validation 交叉验证
交叉验证可以更好的验证模型,把数据分成几份(Folds),依次选取一份作为验证集,其余的用来训练,显然交叉验证会花费更多的时间
如何选择是否使用:
-
对于
较小的数据集,不需要太多的计算负担,则应运行交叉验证 -
对于
较大的数据集,单个验证集就足够了,因为数据足够多了,交叉验证花费的时间成本变大 -
没有简单的准则,如果模型花费几分钟或更短的时间来运行,那就使用交叉验证吧
-
可以运行交叉验证,看看每个实验的分数是否接近。如果每个实验产生相同的结果,则单个验证集可能就足够了
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
my_pipeline = Pipeline(steps=[
('preprocessor', SimpleImputer()),
('model', RandomForestRegressor(n_estimators=50,random_state=0))
])
from sklearn.model_selection import cross_val_score
# Multiply by -1 since sklearn calculates *negative* MAE
scores = -1 * cross_val_score(my_pipeline, X, y,
cv=5,
scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)
print("Average MAE score (across experiments):")
print(scores.mean())
# 树的棵数不同情况下,交叉验证的得分均值
def get_score(n_estimators):
"""Return the average MAE over 3 CV folds of random forest model.
Keyword argument:
n_estimators -- the number of trees in the forest
"""
my_pipeline = Pipeline(steps=[
('preprocessing',SimpleImputer()),
('model',RandomForestRegressor(n_estimators=n_estimators,random_state=0))
])
scores = -1*cross_val_score(my_pipeline,X,y,cv=3,scoring='neg_mean_absolute_error')
return scores.mean()
results = {}
for i in range(1,9):# 获取树的棵树是50,100,。。。,400时,模型的效果
results[50*i] = get_score(50*i)
# 可视化不同参数下的模型效果
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(list(results.keys()), list(results.values()))
plt.show()
n_estimators_best = min(results, key=results.get) #最合适的参数
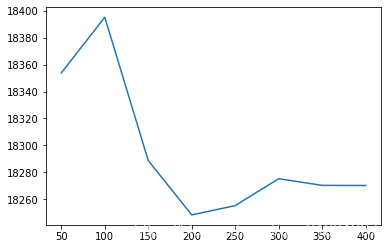
还可以通过 sklearn.model_selection.GridSearchCV 网格式搜索最佳的参数
上一篇:【Kaggle】Intermediate Machine Learning(缺失值+文字特征处理)
下一篇:【Kaggle】Intermediate Machine Learning(XGBoost + Data Leakage)















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











