







FastAPI websocket 流式语音识别服务
0. 背景
流式语音识别(Streaming ASR)或者在线语音识别(Online ASR) 是随着输入语音的数据不断增加,实时给出语音识别的文本结果。与之相对的是非实时或者离线语音识别,是传入完整的音频数据,一次给出整个音频的语音识别文本结果。
训练完一个流式的语音识别模型之后,需要将流式语音识别模型封装成一个服务,使用者通过网络访问流式语音识别服务实时获取音频的文本内容。
流式语音识别服务在实时字幕,视频直播,实时会议转写,输入法等场景都有大规模的应用。
1. Websocket 协议
在流式语音识别中,客户端client和服务端server需要进行长时间进行数据交互,client端不断地将数据传入到服务端,server需要将实时识别的文本返回给client端,因此client需要和server保持长时间的网络连接。
PaddleSpeech采用Websocket协议,保证client和server可以长时间保持网络连接。
WebSocket 协议支持全双工通信,client端和server端可以在一个网络连接上收发消息,使用WebSocket协议,可以实现client不断地向server端发送数据,进行实时语音识别。
# 下载流式ASR的demo视频
!mkdir -p work/source/
!test -f work/source/streaming_asr_demo.mp4 || wget -c https://paddlespeech.bj.bcebos.com/demos/asr_demos/streaming_asr_demo.mp4 -P work/source/
import IPython.display as dp
from IPython.display import HTML
html_str = '''
<video controls width="600" height="360" src="{}">animation</video>
'''.format("work/source/streaming_asr_demo.mov")
dp.display(HTML(html_str))
2. 测试服务
2.1 PaddleSpeech 流式协议
在PaddleSpeech中,client端使用websocket协议与server建立连接进行通信。
PaddleSpeech中client与server端的通信协议如下图所示。
在PaddleSpeech流式服务协议主要由三个部分组成,即建立链接握手,数据处理,结束链接握手。
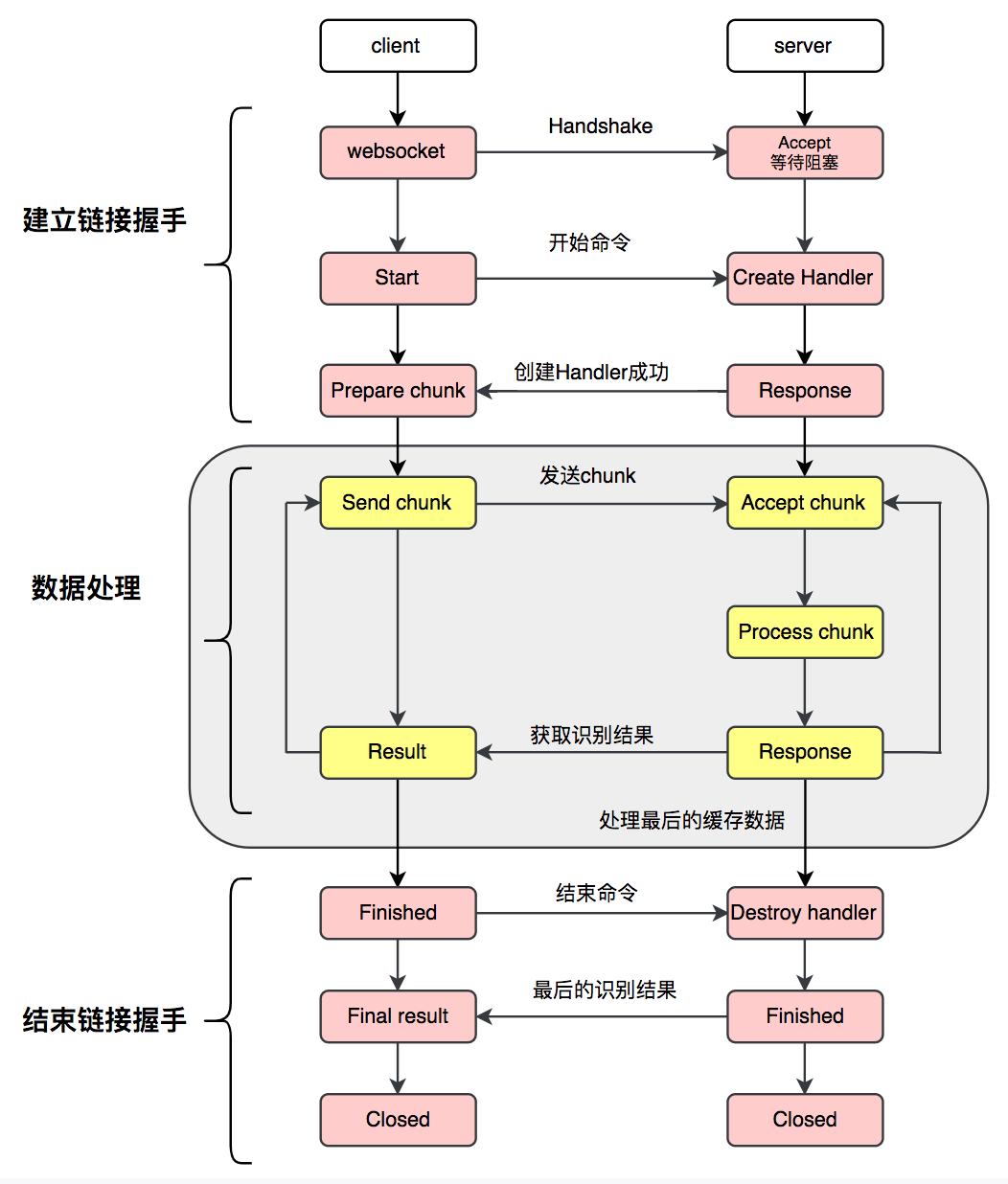
2.1 建立链接握手
在语音识别流式服务中,client端和server端需要建立长链接。
在语音识别流式服务中,client是语音识别业务的请求方,因此client需要主动和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









