







(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
定制化语音识别
1. 背景
在一些特定场景下,要求ASR系统对某些固定句式的关键词准确识别。
- 打车报销单场景,要求日期,时间,地点,金额精准识别。
- 定制化的唤醒词以及命令词,如在车机放音乐场景,那么只需要高精度的识别下一首,上一首,音量调大,音量调小等命令词。
- 还有语音助手打电话的场景,需要根据用户通讯录,完成联系人的识别等等。
为满足此种需求,本文展示一种定制化识别的方案。
第二节介绍相关的基础知识。
第三节已一个 Demo 展示如何实际操作。
PaddleSpeech SpeechX 已上线更详细的操作脚本和教程,欢迎大家关注。

来自电影《钢铁侠》
2. WFST 解码器相关概念:
2.1 WFST 介绍
WFST是加权有限状态机(weighted finite-state transducers)的简称【2】。在语音识别中,基于 WFST 生成的解码图,配合声学模型进行 viterbi 解码是语音识别中一种基础的解码方法。
这种有限状态机有一个有限的状态集合以及状态之间的跳转,其中每个跳转至少有一个标签。
如果存在一条从初始状态到终止状态的路径,使得路径上的标签序列正好等于输入符号序列,那么则输出一个新的序列和权值。
如下图WFST,输入’ac’串,匹配到0-1,1-2这个路径,输出’qs’, 权重1.63。
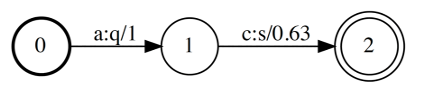
OpenFST【1】实现了 WFST【2】的相关算法,后续的算法解释以及解码图的构建与操作,都是基于 OpenFST 来完成。
相关 OpenFST 以及 WFST 的介绍可以参考如下链接:
openfst官方教程
2.2 WFST Compose 概念
下图中WFST C是有WFST A,B Compose而成,可以看做为A,B的级联,A的输出是B的输出,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









