







原创文章,转载请注明出处。
本文是排序算法系列文章的第二篇,主要讲述 “冒泡排序” 算法。
一、原理: 每一趟排序(例如第 i 趟,其中 i = 0, 1, …, n - 2),依次比较相邻两个数据元素,如果发生逆序,则交换之;待排数据的最大值 “沉” 到待排数据的最底部,(比如 i = 0 时,为第 1 趟排序,数据元素最大者将被交换到最后一个位置;i = 1 时,为第 2 趟排序,数据元素次大者将被交换到最后第二个位置),直至全部待排序的数据元素排完。由于排到 n - 1 趟时,后 n - 1 个元素已然有序,则剩余的一个元素自然也有序,因此一共需要排 n - 1 趟(外层循环 n - 1 次)。设整个待排记录序列有 n 个记录,则第 i 趟冒泡排序从 0 到 n - i - 1,因为第 i 趟排序时,后 i 个数据已经排好序,不需要再进行排序比较,只需与前 n - i - 1 个元素进行比较(内层循环从 0 到 n - i - 1)。
二、代码及注释:
void bubbleSort(int n, int *arr)
{
// 冒泡排序每一趟,例如第 i 趟,待排数据的最大值“沉”到待排数据的最底部
int i, j;
for (i = 0; i < n - 1; i++) // 第 i 趟,只需排 n - 1 趟
{
int temp; // 用于交换的临时变量
// 每排完一趟,待排数据最大的一直往下沉,沉到待排数据的底部,因而下一趟待排的数据就减少 1 个,排完 i 趟就减少 i 个
for (j = 0; j < n - i - 1; j++)
{
if (arr[j]>arr[j + 1]) // 比较大小判定是否需要交换
{
//待排数据交换,小的在前,大的在后
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
} 当输入规模为 n = 10000、20000、30000、40000、50000 时,执行程序,可以得到在不同输入规模下,20 组随机样本数据执行冒泡排序的单组执行时间及平均执行时间为:
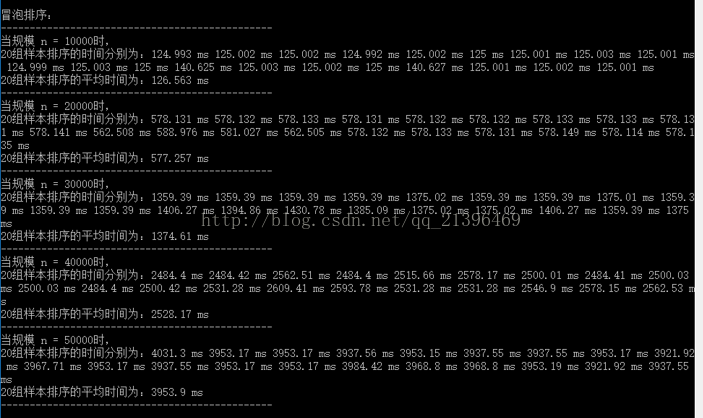
理论上来说,冒泡排序的时间复杂度为 O(n^2)。同时,由上图可以看出,当 n = 10000 时,20 组样本排序的平均执行为 126.563 ms。以输入规模为 10000 的数据运行时间为基准点,则理论上的平均执行时间为:t = k * n^2 ,(k 为常数),带入 t = 126.563 ms、n = 10000,可得:k = t / n^2 =126.563 / 100002 。
所以,在相应输入规模下,冒泡排序的理论执行时间为:

根据上表,可以作出冒泡排序理论效率曲线和实测效率曲线如下:

如上图表,是冒泡排序的理论效率曲线和实测效率曲线,其中位于上方的数据标签是实测效率曲线的标注,位于下方的数据标签是理论效率曲线的标注。由图表我们可以看出,在问题规模较小时,理论消耗时间和实际消耗时间相近,而随着输入规模的增大实际消耗的时间与理论消耗时间的差距越来越大。
首先,不管是理论效率曲线还是实测效率曲线,都大致满足抛物线 y = k * n2 在某个定义域的一段曲线(其中 k 为系数,两条曲线的系数 k 有所差别)。这同样与我们的理论认知也是相一致的。
在冒泡排序过程中,若初始序列为正序,则只需进行一趟排序,在这趟排序中需进行 (n - 1) 次比较操作,但不移动数据元素,这样便是冒泡排序最好的时间复杂度 O(n);但若初始序列为逆序,则需要进行 (n - 1) 趟排序,每趟排序要进行 (n - i) 次比较操作,且每次比较都必须有 3 次移动操作来完成数据元素的交换,这种情况下,比较操作的次数为 n (n - 1) / 2,而移动操作的次数为 3n (n - 1) / 2,这样冒泡排序最坏的时间复杂度为 O(n 2)。因此,总的时间复杂度为 O(n 2),这应当是理论效率曲线所反映出来的。 而实测效率曲线与理论效率曲线在趋势上基本相符,在规模较小时,二者吻合得较好,但规模较大时实际消耗时间则高于理论消耗时间,且随着输入规模的增大,实际消耗时间与理论消耗时间的差距越来越大。同时,仔细一点可以注意到,在同样的问题规模下,冒泡排序耗时是选择排序的几倍多,这与排序算法思想有关。选择排序在执行比较操作时记录下位置,确定最终位置后才进行一次移动(交换)操作,而冒泡排序在比较操作时一旦满足条件就进行移动(交换)操作,相比选择排序多了很多移动操作。这在问题规模小时影响还不是很大,但规模一旦增大便凸显出来了。同样地,实际耗时与理论耗时的差距,也是由大量的移动赋值操作拉开的。当然实测耗时也同样与程序运行时电脑的CPU的资源利用有关。















 1720
1720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









