







一、训练误差&泛化误差
训练误差:模型在训练数据上的误差。
泛化误差:模型在新数据上的误差。
二、验证数据集&测试数据集
验证数据集:验证模型好坏的数据集。不要与训练数据集搞混。比如在不同超参数情况下训练好模型之后查看其表现。
测试数据集:只用一次的数据集。
K折交叉验证
方法:
- 将训练数据集分成K块
- For i =1,…,k
- 使用第i块作为验证数据集,其余的作为训练数据集
- 报告K个验证集误差的平均
- 常用:k=5或10
总结
- 训练数据集:训练模型参数
- 验证数据集:选择模型超参数
- 非大数据集上通常用k-折交叉验证
三、过拟合和欠拟合
欠拟合:模型无法得到较低的训练误差。
过拟合:训练误差明显低于验证误差时要⼩⼼,这表明严重的过拟合。
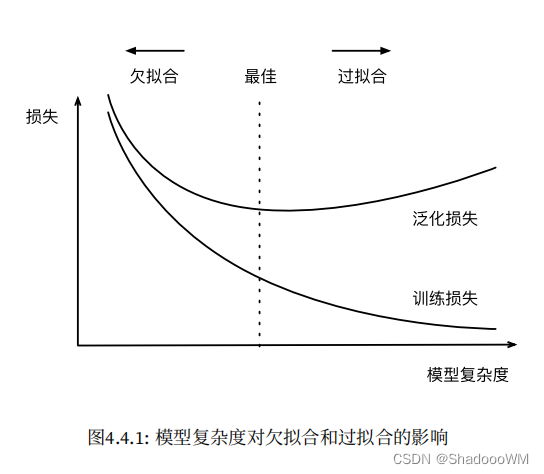
四、数据复杂度
- 多个重要因素
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性
五、模型复杂度
项数多,网络结构深都是模型复杂的标志。















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









