







目录
一、模型选择
1.1 模型选择
◼ 泛化误差和训练误差
任务:预测谁会不还贷款
你发现所有的5个人在面试的时候都穿了蓝色的衬衫,你的模型也发现了这个强信号,这回有什么问题吗?当下次面试的人有人穿了红色的衬衫时,会怎么样?

错误性的强信号:每个人都穿了蓝色衣服
我们看这个问题的时候,最正常的就是去看两种误差:

我们关心的是泛化误差,其实不关心训练误差。
那么我们一般怎么去计算泛化误差和训练误差这两种误差呢?
◼ 训练数据集和测试数据集

注意:验证数据集一定不能跟测试数据集混在一起,
比如房价预测, 我出价房子的实际成交价是我的测试数据集,一旦发生就无法改变。所以说,测数据集理论上来说只能被使用一次。
我们在后续写代码里的test其实很多时候是验证数据集,真正的测试数据集是一个新的数据集,甚至是不知道标号的一个新的数据集。验证数据集很有可能也是虚高的,因为你的超参数很有可能是在验证数据集上调出来的。
所以说,验证数据集的精度不是真正的代表你在新数据集上的泛化能力。
◼K-则交叉验证
我们经常会遇到其实没有那么多的验证数据集。如果直接拿一半的数据集作为验证数据集,不参与训练模型的话,其实会觉得比较亏。所以解决这个问题常见的一个做法是K-则交叉验证算法。
比较简单,我们拿到数据集之后,先简单打散一下,分割成k块(所谓的K则就是这个k)。分割成k块之后,我们做k次计算。

比如我做3-则交叉验证,那么我拿到数据集之后,先简单打散一下,分割成3块,一共做k=3次计算:
- 第1次计算:将第1块作为val验证数据集,其余作为训练数据集train。在后面两块上训练我的模型,在第1块验证数据集验证我的精度;
- 第2次计算:将第2块作为val验证数据集,其余作为训练数据集train。在训练数据集上训练我的模型,在第1块验证数据集验证我的精度;
- 第3次计算:将第3块作为val验证数据集,其余作为训练数据集train。在训练数据集上训练我的模型,在第1块验证数据集验证我的精度;
这样,我们会拿到3次验证的精度或误差,做平均,就得到了3-则交叉验证的误差;
这样就会发现,如果是3-则交叉验证的话,我们使用了66%的数据集作为训练,但是因为val验证数据集变小的话可能存在误差,那么这个误差我会通过做3次验证的精度或误差来取平均。
极端情况下,比如我做n-则交叉验证,每次我只留1块作为val验证数据集,其余作为训练数据集train。这种极端情况下,我能够尽可能尽大的使用我的数据集,但是它的代价是算起来特别贵。假设是1万的话,得跑一万遍。
所以常见的,我们一般取5或者10。
◼ 总结

二、过拟合、欠拟合
2.1 过拟合、欠拟合

所以说,根据数据集的简单和复杂,来选择模型的容量。
如果数据集是比较简单,那么应该来选择比较低的模型容量,这会得到一个比较正常的结果。如果选择比较高的模型容量,模型过于复杂时,那么模型就会直接会把每一个样本直接记住,那我记住样本,很有可能看到新样本,模型其实并没有泛化性,会导致过拟合。
欠拟合同理。

2.2 模型容量
◼ 模型容量
模型容量的具体定义:

在多项式拟合中,模型容量为不同多项式次方。
模型容量比较低的时候,训练误差会比较高,这是因为模型过于简单,无法拟合复杂的数据。随着模型容量的增加,训练误差会逐渐下降,但是记住所有的数据并不是好的现象,因为数据里有噪音,无用。

我们会发现我们真正关心的泛化误差,一开始会随着模型容量的增加而下降,但是下降到某一个点时,开始缓慢往上升,这就说明当到某种程度的时候,模型过于关注某些细节,导致来一个新的数据,会被无关的细节所困扰。
我们用泛化误差和训练误差之间的gap来表示这两种误差的程度。
◼ 估计模型容量
其实,模型容量是可以估计的,但是我们难以在不同的种类算法之间进行比较。比如树模型和神经网络,这两种模型特别不一样,不好直接比较。
但是比如说,我们给定两种模型的种类,我们一般去衡量因素:
- 参数个数:
- 线性模型的参数个数是d+1;
- 单隐藏层,那么参数个数为(d+1)m+(m+1)k;
- 参数值的选择范围:如果可以在很大一个区域选择值的话,那么模型的复杂度比较高。
其中,d是特征向量的维度,1是偏置b的维度。

◼ VC维

假设我的模型可以做一个很复杂的数据集,不管图片怎么选择,有多少,我都可以通过一个模型对数据集进行分类的话,那么其实这个模型肯定要比我只能对一个10张图片的数据集不管怎么标号都能进行分类的模型要来得快。
或者我们可以认为这个模型的复杂度等价于我能够完美的记住一个数据集,这个数据集最大有多大。
线性分类器的VC维:

VC维的好处:

◼ 数据的复杂度
数据的复杂度有多个比较重要的因素:
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性
◼ 模型容量总结

三、多项式解释欠拟合、过拟合
(1)我们通过一个很简单的人工数据集来探索一下这个事情,
① 使用以下三阶多项式来生成训练和测试数据的标签:
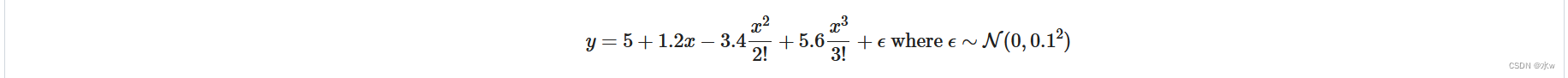
② 这个式子只是一个三次多项式,并不是哪个函数的泰勒展开。
我们用100个测试样本,100个验证样本。w是一个长为20的,[5,1.2,-3.4,5.6]真实标号为5,其余都是0。
会产生一个特征为20的向量,前5个是有值的,后面都是一些0,即噪音。
# 通过多项式拟合来交互地探索这些概念
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
max_degree = 20 # 特征为20就是每一个样本是一个[20,1]的tensor
n_train, n_test = 100, 100 # 100个测试样本、100验证样本
true_w = np.zeros(max_degree)
true_w[0:4] = np.array([5,1.2,-3.4,5.6]) # 真实标号为5
features = np.random.normal(size=(n_train+n_test,1))
print(features.shape)
np.random.shuffle(features)
print(np.arange(max_degree))
print(np.arange(max_degree).reshape(1,-1))
print(np.power([[10,20]],[[1,2]]))
poly_features = np.power(features, np.arange(max_degree).reshape(1,-1)) # 对第所有维的特征取0次方、1次方、2次方...19次方
for i in range(max_degree):
poly_features[:,i] /= math.gamma(i+1) # i次方的特征除以(i+1)阶乘
labels = np.dot(poly_features,true_w) # 根据多项式生成y,即生成真实的labels
labels += np.random.normal(scale=0.1,size=labels.shape) # 对真实labels加噪音进去
#看一下前两个样本
true_w, features, poly_features, labels = [torch.tensor(x,dtype=torch.float32) for x in [true_w, features, poly_features, labels]]
print(features[:2]) # 前两个样本的x
print(poly_features[:2,:]) # 前两个样本的x的所有次方
print(labels[:2]) # 前两个样本的x对应的y
# 实现一个函数来评估模型在给定数据集上的损失
def evaluate_loss(net, data_iter, loss):
"""评估给定数据集上模型的损失"""
metric = d2l.Accumulator(2) # 两个数的累加器
for X, y in data_iter: # 从迭代器中拿出对应特征和标签
out = net(X)
y = y.reshape(out.shape) # 将真实标签与网络输出标签的形式,统一形式
l = loss(out, y) # 计算网络输出的预测值与真实值之间的损失差值
metric.add(l.sum(), l.numel()) # 总量除以个数,等于平均
return metric[0] / metric[1] # 返回数据集的平均损失
# 定义训练函数
def train(train_features, test_features, train_labels, test_labels, num_epochs=400):
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False)) # 单层线性回归网络
batch_size = min(10,train_labels.shape[0])
train_iter = d2l.load_array((train_features,train_labels.reshape(-1,1)),batch_size)
test_iter = d2l.load_array((test_features,test_labels.reshape(-1,1)),batch_size,is_train=False)
trainer = torch.optim.SGD(net.parameters(),lr=0.01)
animator = d2l.Animator(xlabel='epoch',ylabel='loss',yscale='log',xlim=[1,num_epochs],ylim=[1e-3,1e2],legend=['train','test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss), evaluate_loss(net,test_iter,loss)))
print('weight',net[0].weight.data.numpy()) # 训练完后打印整个曲线的变化,并打印最终学到的weight值 
# 三阶多项式函数拟合(正态)
train(poly_features[:n_train,:4],poly_features[n_train:,:4],labels[:n_train],labels[n_train:]) # 最后返回的weight值和公式真实weight值很接近 
可以看出, 我把整个样本的前面4列(前面4列是有权重的,后面都是噪音)给模型,数据和模型是匹配的。
图中,2个地方是比较重要的:
- 曲线最后训练和测试的loss:可以看到结果还行,都在0.01上面一点点;
- 训练和测试loss之间的gap:曲线最后说明测试和测试loss是差不多的,没有发生太多的过拟合;
那么,我只把整个样本的前面2列(前面4列是有权重的,后面都是噪音)给模型,结果怎么样?
# 一阶多项式函数拟合(欠拟合)
# 这里相当于用一阶多项式拟合真实的三阶多项式,欠拟合了,损失很高,根本就没降
train(poly_features[:n_train,:2],poly_features[n_train:,:2],labels[:n_train],labels[n_train:])

只把整个样本的前面2列(前面4列是有权重的,后面都是噪音)给模型,这就说明数据都没有全给模型,可以看到,最后的训练和测试损失loss与上文的0.01相比,都是非常高的。可以说明训练和测试的loss根本就没有下降,数据都没有全给模型,所以根本就没有训练好模型,可以简单认为这个一个欠拟合。
那么过拟合呢?我把整个样本的20列(前面4列是有权重的,后面都是噪音)都给模型,那么模型不变的情况下,数据变得更加有误导性,后面的那些w本来应该是0的,其实都是一些噪音,但是模型全部都学了。
# 十九阶多项式函数拟合(过拟合)
# 这里相当于用十九阶多项式拟合真实的三阶多项式,过拟合了
train(poly_features[:n_train,:],poly_features[n_train:,:],labels[:n_train],labels[n_train:])

从图中可以看到,最后的训练和测试损失loss其实没有下降太多,但是最后的训练和测试损失loss直接的gap很大。
其实跑到中间的时候,模型已经把那4列的w都学到了,但是模型一直不断持续的学,就会导致学到了一些不应该学的噪音。
















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











