







(一)训练误差和泛化误差
训练误差(training error):模型在训练数据集上表现出的误差
泛化误差(generalization error):模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。
一般情况下,由训练数据集学到的模型参数会使模型在训练数据集上的表现优于或等于在测试数据集上的表现。由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。
机器学习模型应关注降低泛化误差。
(二)模型选择
①验证数据集(validation data set)
预留一部分在训练数据集和测试数据集以外的数据来进行模型选择
②K折交叉验证(K-fold cross-validation)
把原始数据集平均分成五份,每次选一个作为子数据集验证模型,并使用其他 K−1个子数据集来训练模型。最后求平均。
(三)欠拟合和过拟合
①模型复杂度
对于一个K阶多项式函数来近似y:
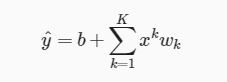
阶数越高,复杂度越高,复杂度过高可能会导致过拟合,模型训练时候的误差很小,但在测试的时候误差很大,也就是我们的模型复杂到可以拟合到我们的所有训练样本了,但在实际预测新的样本的时候,糟糕的一塌糊涂。复杂度过低可能会造成欠拟合。
②训练数据集大小
训练数据集中样本过少时可能导致过拟合。
在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。
 如图所示,从左到右,分别是欠拟合,合适的拟合和过拟合。
如图所示,从左到右,分别是欠拟合,合适的拟合和过拟合。
(四)多项式函数拟合实验
生成数据集
①mxnet.ndarray.concat(data, kwargs)
沿着给定轴输入数组,默认连接的维数是1。
②mxnet.ndarray.power(base, exp)
返回从第二个数组提升到幂的第一个数组元素的结果,按元素进行广播。
例如:x=[[ 2., 2., 2.],
[ 2., 2., 2.]]
y=[[ 1.],
[ 2.]]
mx.nd.power(x,y).asnumpy()
=[[ 2., 2., 2.],
[ 4., 4., 4.]],
定义、训练和测试模型
利用了matplotlib中的semilogy函数,定义得到semilogy函数,作用是:
在y轴上绘制一个带有对数刻度的图。
多项式函数拟合的训练和测试模型:
fit_and_plot函数:
①先定义一个模型变量net,它是一个Sequential实例。在Gluon中,全连接层是一个Dense实例。该层输出为1。接着初始化参数。
②设置小批量大小为10,得到训练的小批量数据train_iter。
③在导入Gluon后,我们创建一个Trainer实例,并指定学习率为0.01的小批量随机梯度下降(sgd)为优化算法。
④接着在每个周期内,对于训练的小批量数据进行操作,求损失l,再利用trainer.step()进行类似于sgd的操作,再利用训练得到的参数分别求训练和测试数据的损失
⑤训练周期完成以后,输出最后一个周期得到的train loss和test loss
利用semilogy函数作图,并显示训练得到的weight和bias。















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









