







1、方法
权重衰减等价于L2范数正则化。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。
原始损失函数如下:
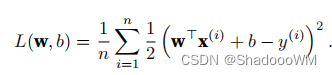
带有L2范数惩罚项的新损失函数为:
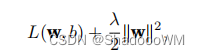
较⼩的λ值对应较少约束的w,⽽较⼤的λ值对w的约束更⼤
计算梯度方法:

理解:
1、正则项就是防止达到损失函数最优导致过拟合,把损失函数最优点往外拉一拉。
2、损失函数加上正则项成为目标函数,目标函数最优解不是损失函数最优解。
trainer = torch.optim.SGD('weight_decay':)
weight_deacy:相当于是lambda,只不过是在算出需要的梯度之后再修饰梯度以便于更新。
杂⑦杂⑧:
1、

2、
MSEloss(L2loss):
M
S
E
=
∑
i
=
1
n
(
f
x
i
−
y
i
)
2
n
M S E=\frac{\sum_{i=1}^{n}\left(f_{x_{i}}-y_{i}\right)^{2}}{n}
MSE=n∑i=1n(fxi−yi)2
平方损失函数:
s q u a r e l o s s = ∑ i = 1 n ( f x i − y i ) 2 2 n square loss=\frac{\sum_{i=1}^{n}\left(f_{x_{i}}-y_{i}\right)^{2}}{2n} squareloss=2n∑i=1n(fxi−yi)2
3、
为什么限制了参数会防止过拟合呢?
由于训练得到的数据都是带有噪音的,所以会导致训练到的W值变大,因为训练尽量的拟合了噪音导致曲线过于复杂,所以限制参数一定程度上可以抵消噪音带来的影响降低过拟合。















 7723
7723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









