







1 背景
在这个信息膨胀的大数据智能时代,如何安全获取与使用个人的相关数据,渐渐成为迫切需要解决的问题。基于大数据的人工智能应用层出不穷,每个人都感觉自己在被时刻的跟踪,感觉在整个网络面前没有丝毫的隐私。没有人希望自己连生个病、上个网或者买件衣服都会被人随意知晓,更别提手机里的若干自拍了。
最开始的时候,人们对个人信息数据采用“匿名化“的方式进行使用,并且认为这样是安全与可靠的,很不幸,发生了几件重大的事件,给数据的安全使用敲响了警钟。
20世纪最著名的用户隐私泄漏事件发生在美国马萨诸塞州。该州集团保险委员会(GIC)发布了“经过匿名化处理的”医疗数据,用于公共医学研究。在数据发布之前,为了防止隐私泄露问题,特地删除了数据中所有的个人敏感信息,例如身份证号、姓名、住址,但是保留了(每位患者生日、性别、邮编)。然而在1997 年,卡内基梅隆大学的博士Latanya Sweeney将匿名化的GIC数据库(包含了每位患者生日、性别、邮编)与选民登记记录相连后,主要应用“每位患者生日、性别、邮编“三元组的弱唯一性,成功破解了这份匿名数据,并找到了当时的马萨诸塞州州长William Weld的医疗记录。

2006 年 10 月,Netflix 举办了一项大奖赛(Netflix Prize Competition)。比赛中,Netflix 提供了一个数据集,包含了从 1988 年到 2005 年间,超过 48 万个随机选择的匿名用户对于一万七千多部电影的评分。数据集中包括的具体数据有:用户 ID(随机分配,无法推出真实 ID)、电影信息(ID、年份、标题、用户对电影的评分等。
Netflix 希望参赛队提出一种算法,使得在相同的训练集上,新算法预测用户喜好的性能比现有算法的性能高出 10%,并宣布对效果最好的队伍给予 50000 美元的奖励。这场比赛持续了 5 年之久,引发了各国参赛队伍激烈的竞争。
然而,2008 年,来自德州大学奥斯汀分校的两名研究人员 Arvind Narayanan 和 Vitaly Shmatikov 发表了名为《Robust De-anonymization of Large Sparse Datasets》的论文,详细描述了如何对 Netflix 提供的数据进行隐私攻击。为此Netflix被发起了集体诉讼,最终以600W美金了结此事。

2 法律法规约束
近年来,许多国家和地区都颁布了用于保护个人隐私信息的法律法规。在这样的背景下,重视消费者隐私的保护与合法合规使用,是科技公司必然的选择。
- 在欧洲,2016 年发布、2018 年开始强制执行的《通用数据保护条例》(General Data Protection Regulation, GDPR)涵盖范围广、保护要求严格,甫一推行就引发了科技公司的密切关注。
- 在美国,尽管联邦层面没有专门用于隐私保护的法律,但在2018 年,严格程度不逊于 GDPR 的《加州消费者隐私法案》 (California Consumer Privacy Act, CCPA)出台,尽管只是州法,但由于加州在科技领域的特殊地位,其影响范围同样是全球性的。
- 在我国,近年陆续颁布或修订的《民法典》《网络安全法》均为个人信息保护作了专门规定,《消费者权益保护法》《执业医师法》等部门法则从消费、医疗等具体维度反映了对个人信息的保护。 同时,尚处草案阶段的《个人信息保护法》也标志着我国对互联网时代个人信息保护的重视达到了一个新的高度。
- 经过三次审议,十三届全国人大常委会第三十次会议表决通过了《中华人民共和国个人信息保护法》,并与2021年11月1日起施行。确立个人信息保护原则、规范处理活动保障权益、禁止“大数据杀熟”规范自动化决策、严格保护敏感个人信息、赋予个人充分权利等。
《个人信息保护法》也对违法惩罚作出了规定,相较于之前的轻微处罚,在新规施行后,违法的主体将最高可处五千万以下或者上一年度营业额百分之五以下的罚款。以某个电商企业为例,其2019年的中国销售额为4557.12亿元,如果处以顶格的5%罚款,那么罚款总额将会达到227.856亿元。
因此,如何安全合规的使用个人数据这个难题就摆在了我们的面前,如果稍有不慎,就会造成巨大的经济损失,所以目前很多公司都在这方面进行重金投入,期望打造安全合规的使用方式。
3 数据合规使用
那么什么是数据的合规使用呢,结合上述法律法规,首先要定义个人信息的概念,尽管各国法规的具体条款各异,但它们对于”个人信息“的定义却有很大重合度,基本都以”可识别性“为主要判定标准。
例如,《民法典》规定”个人信息是以电子或者其他方式记录的能够单独或者与其他信息结合识别特定自然人的各种信息“,而 GDPR 也规定"个人数据"是指与已识别或可识别的自然人(数据主体)相关的任何信息。
那么基于此定义,我们可以这样理解,我们针对个人信息进行”采、存、算“的过程中,如果无法准确的通过自身数据信息以及其他相关联的数据信息进而准确的判断出这个人是谁的话,那么整个数据的使用过程,还是相对安全的。
基于此,我们要想合规的使用数据,其实就是面临着两件事情,我们要做的就是这两件事情的平衡。
- 保护个人隐私,不泄露个体精确信息:隐私保护技术能提供何种强度的保护,能够抵御何种强度的攻击,包括从数据采集、存储、计算整个链路的数据保护机制。
- 保护个人隐私的同时,综合保留数据价值:在保护隐私的同时,最大限度地保留原数据中的有用信息,既能保护数据,又能最大限度的保留数据的价值,能够进行业务赋能。
我们所做的事情,就是在数据隐私与数据价值之间进行平衡,在保障隐私的同时,实现数据价值的体现。
4 技术方案

上图来自杨强教授KDD 2021中国区的演讲内容,针对隐私计算的发展历程做了总结,从最开始的安全多方计算、差分隐私、TEE到现在的当红小生联邦学习,都进行了综合性的描述,从上面可以看出,隐私计算的要求是比较早的,但是一直都是不温不火,一方面是对隐私的重视程度,另外一个方面就是技术的突破,安全多方计算的性能之比较大的问题,从差分隐私到联邦学习在计算性能与效果性能进行了一些平衡,所以很好的应用到了现实中的场景中。并且在近年内大放异彩。
5 差分隐私:Differential Privacy
本节主要介绍在隐私计算领域内,被广泛应用的Differential Privacy(差分隐私)技术,差分隐私的本质就是对数据进行适当的加噪加扰,进而达到数据隐私与可用性之间的平衡。
基于差分隐私优秀的普适性,很多企业都将差分隐私作为其解决隐私安全的关键技术。
- 在2016年WWDC主题演讲中,苹果工程副总裁Craig Federighi宣布苹果使用本地化差分隐私技术来保护iOS/MacOS用户隐私。根据其官网披露的消息,苹果将该技术应用于Emoji、QuickType输入建议、查找提示等领域。
- Google利用本地化差分隐私保护技术从Chrome浏览器每天采集超过1400万用户行为统计数据。
5.1 差分攻击:Differential Attack
提起差分隐私,就不得不提起差分攻击。其实我们思考这样一个问题,如果数据是静态的,并且我们都是提供全局的检索,不提供”添加、删除“,也不提供精确的过滤条件,那么针对整个静态的群体查询是没有太大的问题的。
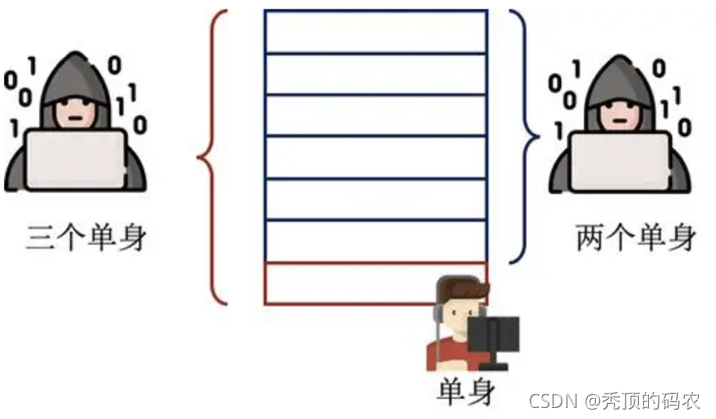
但是假设有这样一个场景,话说在某个盛产帅哥的城市,单身的优质女神非常紧俏。假设这个城市某个接到的信息库里面有500个适龄女青年的信息,其中498个都是已婚,只有2个是单身,那么这个时候我们整体查询单身的人数是2。这个时候,女神A姐搬到这个街道,并且信息加入到了这个库里面,同时A姐也是单身,这个时候在进行整体数据库的查询单身的话,就是3个。那么我们就可以轻易的知道原来女神A姐还是单身,导致广大男青年纷纷找到A姐要微信,A姐不胜其烦。
那么这个时候如果在A姐加入后进行查询的时候,如果查询结果输出的是2.3,A姐没有加入的时候输出结果是2.4的话,这样A姐加入后的查询就无法泄露女神A姐是不是单身了,这个方法就是差分隐私。
5.2 差分隐私的定义
假设有随机算法M,S为M所有可能输出结果构成的集合,Pr[ ]表示概率。对于任意两个相邻数据集
D
,
D
‘
D,D^`
D,D‘,两个数据集两个数据集的差别只有1条记录,如果两个相邻集合的概率分布满足如下约束条件:
P
r
[
M
(
D
)
∈
S
]
≤
e
ϵ
P
r
[
M
(
d
‘
)
∈
S
]
Pr[M(D) \in S] \leq e^{\epsilon}Pr[M(d^`)\in S]
Pr[M(D)∈S]≤eϵPr[M(d‘)∈S]
或者
P
r
[
M
(
D
)
∈
S
]
≤
e
ϵ
P
r
[
M
(
d
‘
)
∈
S
]
+
δ
Pr[M(D) \in S] \leq e^{\epsilon}Pr[M(d^`)\in S] + \delta
Pr[M(D)∈S]≤eϵPr[M(d‘)∈S]+δ
注:两个公式的差异在于是否使用松弛变量,另外公式的推导可以使用衡量两个分布差异的KL-Divergence来进行推导。
满足上述条件的情况下,则称算法M提供了
ϵ
−
\epsilon -
ϵ−差分隐私保护,其中
ϵ
\epsilon
ϵ为差分隐私预算,用来保证数据集中增加或者较少一条数据记录,随机算法M的输出结果不可区分性的概率。如下图所示:
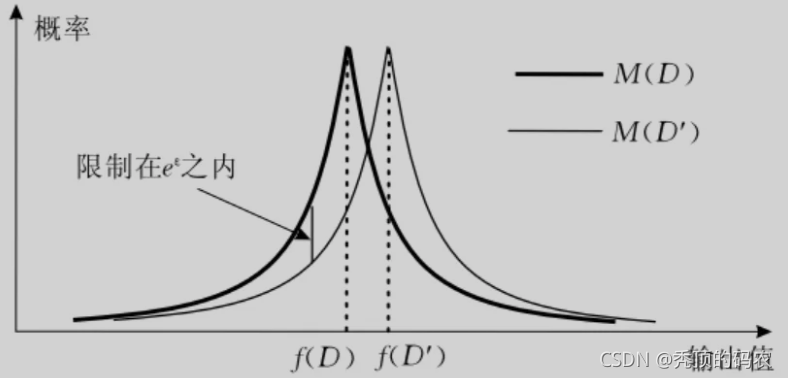
ϵ \epsilon ϵ的值越小,随机算法M在两个数据集 D , D ‘ D,D^` D,D‘上的概率分区越接近,输出的结果就越难区分,可区分性差,隐私保护强度越高。特殊情况下,当 ϵ \epsilon ϵ为0的时候,两个数据集的分布重合,输出结果完全不可区分,隐私强度是高了,但是这种情况下,原始数据的可用性也就丧失了。我们要做的是数据信息的隐私保护与可用性之间的平衡,所以 ϵ \epsilon ϵ的设置需要斟酌。
上面章节从差分攻击的角度解释了什么是差分隐私,简而言之,差分隐私就是在临近的数据集使用的时候,通过加入一些噪声,实现加扰,让数据整体的多次全方位的使用不会透漏出个体的用户信息,并且通过算法保障,即使加了噪音,数据依然可以在最大的程度保持综合的可用性。
差分隐私的关键四元组:
- 集合1:D
- 集合2: D ‘ D^` D‘
- 随机算法:M
- 约束因子: ϵ \epsilon ϵ
- 可选松弛变量项: δ \delta δ
5.3 差分隐私的实现
针对需要进行差分隐私保护的数据,我们大体可以分为两个部分,其一是数值型数据,比如上面例子中的已婚人士的,其二是非数值型的数据,比如形状三角形、四边形等。
- 针对数值型的数据,采用Laplace或者高斯机制,对数据结果添加随机动态扰动噪声进行实现。
- 针对非数值型数据 ,采用指数机制进而引入一种打分机制,枚举计算各自离散分类的输出分数,并且经过归一化之后作为概率值进行表征。
接下来,就和大家具体介绍下差分隐私的实现机制,做到知其然而知其所以然,不过在这之前先介绍下敏感痘这个概念。
5.3.1 敏感度
定义:差分隐私中的敏感度的意义是,针对两个相邻数据集
D
,
D
‘
D,D^`
D,D‘,随机函数f()的最大变化范围,也就是说加入噪声后的震荡范围,记做
Δ
f
\Delta f
Δf,则敏感度计算的公式如下:
Δ
f
=
m
a
x
D
,
D
‘
∥
f
(
D
)
−
f
(
D
‘
)
∥
1
\Delta f = max_{D,D^`} \|f(D) - f(D^`)\|_1
Δf=maxD,D‘∥f(D)−f(D‘)∥1
5.3.2 数值型方案 - Laplace机制
- 首先,优先介绍Laplace分布,其属于连续分布,所以连续分布的概率密度符合,其中 μ \mu μ是位置参数, b b b是尺度参数,那么拉普拉斯分布的数学期望是 μ \mu μ,方差是 2 b 2 2b^2 2b2。
f ( x ∣ μ , b ) = 1 2 b e − ∣ x − μ ∣ b f(x|\mu,b) = \frac{1}{2b}e^{-\frac{|x-\mu|}{b}} f(x∣μ,b)=2b1e−b∣x−μ∣
-
其次,介绍基于Laplace的差分隐私机制。其中f(D)表示的是随机算法(比如查询),Y表示的是Laplace噪声,并且符合拉普拉斯分布,M(D)表示的是加了噪声之后的混淆的最后的展示结果,这个过程表达的是在随机算法的基础上添加服从Laplace的噪声。
M ( D ) = f ( D ) + Y M(D) = f(D) + Y M(D)=f(D)+Y -
再次,那么Laplace是如何应用差分隐私的呢,下面和大家娓娓道来,从上面的公式可以感知,Y是我们要处理的噪声,那么这个Y需要满足什么条件呢。
-
再次,我们来定义Y: Y ∼ L ( 0 , Δ f ϵ ) Y \sim L(0, \frac{\Delta f}{\epsilon}) Y∼L(0,ϵΔf)满足 ϵ − \epsilon - ϵ−差分隐私,其中 Δ f \Delta f Δf表示敏感度, ϵ \epsilon ϵ 表示隐私预算。可以看到,隐私预算越小,噪声越大,结果可用性越小,隐私保护越好。
-
最后,我们来证明下这个过程
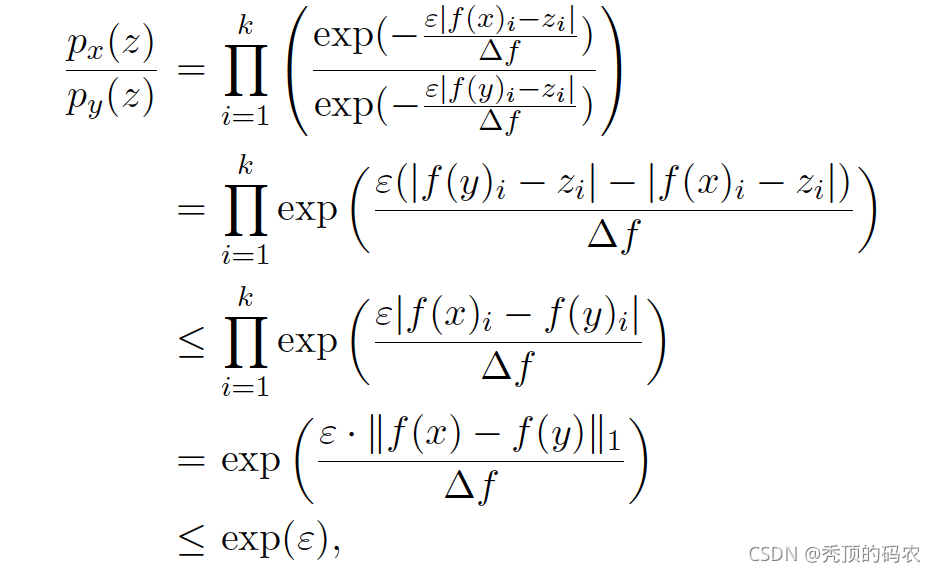
按照上面的公式顺序推导即可,重点是推导过程中进行了二次缩放,第一次缩放用到了绝对值不等式进行缩放,第二个缩放用到了上面我们的定义,由此我们就可以证明拉普拉斯分布可以用来实现差分隐私。
代码如下,git地址:https://github.com/dubaokun/code/tree/master/privacy/differential-privacy/laplace
1 import numpy as np
2
3 # 计算基于拉普拉斯分布的噪声
4 def laplace_noisy(sensitivety,epsilon):
5 n_value = np.random.laplace(0, sensitivety/epsilon, 1)
6 return n_value
7
8 # 计算基于拉普拉斯加噪的混淆值
9 def laplace_mech(data, sensitivety, epsilon):
10 for i in range(len(data)):
11 data[i] += laplace_noisy(sensitivety,epsilon)
12 return data
13
14 # 基于拉普拉斯分布的特性,如果想要分布震荡较小,需要将隐私预算epsilon的值设置较大
15 if __name__ =='__main__':
16 data = [1.,2.,3.]
17 sensitivety = 1
18 epsilon = 10
19 data_noisy = laplace_mech(data, sensitivety, epsilon)
20 for j in data_noisy:
21 print("Final Resulet = %.16f" % j)
输出结果
(tensorflow) dubaokun@ZBMAC-C02D5257M ~ python laplace_apply.py
Final Resulet = 1.1131262345421142
Final Resulet = 1.9423797734301973
Final Resulet = 3.0605257391487291
坊间传闻,苹果公司的epsilon值比较大,嘿嘿。
6 参考资料
- The Algorithmic Foundations of Differential Privacy
7 番外篇
个人介绍:杜宝坤,隐私计算行业从业者,从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。
框架层面:实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型支持。
业务层面:实现了业务侧的开门红业务落地,开创了新的业务增长点,产生了显著的业务经济效益。
个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:baokun06@163.com
8 未完待续
后续会继续补充差分隐私相关内容,敬请期待。














 1834
1834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









