







摘要
在使用pandas是,我们经常会用到groupby。我们groupby的目的其实就是对不同的分组进行单独的处理。pandas 已经为我们写好了一些groupby后常用的操作的。但是有很多情况下,我们在pandas库中找不到对应的实现方法。这个时候就可以用apply来高效的实现。下面会通过几个例子说明。
1.简单入门————分组求和
假设我们有数据集df如下
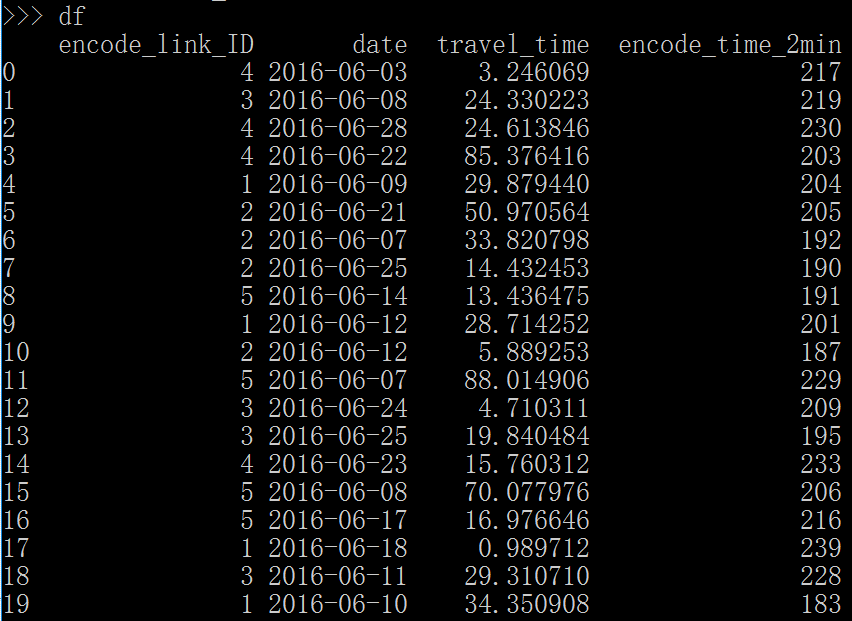
在第一列里面 encode_link_ID,我们需要对他进行分组,然后对每组进行travel_time的求和。具体过程可以描述如下图。
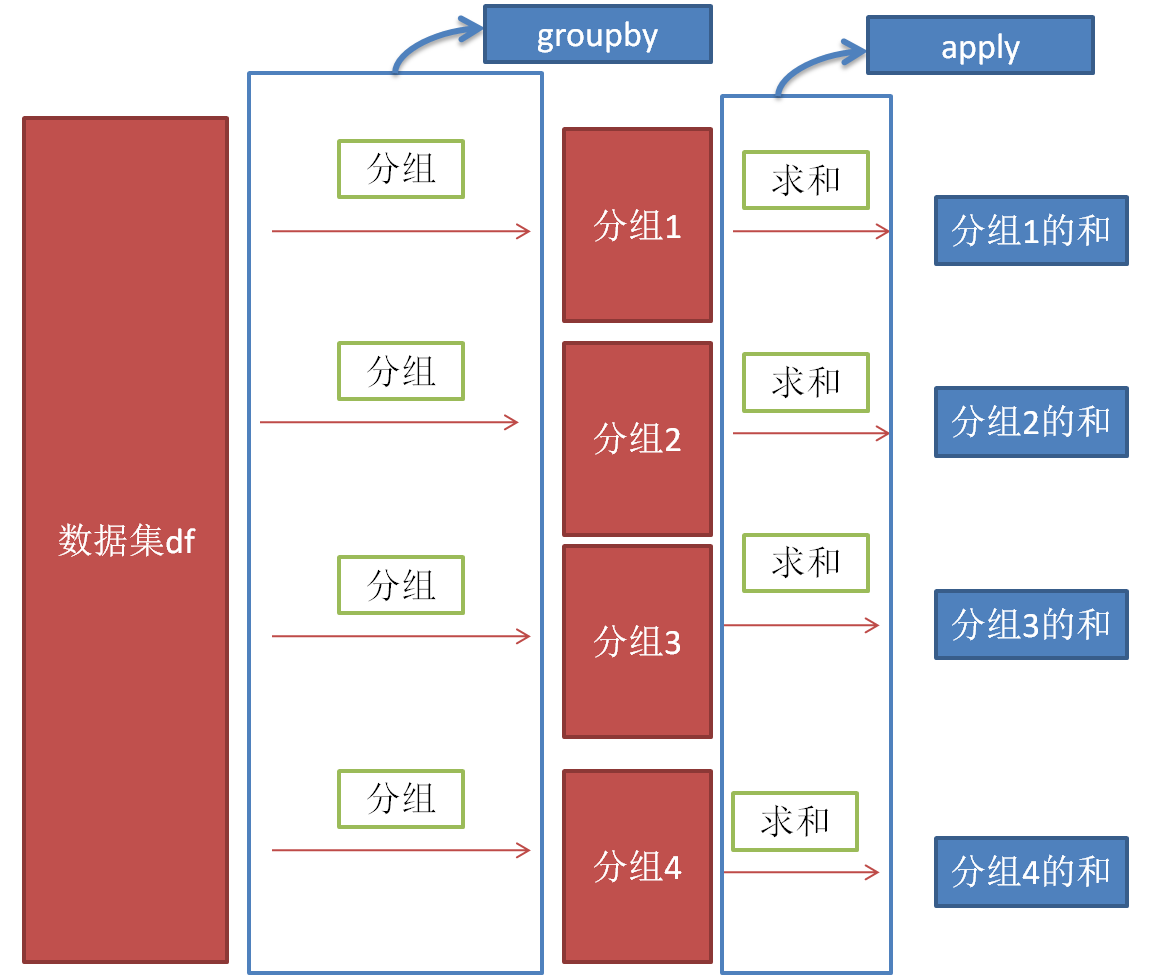
可以看到其实分两个过程,groupby和apply。其中apply要自己编写一个函数。在这种情况下,我们的求和函数是:
def groupby_sum(x):
x['travel_time'].sum()
return x我们的任务就是对df分组后某一列(travel_time)进行求和。
df.groupby(['encode_link_ID']).apply(groupby_sum)df.groupby(['encode_link_ID'])['travel_time'].sum()这个例子只是想以简单的方法,让大家体验一下apply的魅力。
另外,这里的分组不一定只是以某一列作为分组,还可以以多列。例如以df的encode_link_ID和date作为分组的依据
df.groupby(['encode_link_ID','date']).apply(groupby_sum)2.稍微难一点的例子
待续.......................















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









