






 本文介绍了推荐系统和CTR预估中常用的FM模型。通过引入向量表示解决特征交叉问题,减少参数数量并改善权重学习。对比多项式SVM,展示FM的优势。
本文介绍了推荐系统和CTR预估中常用的FM模型。通过引入向量表示解决特征交叉问题,减少参数数量并改善权重学习。对比多项式SVM,展示FM的优势。
摘要:
本文将要介绍一个在推荐、CTR中很常见的模型,FM(Factorization Machines)。
前言
我们首先回忆一下在推荐或者CTR预估的场景下我们经常用的模型是LR。具体来说我们熟悉的LR即如(0)式。
y^=w1x1+w2x2+...wnxn=∑ni=1wixi(0)
(0)
y
^
=
w
1
x
1
+
w
2
x
2
+
.
.
.
w
n
x
n
=
∑
i
=
1
n
w
i
x
i
接触过CTR或者推荐场景的可能很清楚,在这些场景下,我们通常会做一些交叉特征(cross feature)来增强LR的非线性以加强线性模型的表达能力。这种做法可以认为是在特征工程上下功夫。
而我们能否解放特征工程。从模型上下功夫来解决特征交叉的问题呢?
其实可以,比如说,我对(0)进行一点点修改,如(1)式子。
y^=∑ni=1wixi+∑ni=1∑nj=i+1wijxixj(1)
(1)
y
^
=
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
w
i
j
x
i
x
j
非常的直观,我们直接在线性模型的基础上增加多各个特征的乘积项。其表达的含义就是两个特征之间做交叉的意思。(1)式增加了
n(n+1)2
n
(
n
+
1
)
2
个参数。通常来说,会用到这种模型下的特征维度
n
n
都非常的大。所以这种如此暴力的方法(从式子(0)到式子(1)的变化)存在一定优化空间。
其实大量参数并非这种方法的最大问题,最大的问题在于由于推荐和CTR这两种场景下的特征非常的稀疏(sparse data),这会导致有大量的权重将得不到训练。可以直观上理解:当且仅当 xixj x i x j 同时不为0时,权重 wij w i j 在进行梯度下降时才会更新。否则每次梯度下降会保持不变。
为了解决这两个问题,第一个缩减参数的规模,第二个让交叉项的权重能够更好的学习,Steffen Rendle在提出了FM。
FM模型
上面提到FM是为了解决直接采用用多项式即式子(1)带来的几个问题所提出的模型。
那么FM到底是如何解决的呢?这里其实可以从多个角度来理解。这里采用一种个人比较理解的角度来说明。
假设我们给每个特征
xi
x
i
学习一个长度为
k
k
的向量表达。即向量
vi
v
i
为特征
xi
x
i
的
k
k
维表达。
那么我们在做特征组合的时候,比如组合与
xj
x
j
时,我们可以把学习的权重转化为学习
vi
v
i
和
vj
v
j
的向量点积的结果,
⟨vi,vj⟩
⟨
v
i
,
v
j
⟩
,也就是说(1)式改为:
y^=∑ni=1wixi+∑ni=1∑nj=i+1⟨vi,vj⟩xixj(2)
(2)
y
^
=
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
⟨
v
i
,
v
j
⟩
x
i
x
j
其中: ⟨vi,vj⟩=∑kf=1vi,f⋅vj,f ⟨ v i , v j ⟩ = ∑ f = 1 k v i , f ⋅ v j , f
我们这样做之后能够改善上面所提到部分权重得到不学习的问题。
这里我举一个例子。
比如我们有一个训练集,训练集中只有三个特征。其中一条样本如下
x1=1,x2=0,x3=1()
()
x
1
=
1
,
x
2
=
0
,
x
3
=
1
这个时候,我们如果采用式子(1)来学习时,我们需要学习其中的三个参数
w12
w
12
、
w13
w
13
、
w23
w
23
。
由于:仅有
x1x3=1
x
1
x
3
=
1
不为0,故仅有
w13
w
13
这个权重在梯度下降时得到了学习。那么在进行预测的时候,我们就利用了根本没有经过学习的、非常不准确的参数
w12
w
12
、
w23
w
23
。
而如果我们采用式子(2)来学习,我们有如下(方便起见,向量长度为 k=1 k = 1 )
虽然我们只有
x1x3=1
x
1
x
3
=
1
不为0,但是在梯度下降的时候,
v1,v3
v
1
,
v
3
都得到了学习。那么这个时候,我们在预测的时候,尽管
v2
v
2
没有得到学习。但是由于
⟨v1,v2⟩
⟨
v
1
,
v
2
⟩
和
⟨v2,v3⟩
⟨
v
2
,
v
3
⟩
中包含了我们学习过的
v1,v3
v
1
,
v
3
。所以从模型最终的效果上来看,尽管部分交叉特征从来出现过,但是由于其中包含有已经学习过的权重,所以还是能够使得这些交叉特征的权重是一个相对合理的值,而不是一个从未经过训练的值。
上面的权重的学习得到了改善,另外在进行预测时候的复杂度,其实也从
O(n2)
O
(
n
2
)
降到了线性
O(nk)
O
(
n
k
)
。
整个FM的复杂度其实来源于交叉特征部分。直观上看复杂度为
O(n2k)
O
(
n
2
k
)
,但是我们其实可以做一个简单的数学推导:
(这个推导直接摘论文里面的了,敲公式太累了- -!!!)
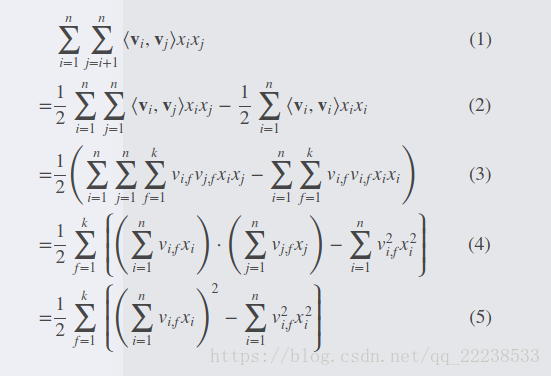
从式子(5)中可以看到,最外层的求和要计算 O(k)次 O ( k ) 次 ,里面一共需要计算 O(n) O ( n ) 次。所以总的复杂度为 O(nk) O ( n k ) 。所以整个复杂度变成了线性。
关于FM的训练
那么,我们对FM模型有了一定的认识之后,我们下一步需要考虑的就是如何进行训练,或者说如何求出上面所涉及到的一些参数。这里我们把式子(5)的推导结果带入式子(2)可以得到:
y^=∑ni=1wixi+12∑kf=1{(∑ni=1vi,fxi)2−∑ni=1v2i,fx2i}(3) (3) y ^ = ∑ i = 1 n w i x i + 1 2 ∑ f = 1 k { ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 }
对于分类任务,一般我们可以选择logloss作为我们的损失函数。那么对于logloss我们有(对于第
m
m
条样本):
其中:
p(m)=11+ey(m)^
p
(
m
)
=
1
1
+
e
y
(
m
)
^
把(3)式中的所有参数统一记为
θ,然后
θ
,
然
后
(6)式对
θ
θ
求导有:
∂L(y(m),y(m)^)∂θ=(y(m)−p(m))∂y(m)^∂θ(7)
(7)
∂
L
(
y
(
m
)
,
y
(
m
)
^
)
∂
θ
=
(
y
(
m
)
−
p
(
m
)
)
∂
y
(
m
)
^
∂
θ
最后对于 ∂y(m)^∂θ=⎧⎩⎨⎪⎪1xixi∑nj=1vj,fxj−vi,fx2iθ=w0θ=wiθ=vi,f(8) (8) ∂ y ( m ) ^ ∂ θ = { 1 θ = w 0 x i θ = w i x i ∑ j = 1 n v j , f x j − v i , f x i 2 θ = v i , f
有了每个参数的梯度之后,就可以利用SGD来对各个参数进行训练了。
可以看到,对于训练过程其复杂度也是线性的
O(nk)
O
(
n
k
)
。
FM与多项式的SVM对比
在FM的论文里有FM和SVM的一个简单的对比,其实总结起来。主要想表达就是,当SVM的核函数选择多项式核时即
d=2
d
=
2
的情况,SVM为下式:
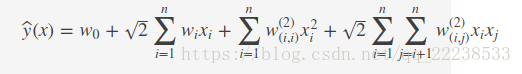
可以看到这个式子大体上就和式子(1)类似。所以对比FM和多项式核下的SVM其实就是文中一开始讨论的内容。
总结
到这里,我们可以稍微整理一下前面的内容。其实我们无非做了以下几点事情。
首先,我们阐述通过做特征工程来使得LR非线性表达能力增强的想法。后面,我们希望通过模型本身来做特征的交叉,阐述了直接利用二阶多项式的方法所带来的问题。最后,我们利用FM来解决上述所带来的一些问题。
所以FM其实很好的解决了两个问题
第一,将需要交叉特征部分的参数从
n(n+1)2
n
(
n
+
1
)
2
个降到了
nk
n
k
个。
第二,改善了交叉特征部分的权重的学习。
建议参考文章:美团技术点评-FFM

















 5509
5509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









