







仅处理文本的大语言模型实现多模态化
研究背景
-
大语言模型(LLM)在处理文本方面表现出色,但存在局限性,即如果没有针对图像、视频、音频等媒体类型进行进一步训练,就无法直接解读这些非文本信息。
新研究成果
-
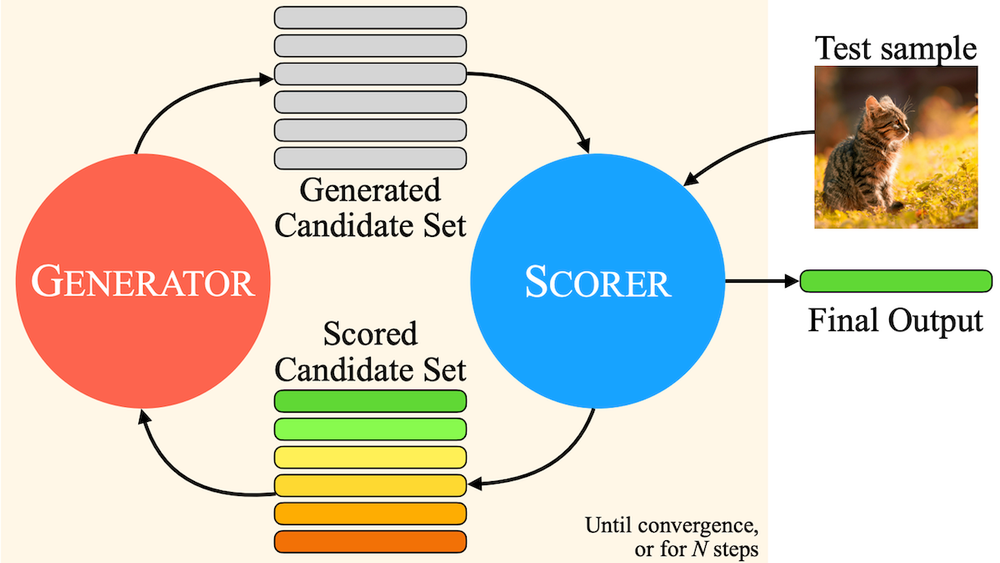
提出新方法:Meta、德克萨斯大学和加州大学伯克利分校的研究人员Kumar Ashutosh及其同事引入了多模态迭代大语言模型求解器(MILS)。该方法将仅处理文本的大语言模型与多模态嵌入模型相结合,能够在不进行额外训练的情况下,为图像、视频和音频生成字幕。
关键思路
-
大语言模型的能力:大语言模型可以生成文本,并能依据新信息对输出进行优化。
-
多模态嵌入模型的作用:多模态嵌入模型能够对给定文本与图像、视频或音频片段之间的相似度进行评分。
-
结合方式:大语言模型利用多模态嵌入模型给出的评分,对文本进行迭代再生,直到文本与相关媒体之间达到较高的匹配度,从而实现为媒体生成准确字幕的目的,且无需针对这些任务专门训练。
工作原理
-
初始生成:以Llama 3.1 8B模型为例,在给定提示词以及图像、视频或音频片段后,模型会生成3万到5万个初始字幕来启动整个过程。
-
相似度评估:针对每个字幕和媒体文件,不同的多模态模型会进行语义相似度评估。如SigLIP用于评估文本和图像,ViCLIP用于评估文本和视频,ImageBind用于评估文本和音频。
-
迭代生成:基于之前最相似的50个字幕,大语言模型生成新的字幕。
-
循环终止:系统重复上述相似度评估和迭代生成的步骤,直到得分最高的文本变化不大,或者大语言模型达到预定的迭代次数。
实验结果
-
评估指标:使用带有显式顺序的翻译评估指标(METEOR)来衡量性能,该指标通过检查同义词、同根词和单词顺序,判断生成字幕与真实字幕的匹配程度,分数越高越好。
-
图像字幕任务:在用于图像字幕生成的MSCOCO数据集上,MILS的METEOR得分达到15.0,而MeaCap模型的得分是14.1,MILS表现更优。
-
视频字幕任务:在评估视频字幕生成的MSR-VTT数据集上,MILS的METEOR得分达到14.4,而经过视频字幕生成训练的模型得分是11.3,MILS性能超过了专门训练的模型。
-
音频字幕任务:在评估音频字幕生成的Clotho数据集上,MILS的METEOR得分达到12.4,而ZerAuCap模型的得分是9.4,MILS同样表现出色。
研究意义
-
突破传统限制:像Aya Vision和Pixtral这样的零样本字幕生成模型需要使用成对的字幕和媒体数据进行训练,而MILS方法利用预训练的多模态模型,让大语言模型无需进一步训练就能创作多媒体字幕,突破了传统模型的限制。
-
推动合成数据应用:合成数据在训练人工智能模型中越来越重要,MILS使大语言模型能够合成优质字幕,进一步推动了合成数据在模型训练中的应用趋势。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











