







一、 Presto 简介
1.1.1 Presto 概念
Presto 是一个开源的分布式 SQL 查询引擎,数据量支持 GB 到 PB 字节,主要用来处理
秒级查询的场景。注意:虽然 Presto 可以解析 SQL,但它不是一个标准的数据库。不是MySQL、Oracle的代替品,也不能用来处理在线事务(OLTP)。
1.1.2 Presto 架构
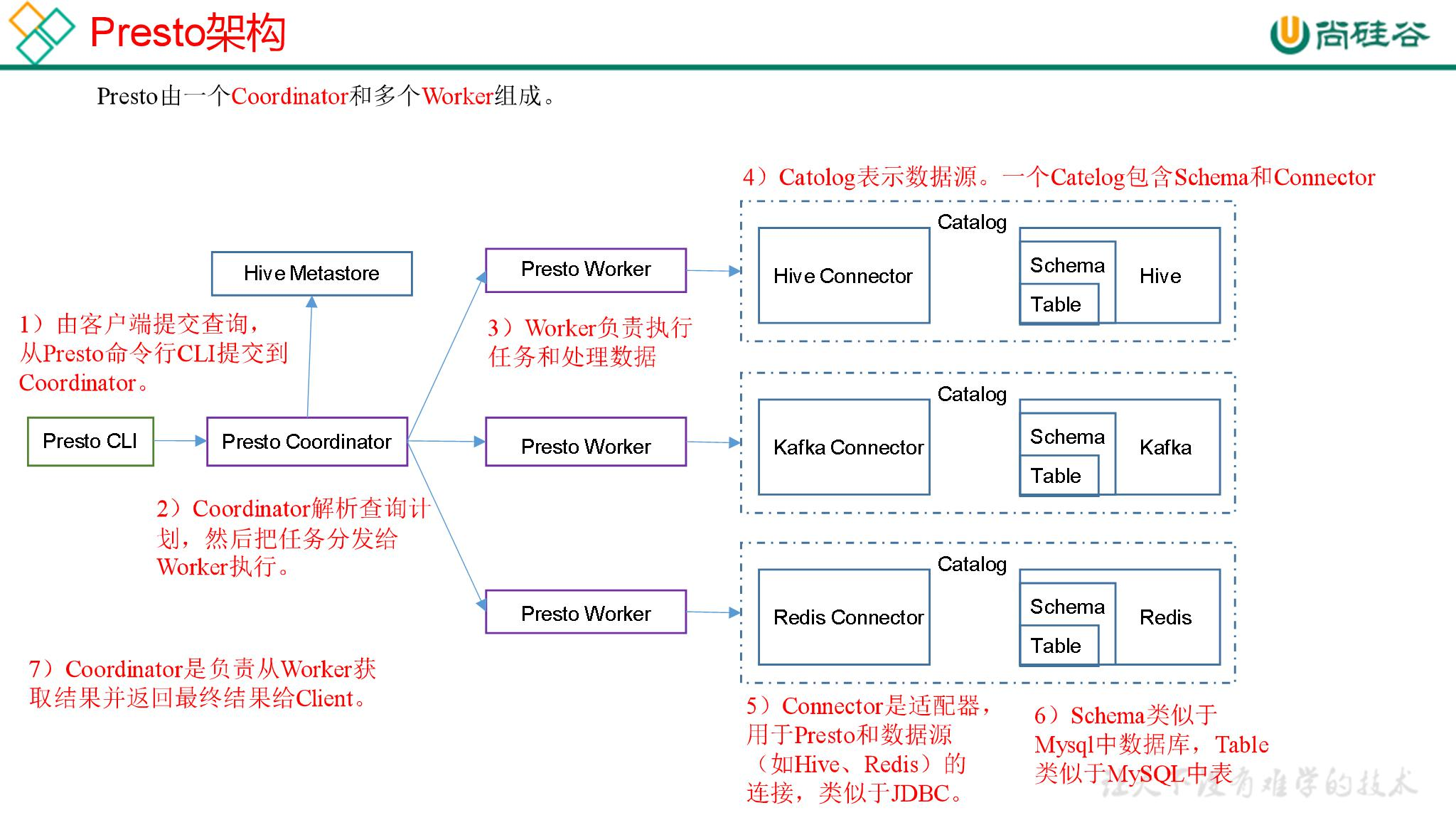
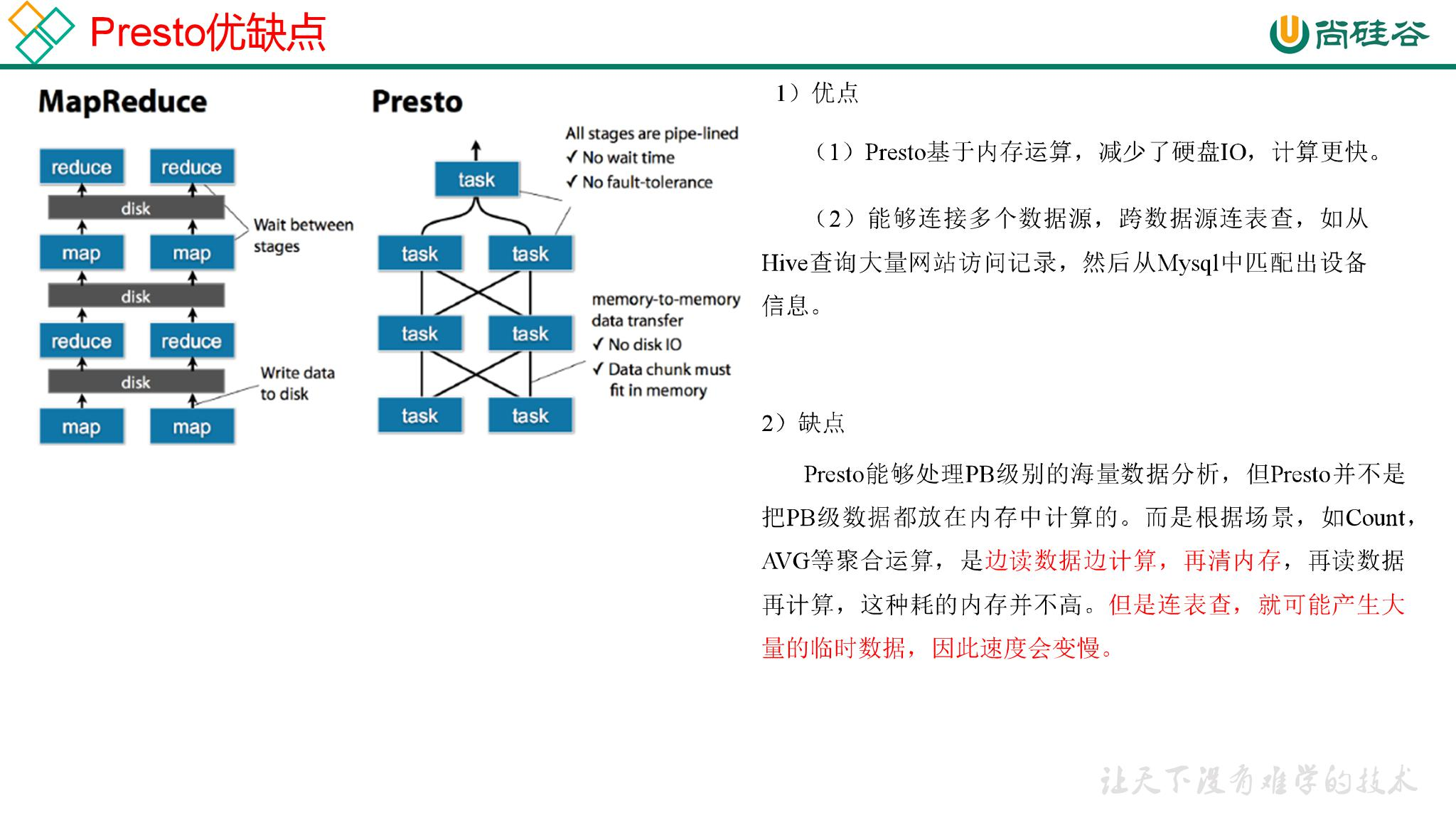
1.1.3 Presto 优缺点
1.2 Presto 安装
1.2.1 Presto Server
1.2.2 Presto 命令行 行 Client 安装
1.2.3 Presto 可视化 Client 安装
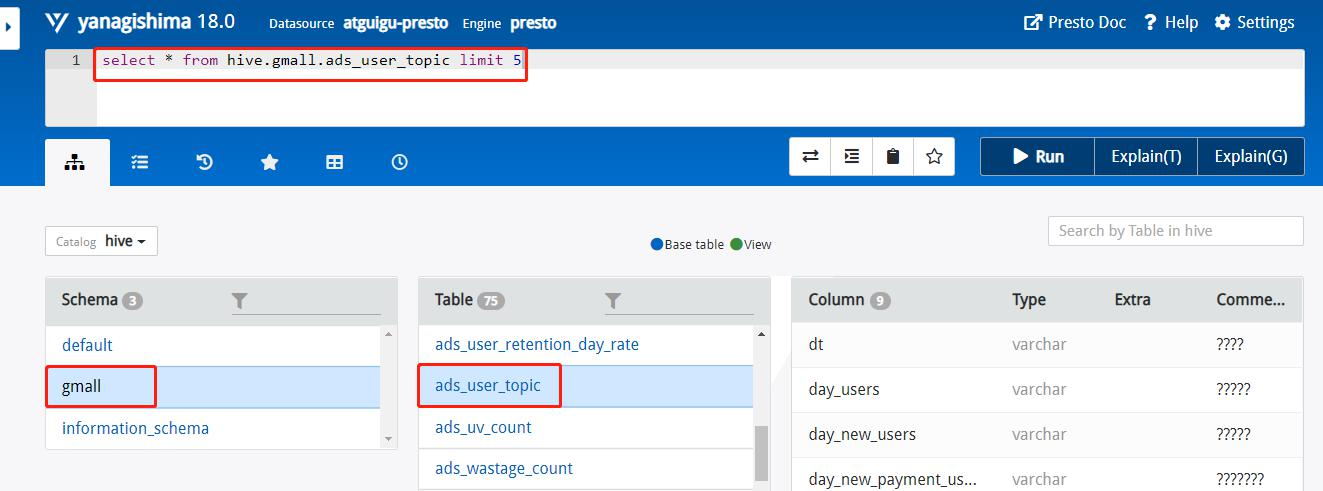
1.3 Presto 优化之 数据存储
1.3.1 合理设置分区
与 Hive 类似,Presto 会根据元数据信息读取分区数据,合理的分区能减少 Presto 数据
读取量,提升查询性能。
1.3.2 使用列式存储
Presto 对 ORC 文件读取做了特定优化,因此在 Hive 中创建 Presto 使用的表时,建议采
用 ORC 格式存储。相对于 Parquet,Presto 对 ORC 支持更好。
1.3.3 使用压缩
数据压缩可以减少节点间数据传输对 IO 带宽压力,对于即席查询需要快速解压,建议
采用 Snappy 压缩。
1.4 Presto 优化之询 查询 SQL
1.4.1 只选择使用的字段
由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取
所有字段
[GOOD]: SELECT time, user, host FROM tbl
[BAD]: SELECT * FROM tbl
1.4.2 过滤条件必须加上分区字段
对于有分区的表,where 语句中优先使用分区字段进行过滤。acct_day 是分区字段,
visit_time 是具体访问时间。
[GOOD]: SELECT time, user, host FROM tbl where acct_day=20171101 and visit_time=20171101
[BAD]: SELECT * FROM tbl where visit_time=20171101
1.4.3 Group By 语句优化
合理安排 Group by 语句中字段顺序对性能有一定提升。将 Group By 语句中字段按照每
个字段 distinct 数据多少进行降序排列。uid数量大于gender
[GOOD]: SELECT GROUP BY uid, gender
[BAD]: SELECT GROUP BY gender, uid
1.4.4 Order by 时使用 Limit
Order by 需要扫描数据到单个 worker 节点进行排序,导致单个 worker 需要大量内存。
如果是查询 Top N 或者 Bottom N,使用 limit 可减少排序计算和内存压力。
[GOOD]: SELECT * FROM tbl ORDER BY time LIMIT 100
[BAD]: SELECT * FROM tbl ORDER BY time
1.4.5 使用 Join 语句时将大表放在左边。和spark hive相反
Presto 中 join 的默认算法是 broadcast join,即将 join 左边的表分割到多个 worker,然后
将 join 右边的表数据整个复制一份发送到每个 worker 进行计算。如果右边的表数据量太大,
则可能会报内存溢出错误。
[GOOD] SELECT ... FROM large_table l join small_table s on l.id= s.id
[BAD] SELECT ... FROM small_table s join large_table l on l.id =s.id
1.5 注意事项
1.5.1 字段名引用
避免和关键字冲突:MySQL 对字段加反引号` 、Presto 对字段加双引号分割
当然,如果字段名称不是关键字,可以不加这个双引号。
1.5.2 时间函数
对于 Timestamp,需要进行比较的时候,需要添加 Timestamp 关键字,而 MySQL 中对
Timestamp 可以直接进行比较。
/*MySQL 的写法*/
SELECT t FROM a WHERE t > '2020-01-01 00:00:00';
/*Presto 中的写法*/
SELECT t FROM a WHERE t > timestamp '2020-01-01 00:00:00';
1.5.3 不支持 INSERT OVERWRITE 语法
Presto 中不支持 insert overwrite 语法,只能先 delete,然后 insert into。
1.5.4 PARQUET 格式
Presto 目前支持 Parquet 格式,支持查询,但不支持 insert。
二、 Presto的连接和使用
推荐使用DBeaver

驱动设置:

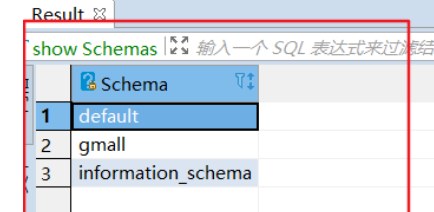
之后就连接到hive,输入指令可查看Schemas
![]()
输入sql即可进行查询:

Presto能够完成不能框架下的数据查询,例如进行mysql和hive的查询:

2、Presto JDBC使用(java)
maven依赖: <artifactId>presto-jdbc</artifactId>
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PrestoJDBC {
public static void main(String[] args) throws Exception {
//1.加载驱动
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
String url = "jdbc:presto://192.168.88.80:8090/hive/myhive";
Connection connection = null;
try {
//2.创建链接
connection =
DriverManager.getConnection("jdbc:presto://192.168.88.80:8090/hive/myhive","test",null
);
//3.statement
Statement stmt = connection.createStatement();
//4.执行SQL
ResultSet rs = stmt.executeQuery("show tables");
while (rs.next()) {
System.out.println(rs.getString(1));
}
ResultSet rs = stmt.executeQuery("SELECT * from employee limit 10");
while (rs.next()) {
System.out.println(rs.getString(1) + "\t" + rs.getString(2));
}
rs.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
//5.关闭连接
connection.close();
}
}
}
三、 Psto 、Impala 性能比较
https://blog.csdn.net/u012551524/article/details/79124532
测试结论:Impala 性能稍领先于 Presto,但是 Presto 在数据源支持上非常丰富,包括Hive、图数据库、传统关系型数据库、Redis 等
1、单表的聚合操作
Presto:count;1s
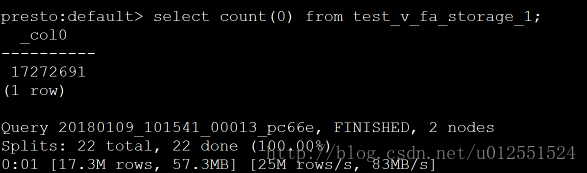
Impala:count:0.24s

Presto:count(distinct ):取了3次,分别是:4、3、3 (s)
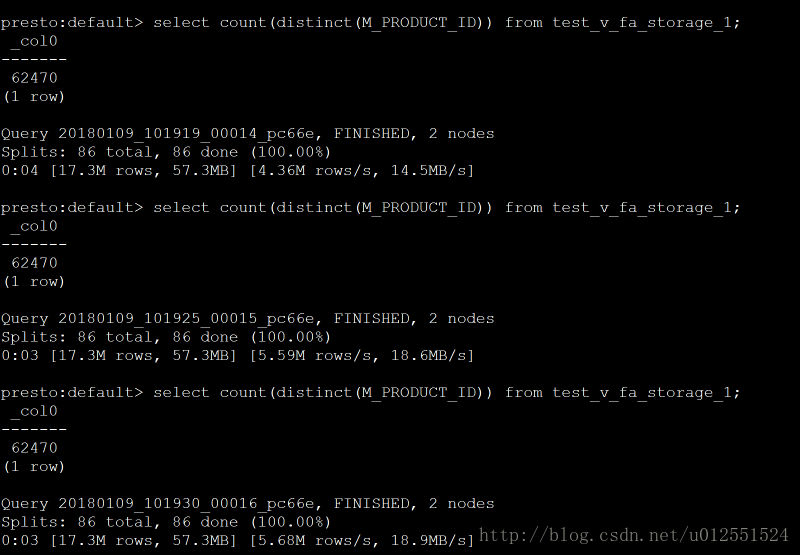
Impala:count(distinct ):取了3次:0.74、0.75、0.76(s)
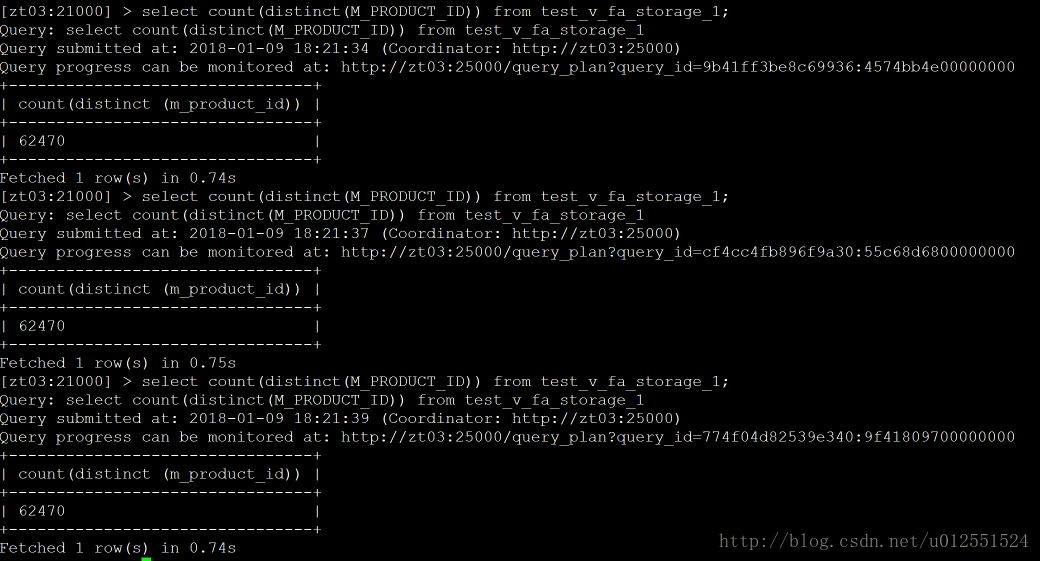
2、单值查询
Presto :查询一个ID的记录: 3次:6、5、6(s)
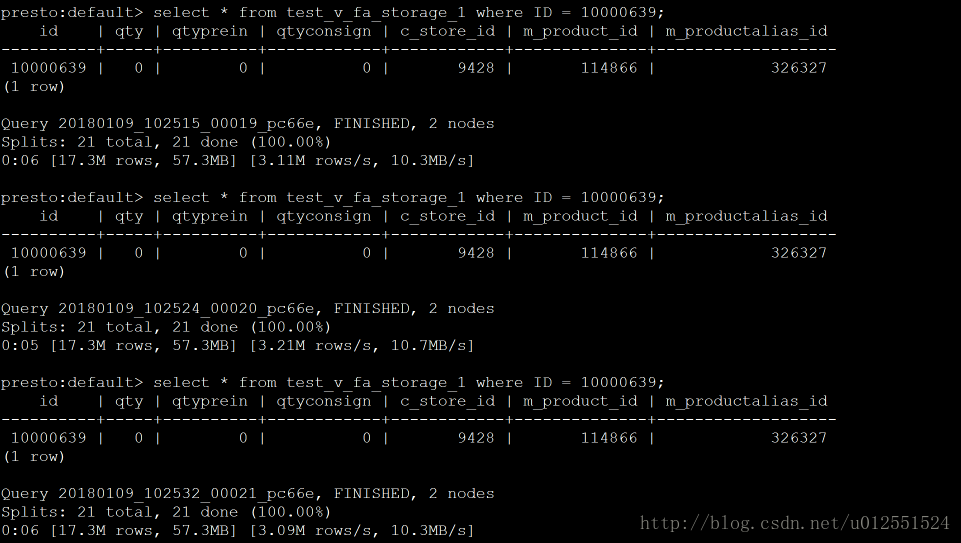
Impala: 3次都在1.7s左右
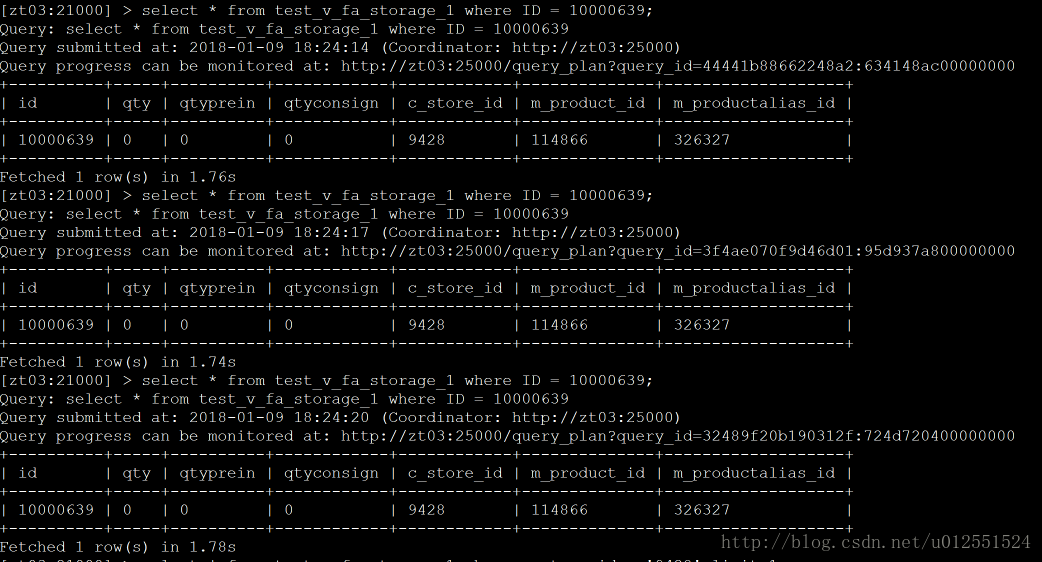
3、两表关联(2张2000W的表做join)
Presto: 3次结果:9、11、9
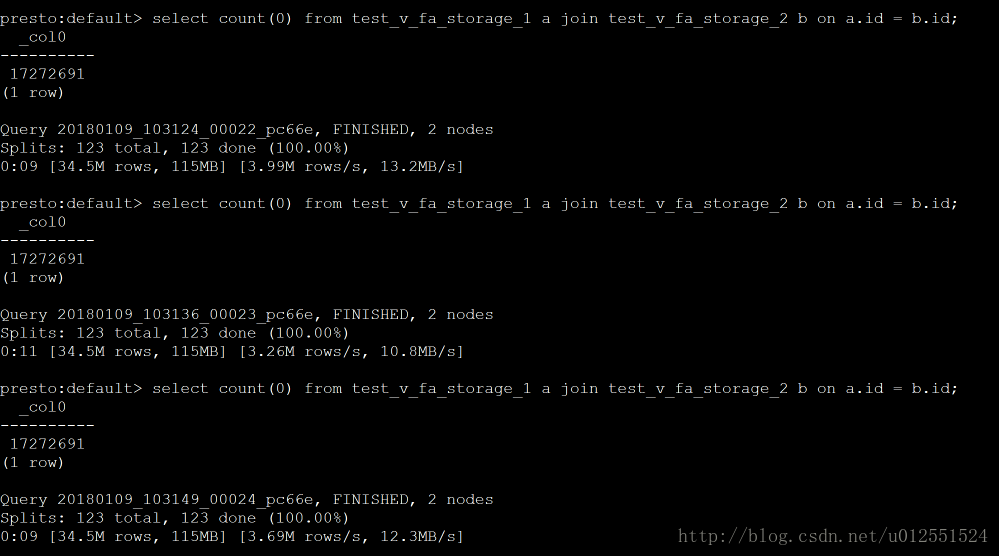
Impala:3次结果在7s左右
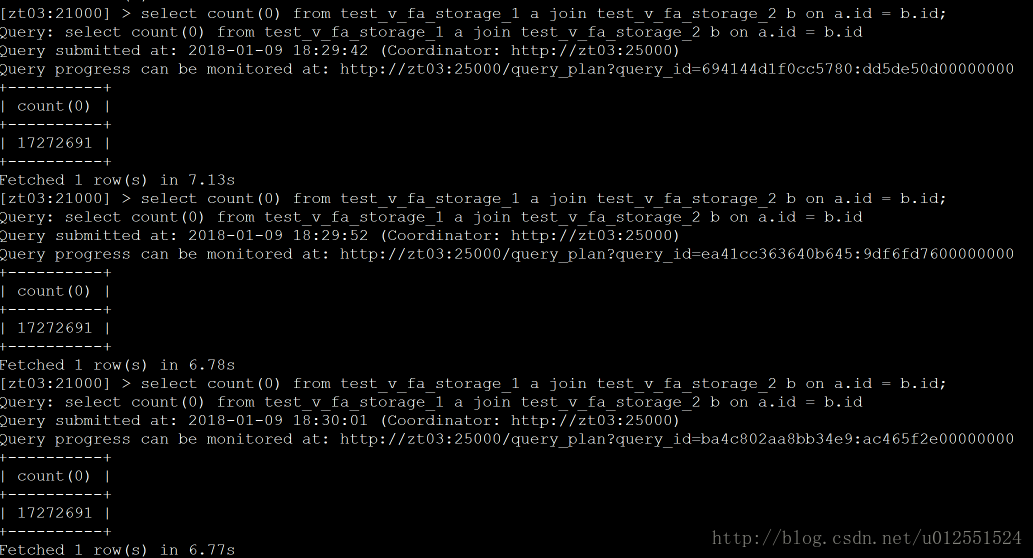
Presto: 4次结果:13、11、15、12(s)
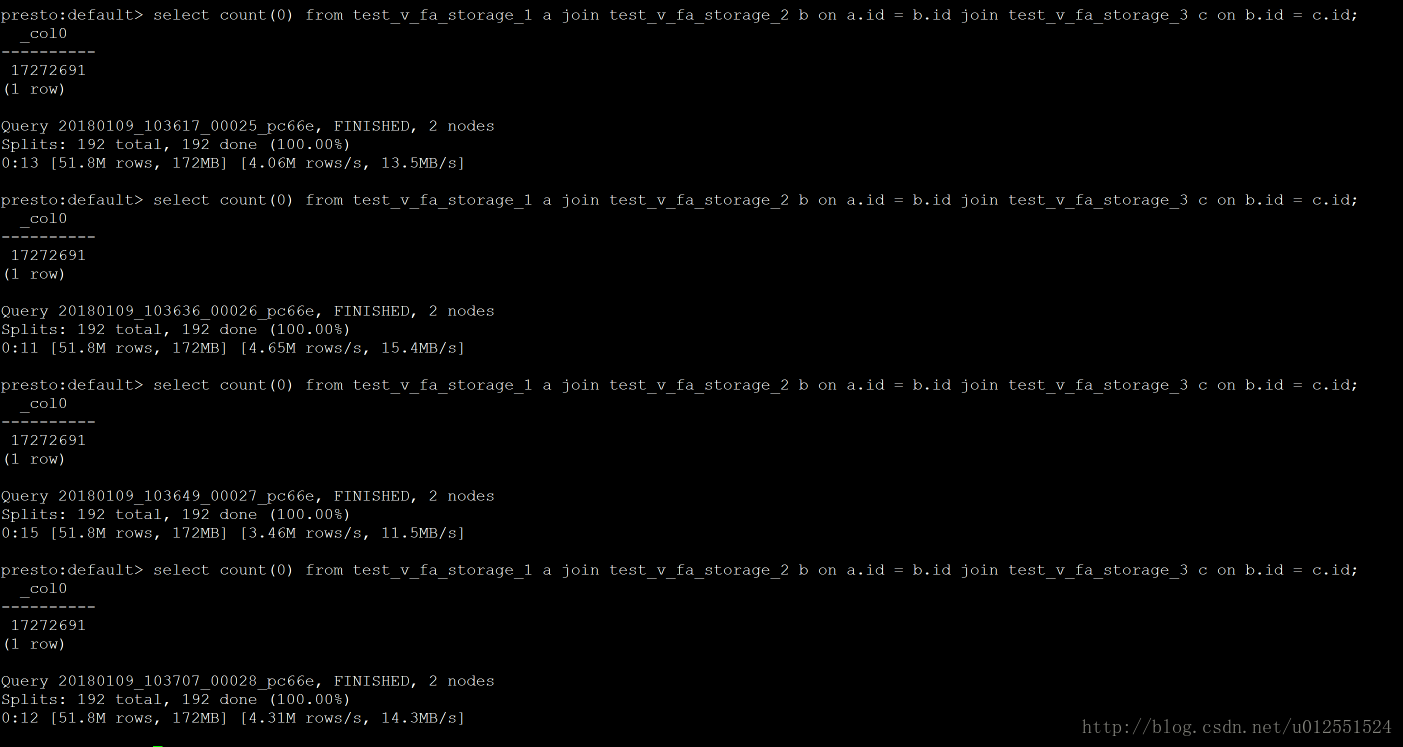
Impala: 3次结果在8.9s左右
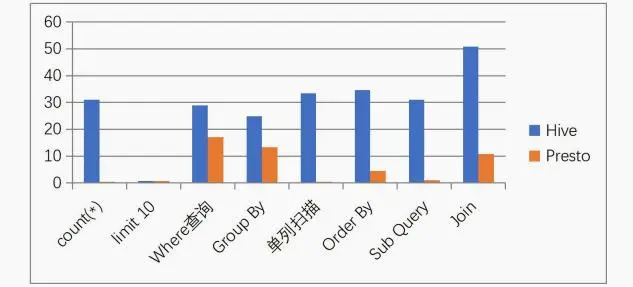
总结:这是一些场景下的查询效率的比较,数据量不是很大,但是能看出一些问题,他们的共同点就是吃内存,当然在内存充足的情况下,并且有规模适当的集群,性能应该会更可观,从上图可以看出Impala性能稍领先于presto,但是presto在数据源支持上非常丰富,包括hive、图数据库、传统关系型数据库、Redis等
缺点:这两种对hbase支持的都不好,presto 不支持,但是对hdfs、hive兼容性很好,其实这也是顺理成章的,所以数据源的处理很重要,针对hbase的二级索引查询可以用phoenix,效果也不错
测试结论:Impala 性能稍领先于 Presto,但是 Presto 在数据源支持上非常丰富,包括Hive、图数据库、传统关系型数据库、Redis 等
四、impala presto SparkSql性能测试对比
测试过程比较简单,分为四个场景sql查询:
| 查询id | 查询语句 | 数据量(压缩前) |
| query1 | select sum(pv) from d_op_behavior_host_text_snappy | 35G |
| query2 | select siteid,sum(pv) as pv1 from d_op_behavior_host_text_snappy where pv>0 group by siteid order by pv1 desc limit 11; | 35G |
| query3 | select count(*) from dwd.d_ad_3rd_party_fancy_all_data where thisdate='2015-11-10' and hour='17'; | 200G |
| query4 | select count(*) from dwd.d_ad_impression where thisdate>='2015-09-01' and thisdate<='2015-10-31' |
测试结果对比如下:
| 查询 | 工具 | 第一次执行时间 | 第二次执行时间 |
| query1 | impala | 4.82s | 5.56s |
| presto | 6s | 5s | |
| sparkSql | 13s | 9s | |
| query2 | impala | 12.79s | 12s |
| presto | 15s | 13s | |
| sparkSql | 20s | 23s | |
| query3 | impala | 挂掉 | 挂掉 |
| presto | 63s | 58s | |
| sparkSql | 88s | 77s | |
| query4 | impala | 131s | 148s |
| presto | 136s | 128s | |
| sparkSql | 187s | 188s |
测试结果对比如下:
impala与presto性能相当,SparkSql逊色不少。
目前看presto相比impala
1、与hive实时共享元数据,impala需要用另外定时任务广播元数据,新生成的数据,用impala不能立即查询。
2、没有出现操作大数据集有时挂掉的情况
3、presto与hive都由fackbook开源,兼容性应该会更好点

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











