







 超对称技术联合复旦等发布10亿参数的金融预训练模型BigBang Transformer[乾元],采用时序-文本跨模态架构,提升金融领域语言模型准确性。模型能识别时序数据变化,适用于金融量化投资、数据分析。同时,BBT模型构建了动态事理图谱,并提供了金融NLP评测数据集和API服务,促进金融AI生态发展。
超对称技术联合复旦等发布10亿参数的金融预训练模型BigBang Transformer[乾元],采用时序-文本跨模态架构,提升金融领域语言模型准确性。模型能识别时序数据变化,适用于金融量化投资、数据分析。同时,BBT模型构建了动态事理图谱,并提供了金融NLP评测数据集和API服务,促进金融AI生态发展。
目录
4.创新的预训练方法可大幅提高语言模型准确度:Similarity Sampling 和Source Prompt
5.通用的时间向量表示组件DWT-ST2Vec可以连接不同模型
7.应用BBT大模型构建量化投资新因子,BBT模型助力多因子策略开发
8.Benchmark 评测数据集:首个中文金融NLP评测数据集
9.开发者服务:向金融和非金融行业开发者开放API,构建BBT大模型开发者生态
超对称技术公司发布10亿参数金融预训练语言模型BigBang Transformer[乾元]。BBT大模型基于时序-文本跨模态架构,融合训练文本和时序两种模态数据,下游任务准确率较T5同级别模型提升近10%,并大幅提高时序预测的R2 score,跨模态架构能让语言模型识别时序数据的变化并通过人类语言来分析和阐述其发现。BBT模型可用于金融量化投资的因子挖掘,支撑多因子策略,以及广泛的数据可视化和物联网的时序数据分析等。BBT模型的目标是实现具备人类级别分析能力的预训练大模型,构建可在行业落地的通用人工智能架构。
1.通用大模型的缺陷
OpenAI的GPT-3,Google 的LaMDA, PaLM等千亿以上参数的语言模型和多模态大模型在写作,文字生成图片,对话等任务能接近乃至超越人类的智力水平。但是以上大模型有一些共同的缺陷。1. 大模型以通用的语料和数据进行预训练,在通用场景上表现良好,但是在专业领域有明显缺陷。所以GPT-3, 悟道,盘古等模型多用续写小说,写作诗歌,或者人机对话来展示大模型的能力。涉及到严肃的工作场景,则是只见打雷不见下雨。至今未见基于大模型在行业上的已经规模化应用的产品,背后的原因尚需进一步挖掘。仅用通用语料,未用行业数据进行预训练的大模型,其能力边界在哪里?如果超对称团队证明用行业数据训练的模型准确度更好,是否说明现有大模型的总体设计需要重新调整,才能获得大模型在不同行业的通用性?2 Dalle 2等预训练多模态模型在文字生成图像的应用取得惊人的效果,但是多模态模型在时序数据,表格文档数据等更实用更复杂的模态上进展不大,而这些模态占据了实际工作的大量场景。除了可以处理语言,语音,图像这三种常见模态,能读懂和分析数据也是人类智能的一种突出能力,而且人类能够并行处理语言,数据来获得结论。大模型是否也能实现人类智能对数据的分析能力,从而有效实现在工业场景的广泛应用。
超对称技术公司专注于开发算法和数据产品为金融,媒体,生产制造等行业提供服务。超对称公司针对金融投资领域的应用设计和训练了一个大规模参数预训练语言模型Big Bang Transformer乾元(BBT),目前发布了Base 版本2.2亿参数和Large 版本 10亿参数。同超对称团队还针对金融行业的预训练模型发布了一套评测数据集BBT-FinCUGE,开源于Github。BBT模型参考T5的Encoder+Decoder结构,以融合处理NLU和NLG的下游任务。超对称团队整理了一套金融行业的数据集,建立了一个跨模态联合训练文本和时序数据的基于Transformer的架构。
大模型是通往Artificial General Intelligence (AGI) 的一条道路。超对称公司认为具备数据分析能力是实现AGI的基础之一。超对称技术公司联合复旦大学计算机学院肖仰华知识工场实验室,浙江大学徐仁军实验室,南开大学和北师大人工智能学院的老师,在基础理论,架构,算法实现三方面推动AGI底层算法的研发,构建AGI在产业应用的底座。该项研究获得甘肃高台“东数西算”项目和南京江苏软件园在算力基础设施上的支持。
以Google 的T5框架为参考基准,BBT模型的实验验证了以下几个结论 1. 基于领域专业数据集预训练的大模型,比T5同级别参数模型平均下游任务准确率可以提高接近10%。 2. 不同下游任务的语料数据集比例对下游任务的准确度有影响。3. 基于下游任务类别提供Source Prompt的提示学习能大幅提高下游任务的准确度。4. BBT的时序模型进行多元时序预测,比普通的Transformer获得R2 score的大幅提升 5. 联合文本和时序数据数据进行训练,模型能读懂数字变化所对应的真实世界。
2.专注于融合训练时序-文本跨模态的预训练模型算法架构
传统的时序模型往往仅依赖时序本身的信息完成各种任务,而忽略了时序数据对外部信息的依赖。例如某一时刻股价、经济指标等数据的波动并不完全由这一时刻前的数据决定。语言模型具有强大的表征文本信息的能力,将语言模型与时序模型结合,既可以使得世界信息能够以文本的形式支撑时序任务的完成,又可以通过时序数据中包含的信息强化语言模型对信息的理解能力。为此超对称团队设计了基Transformer的时序-文本跨模态预训练模型,这是业内最早的专注于联合训练时序-文本二模态的预训练算法架构之一。预训练方式为通过T时刻前的文本信息和时序信息对T时刻的时序数据进行预测。时序数据和文本图像数据同时作为Embedding层输入Encoder一个双向的Transformer,输出向量进入的Decoder有NLU,NLG,Time Series三类。
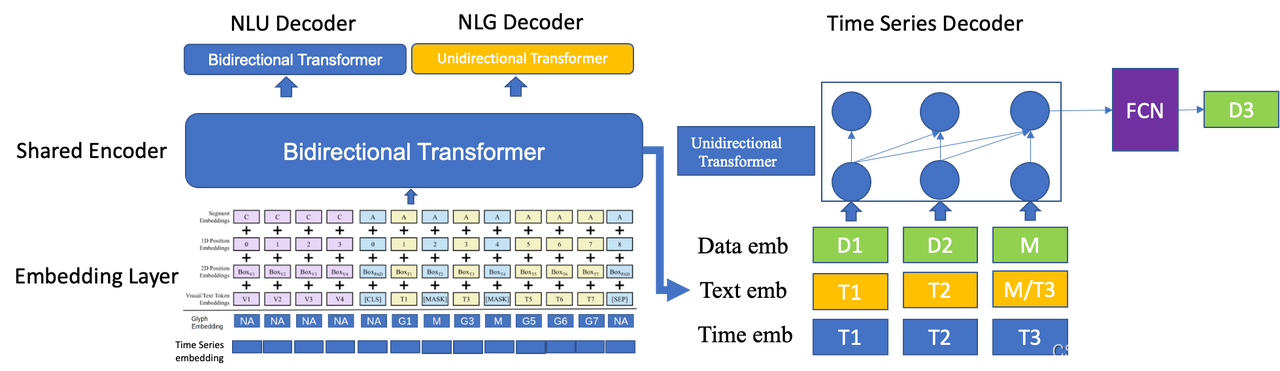
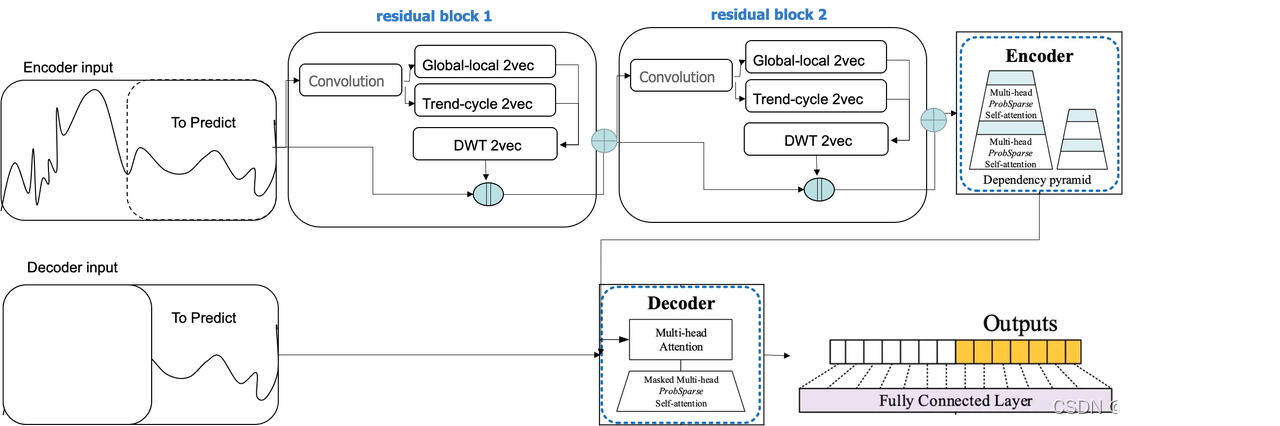
BBT模型设计了一个通用的将时间向量化输入Embedding层的模块。多元时间序列受到空间维度与时间维度两方面信号脉冲的影响,其被激活的时间、空间范围是一个连续的频谱,可大致分为低频局部脉冲、低频全局脉冲、高频局部脉冲和高频全局脉冲四方面分析这种影响。其中,“低频”/“高频”是指从时间视图描述了影响的激活范围,而“全局”/“局部”从空间视图描述了激活范围。“低频”即脉冲变化平稳,倾向于在较长时间内保持稳定;“高频”即脉冲变化剧烈;“全局”是指这种脉冲对所有时间序列产生类似的影响;“局部”是指脉冲只影响单个的时间序列,或对不同的时间序列施加不同的影响。基于此,超对称提出一种通用的、模型无关的、可学习的向量时间表示组件DWT-ST2Vec,可适用于多种模型结构与下游任务。该组件可从时空两个维度对序列的高频、低频分量进行分解,从而更加充分学习序列信息。
3.学术和工业界覆盖最完整,规模最大的金融投资类数据集
语料库的质量、数量和多样性直接影响语言模型预训练的效果,现有的中文金融预训练语言模型,例如FinBERT与英伟达发布的FinMegatron,其预训练语料在数量和多样性上十分有限。为了更好地推进中文金融自然语言处理(NLP)的发展,超对称搜集和爬取了几乎所有公开的和其他手段可以获得的中文金融语料数据,包括过去20年所有主流媒体平台发布的财经政治经济新闻,所有上市公司公告和财报,上千万份研究院和咨询机构历史上发布的所有研究报告,百万本金融经济政治等社会科学类书籍,40多个政府部位网站和地方政府网站的公告和文档,社交媒体平台用户发帖,从中清洗和整理了大规模中文金融语料库BBTCorpus,涵盖五大类别共300多GB,800亿Token的高质量多样化语料数据,是目前市面上覆盖最完整,规模最大的金融投资类数据集,具体的规模分布如表1所示。
| 类别 |
上市公司公告 |
研究报告 |
财经政治新闻 |
政府网站 |
社交媒体和社科书籍 |
总计 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











