










来源:本人公众号
原文解读见《多任务网络学习之注意力机制MTAN(一)》。
若有读者对多任务不太了解的,可阅读综述《多任务网络框架和训练策略介绍》。
在代码中通过注释的形式解读。
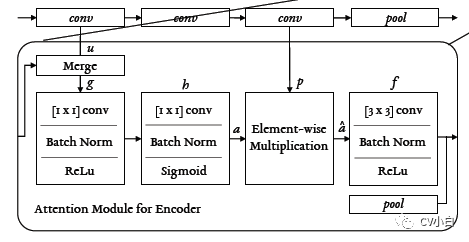
mtan思想,以resnet为例,如上图所示,图中的u和p,分别对应代码中的b和t:
-
得到每一层layer的b_i和t_i,即resnet.layer_i的倒数2个特征图;
-
若为第一个layer,则没有merge,通过对b_i进行g和h操作,得到a_mask_i;若i大于1,则将b_i和a_i_1 concate, 在对concate后的特征进行g和h操作,得到a_mask_i;
-
将a_mask_i和t_i做element-wise multiplication,得到a_hat_i;
-
做f操作,得到a_i;
-
i+1,重复2,3,4,遍历完每一个layer;
-
得到的一系列的a_i特征图,即为利用注意力机制后,得到的基于特定任务的特定特征图。
class MTANDeepLabv3(nn.Module):
def __init__(self):
super(MTANDeepLabv3, self).__init__()
backbone = ResnetDilated(resnet.__dict__['resnet50'](pretrained=True))
ch = [256, 512, 1024, 2048]
self.tasks = ['segmentation', 'depth', 'normal']
self.num_out_channels = {'segmentation': 13, 'depth': 1, 'normal': 3}
# 将resnet的encoder拆分为MTAN需要的输入,每一层都需要b和t。
# 后续的MTAN均是根据b和t计算。
self.shared_conv = nn.Sequential(backbone.conv1, backbone.bn1, backbone.relu1, backbone.maxpool)
# We will apply the attention over the last bottleneck layer in the ResNet.
self.shared_layer1_b = backbone.layer1[:-1]
self.shared_layer1_t = backbone.layer1[-1]
self.shared_layer2_b = backbone.layer2[:-1]
self.shared_layer2_t = backbone.layer2[-1]
self.shared_layer3_b = backbone.layer3[:-1]
self.shared_layer3_t = backbone.layer3[-1]
self.shared_layer4_b = backbone.layer4[:-1]
self.shared_layer4_t = backbone.layer4[-1]
# Define task specific attention modules using a similar bottleneck design in residual block
# (to avoid large computations)
# 计算attantion mask a,为省计算量,用bottleneck。
# 对应论文中的g和h操作
self.encoder_att_1 = nn.ModuleList([self.att_layer(ch[0], ch[0] // 4, ch[0]) for _ in self.tasks])
self.encoder_att_2 = nn.ModuleList([self.att_layer(2 * ch[1], ch[1] // 4, ch[1]) for _ in self.tasks])
self.encoder_att_3 = nn.ModuleList([self.att_layer(2 * ch[2], ch[2] // 4, ch[2]) for _ in self.tasks])
self.encoder_att_4 = nn.ModuleList([self.att_layer(2 * ch[3], ch[3] // 4, ch[3]) for _ in self.tasks])
# Define task shared attention encoders using residual bottleneck layers
# We do not apply shared attention encoders at the last layer,
# so the attended features will be directly fed into the task-specific decoders.
# 得到最终的a_hat
# 对应论文中的f操作
self.encoder_block_att_1 = self.conv_layer(ch[0], ch[1] // 4)
self.encoder_block_att_2 = self.conv_layer(ch[1], ch[2] // 4)
self.encoder_block_att_3 = self.conv_layer(ch[2], ch[3] // 4)
self.down_sampling = nn.MaxPool2d(kernel_size=2, stride=2)
# Define task-specific decoders using ASPP modules
self.decoders = nn.ModuleList([DeepLabHead(2048, self.num_out_channels[t]) for t in self.tasks])
def forward(self, x, out_size):
# Shared convolution
x = self.shared_conv(x)
# Shared ResNet block 1
u_1_b = self.shared_layer1_b(x)
u_1_t = self.shared_layer1_t(u_1_b)
# Shared ResNet block 2
u_2_b = self.shared_layer2_b(u_1_t)
u_2_t = self.shared_layer2_t(u_2_b)
# Shared ResNet block 3
u_3_b = self.shared_layer3_b(u_2_t)
u_3_t = self.shared_layer3_t(u_3_b)
# Shared ResNet block 4
u_4_b = self.shared_layer4_b(u_3_t)
u_4_t = self.shared_layer4_t(u_4_b)
# Attention block 1 -> Apply attention over last residual block
# g和h操作
a_1_mask = [att_i(u_1_b) for att_i in self.encoder_att_1] # Generate task specific attention map
# element-wise multiplication
a_1 = [a_1_mask_i * u_1_t for a_1_mask_i in a_1_mask] # Apply task specific attention map to shared features
# f操作和降采样
a_1 = [self.down_sampling(self.encoder_block_att_1(a_1_i)) for a_1_i in a_1]
# Attention block 2 -> Apply attention over last residual block
# merge,g和h操作,得到a
a_2_mask = [att_i(torch.cat((u_2_b, a_1_i), dim=1)) for a_1_i, att_i in zip(a_1, self.encoder_att_2)]
a_2 = [a_2_mask_i * u_2_t for a_2_mask_i in a_2_mask]
a_2 = [self.encoder_block_att_2(a_2_i) for a_2_i in a_2]
# Attention block 3 -> Apply attention over last residual block
a_3_mask = [att_i(torch.cat((u_3_b, a_2_i), dim=1)) for a_2_i, att_i in zip(a_2, self.encoder_att_3)]
a_3 = [a_3_mask_i * u_3_t for a_3_mask_i in a_3_mask]
a_3 = [self.encoder_block_att_3(a_3_i) for a_3_i in a_3]
# Attention block 4 -> Apply attention over last residual block (without final encoder)
a_4_mask = [att_i(torch.cat((u_4_b, a_3_i), dim=1)) for a_3_i, att_i in zip(a_3, self.encoder_att_4)]
a_4 = [a_4_mask_i * u_4_t for a_4_mask_i in a_4_mask]
# Task specific decoders
out = [0 for _ in self.tasks]
for i, t in enumerate(self.tasks):
out[i] = F.interpolate(self.decoders[i](a_4[i]), size=out_size, mode='bilinear', align_corners=True)
if t == 'segmentation':
out[i] = F.log_softmax(out[i], dim=1)
if t == 'normal':
out[i] = out[i] / torch.norm(out[i], p=2, dim=1, keepdim=True)
return out
def att_layer(self, in_channel, intermediate_channel, out_channel):
return nn.Sequential(
nn.Conv2d(in_channels=in_channel, out_channels=intermediate_channel, kernel_size=1, padding=0),
nn.BatchNorm2d(intermediate_channel),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=intermediate_channel, out_channels=out_channel, kernel_size=1, padding=0),
nn.BatchNorm2d(out_channel),
nn.Sigmoid())
def conv_layer(self, in_channel, out_channel):
downsample = nn.Sequential(conv1x1(in_channel, 4 * out_channel, stride=1),
nn.BatchNorm2d(4 * out_channel))
return Bottleneck(in_channel, out_channel, downsample=downsample)














 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









