









论文团队:华中科技大学(白翔)
论文链接:https://arxiv.org/pdf/1911.08947.pdf
工程链接:https://github.com/MhLiao/DB
该算法的特点就是:后处理速度快,与PANNet相比,可以节省差不多一半的时间(在本人台式机cpu运行);
目录
2.可微二值(differentiable binarization)
3.自适应阈值(Adaptive threshold)(略)
4.可变形卷积(Deformable convolution)
1.算法的整体框架

主要三个步骤:首先:图像输入特征提取主干,提取特征;
其次: 特征金字塔上采样到相同的尺寸,并进行特征级联到特征F;
然后:特征F用于预测概率图(probability map P)和阈值图(threshold map T);
最后:通过P和F计算近似二值图(approximate binary map B^)
论文算法主要包括了以下几部分:
2.可微二值(differentiable binarization)
标准二值处理:
一般使用分割网络(segmentation network)产生的概率图(probability map P),将P转化为一个二值图P,当像素为1的时候,认定其为有效的文本区域,同时二值处理过程:
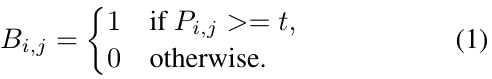
i和j代表了坐标点的坐标,t是预定义的阈值;
但是标准的二值处理是不可微的,这样分割网络不可以在训练过程中优化。所以作者提出了可微二值:
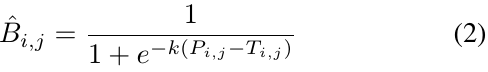
![]() 就是近似二值图;T是自适应的阈值图;k是膨胀因子(经验性设置k=50).
就是近似二值图;T是自适应的阈值图;k是膨胀因子(经验性设置k=50).
使用二值交叉熵作为一个例子。定义,
,则正样本标签和负样本标签的loss分别为:
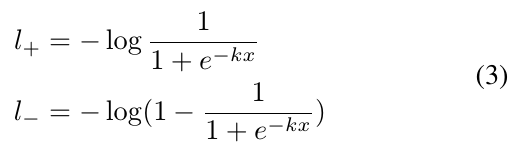
这样就很好计算反传值,(详细可参照论文自己推演);

3.自适应阈值(Adaptive threshold)(略)
4.可变形卷积(Deformable convolution)
作者使用可变形卷积的原因:可变形卷积可以提供更加丰富的感受野,这对于极端比例的文本检测效果有益;
展示了普通的卷积和可变形卷积的差异:
图中以两个3*3的卷积为例,可以看到对于普通卷积来说,卷积操作的位置都是固定的。而可变形卷积因为引入了offset,所以卷积操作的位置会在监督信息的指导下进行选择,可以较好的适应目标的各种尺寸,形状,因此提取的特征更加丰富并更能集中到目标本身。

(自己的理解:在比例较正常时,是不是可以去掉,毕竟普通卷积的计算量还是小于可变形卷积)
5.标签的产生(Lable generation)

标签产生受PSENet的启发,正样例区域产生通过收缩polygon从G到Gs,使用Vatti clipping algoithm,补偿公式计算
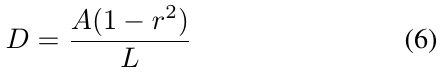
D:offset;L:周长;A:面积;r:收缩比例,设置为0.4;
5.loss
![]()
Ls:收缩文本实例的loss;Lb:二值化之后的收缩文本实例loss;Lt:二值化阈值map的loss;
论文中,作者的Ls和Lb使用的是二值交叉熵loss(但是在工程代码中,Ls使用的是dice loss),Lt使用的是L1 loss;
6.后处理

D‘就是扩展补偿,A’是收缩多边形的面积,L‘就是收缩多边形的周长,r’作者设置的是1.5;
(注意r‘的值在DBNet工程中不是1.5,而在我自己的数据集上,参数设置为1.3较合适,大家训练的时候可以根据自己模型效果进行调整)
在推理过程中,可以使用概率图(probability map)或者近似概率图(approximate binary map)产生文本边缘框。为了提升效率,作者使用了概率图。产生预测结果分为三个步骤:
1)概率图通过一个阈值获得二值图;2)通过二值图获得连接区域;3)收缩区域通过膨胀再扩展回来,使用公式(10);
7.Experiments
数据集:SynthText包含800k图片;MLT-2017数据集,包含九种语言的多语言数据集,7200张训练图片,1800张验证图片,9000张测试图片。ICDAR 2015数据集包括1000张训练图片和500张测试图片;MSRA-TD500数据集多语言数据集,包括英语和中文。300张训练样本,200张测试样本。CTW1500 数据集,样本特点是弯曲文字,包括1000张训练样本,500张测试样本;Total-Text dataset数据集包括各种形状的文本,包括水平,多方向和弯曲文字。包括1255张训练图片和3000张测试图片。
数据增强:1)随机旋转角度(-10°,10°);2)随机裁剪;3)随机翻转。所有图片都被resize为640*640进行训练;
Ablation study
Differentiable binarization:

通过表1可以得到:使用DB提升了Resnet-18和resnet-50的性能。最关键,推理阶段可以移除DB,这样节省推理时间。
Deformable convolutional
通过表1可以得到:使用deformable convolution可以提升模型性能;
Supervision of threshold map

通过表2可得:通过给阈值图增加监督,模型性能有所提升;
Comparisons with previous methods

图7是本文方法的多语言多方向的可视化结果;


通过表3和表4结果的比较,可以得出本文方法在性能和速度上都得到了比较好的结果。
Multi-language text detection


通过表6和表7可以得到,“DB-Resnet-50”在精度和速度上都比之前的方法优秀;
8.Limitation
文本收缩有助于检测文本重叠(前提是文本中心未重叠),但是当文本实例的中心重叠时,该文方法就没办法处理好了。
9.Conclusion
作者提出来了可微二值化处理(DB),实验结论显示,该文的方法在速度和精度上都获得了很好的结果;
















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











