







代码地址:
1. 概述
由于分割网络的结果可以准确描述诸如扭曲文本的场景,因而基于分割的自然场景文本检测方法变得流行起来。基于分割的方法其中关键的步骤是其后处理部分,这步中将分割的结果转换为文本框或是文本区域。这篇文章的文本检测方法也是基于分割的,但是通过提出Differenttiable Binarization module(DB module)来简化分割后处理步骤(加了一个边的预测),并且可以设定自适应阈值来提升网络性能。文章的方法在现有5个数据上在检测精度与速度上均表现为state-of-art。在换用轻量级的backbone(ResNet-18)之后可以将检测帧率提升到62FPS,其与其它一些文本检测算法的性能与速率关系见图1所示。
文章方法与其它一些方法的对比:

传统意义上基于分割的文本检测算法其流程如图2中的蓝色箭头所示。在传统方法中得到分割结果之后采用一个固定的阈值得到二值化的分割图,之后采用诸如像素聚类的启发式算法得到文本区域。

而文章的检测算法流程是图2中红色箭头所示的,其中不同的地方也是这篇文章核心的一点就是在阈值选取上,通过网络去预测图片每个位置处的阈值,而不是采用一个固定的值,这样就可以很好将背景与前景分离出来。但是这样的操作会给训练带来梯度不可微的情况,对此对于二值化提出了一个叫做Differentiable Binarization来解决不可微的问题。
在解决了阈值可微的为题之后,文章将分割算法与DB module组合起来构建了一个快速且鲁棒的文本检测器,这个方法的亮点表现在:
- 1)在几个开源的数据集上对于水平、倾斜、扭曲的文本表现出了更好的检测性能;
- 2)由于不需要繁琐的后处理,直接使用DB module产生适应的阈值使得网络提速很多,并且DB module能够生成更加鲁棒的分割二值图;
- 3)DB module在轻量级的backbone(ResNet-18)也具有很好的性能;
- 4)DB module在做inference的时候可以直接移除,而不会损失性能,因而减少了这部分的时间与资源消耗;
2. 方法设计
2.1 网络结构
文章的网络结构见图3所示,输入的图像经过不同stage的采样之后获得不同大小的特征图,之后这些由这些特征图构建特征金字塔,从而构建出统一尺度(相比原图像stride=4)的特征图 F F F,之后这个特征图用于预测分割概率图 P P P与阈值图 T T T,之后将 P , T P,T P,T结合得到估计的二值图 B ^ \hat{B} B^。在训练的时候 P , B P,B P,B是使用同样的表现作训练,而 T T T会使用单独的阈值图作训练。

2.2 二值化操作
标准二值化(Standard Binarization,SB)
对于分割特征图 P ∈ R H ∗ W P\in R^{H*W} P∈RH∗W,使用下面的方式进行二值化处理:
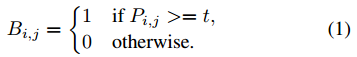
可微的二值化(Differentiable Binarization,DB)
由于公式1中的二值方法不是可微的,因而就不能在分割网络中随着训练的过程进行优化,为了解决这个问题文章提出了一个函数来近似这个二值化过程,既是:
B ^ i , j = 1 1 + e − k ( P i , j − T i , j ) \hat{B}_{i,j}=\frac{1}{1+e^{-k(P_{i,j}-T_{i,j})}} B^i,j=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









