







A Unified Optimization Framework of ANN-SNN Conversion: Towards Optimal Mapping from Activation Values to Firing Rates
Jiang, Haiyan, et al. “A unified optimization framework of ANN-SNN conversion: towards optimal map** from activation values to firing rates.” International Conference on Machine Learning. PMLR, 2023.
ANN-SNN 转换的统一优化框架:实现从激活值到发放率的最佳映射
Abstract
脉冲神经网络 (Spiking Neural Networks, SNNs) 因其高效能和快速推理能力而备受关注,但由于脉冲信号的离散性,从零开始训练SNNs较为困难。另一种方法是将人工神经网络 (Artificial Neural Network, ANN) 转换为SNN,被称为ANN-SNN转换。
目前,现有的ANN-SNN转换方法通常涉及用新激活函数重新设计ANN,而不是使用传统的ReLU,然后将其转换为SNN。然而,这些方法没有考虑到使用ReLU的常规ANN和定制ANN之间可能的性能损失。
在本文中,我们提出了一种统一的ANN-SNN转换优化框架,同时考虑了性能损失(performance loss)和转换误差(conversion error)。为此,我们引入了 SlipReLU 激活函数,它是 threshold-ReLU 和阶跃函数的加权和。
理论分析表明,在位移值 δ ∈ [ − 0.5 , 0.5 ] δ ∈ [−0.5, 0.5] δ∈[−0.5,0.5] 的范围内,转换误差(conversion error)可以为零,而不是固定的0.5。我们在CIFAR数据集上评估了我们的SlipReLU方法,结果表明SlipReLU在准确性和延迟方面优于当前的ANN-SNN转换方法和监督训练方法。
据我们所知,这是 第一个只使用一次时间步长进行SNN推理的ANN-SNN转换方法 。代码可在 HaiyanJiang/SNN_Conversion_unified 获得。
1. Introduction(背景介绍)
脉冲神经网络 (Spiking Neural Networks, SNNs) 是一种受生物启发的神经网络,基于生物上合理的脉冲神经元模型来处理实时信号 (Hodgkin & Huxley, 1952; Izhikevich, 2003)。
由于其在神经形态硬件上的低功耗和快速推理的显著优势 (Roy et al., 2019),SNNs 正成为运行大规模深度人工神经网络 (Artificial Neural Networks, ANNs) 的主要候选者。
SNNs 中最常用的神经元模型是积分-发放 (Integrate-and-Fire, IF) 神经元模型 (Liu & Wang, 2001)。在这种模型中,当神经元的累积膜电位超过阈值电压时,SNN 中的每个神经元才会发出脉冲。否则,它在当前时间步内保持不活跃。这使得SNNs更类似于生物神经网络。
与ANNs相比,事件驱动的SNNs具有二值化/脉冲激活值,这在专用神经形态硬件上实现时,能耗更低。SNNs的另一个显著特性是其输入和输出的伪同时性(pseudo-simultaneity),可以在时空范式中进行推理。
与传统的ANNs一次呈现整个输入向量并逐层处理以生成一个输出值相比,SNNs的前向传递可以高效地处理流时间变化的输入。
通常,有两种主要方法来获得SNN:
(1) 从零开始训练SNN (Wu et al., 2018; Neftci et al., 2019; Zenke & Vogels, 2021)从零开始训练使用基于梯度的监督优化方法,例如反向传播,将SNNs视为特殊的ANNs。
(2) ANN-SNN转换 (Cao et al., 2015; Diehl et al., 2015; Deng & Gu, 2021),即将ANN转换为SNN。
由于SNNs中二值激活函数的不可微性,通常使用替代梯度 (Neftci et al., 2019)。然而,这种方法只能在小到中等规模的数据集上训练SNNs (Li et al., 2021)。
另一方面,ANN-SNN转换是一种在大规模数据集上获得性能与ANNs相当的深度SNNs的有效方法。
有两种主要的ANN-SNN转换机制:
(1) 一步转换,即在不改变预训练ANN架构的情况下将其转换为SNN,例如 Diehl et al. (2015); Li et al. (2021)
(2) 两步转换,涉及重新设计ANN,训练它并将其转换为SNN,例如 Cao et al. (2015); Deng & Gu (2021); Bu et al. (2021)。
重新设计指的是:替换ReLu激活函数
在本文中,我们研究了一种两步法的ANN-SNN转换方法。
这种方法通过用新的激活函数替换常规的ReLU激活函数来重新设计ANN,训练定制的ANN,并随后将其转换为SNN。
偏离常规ANN过多的定制ANN会降低其性能,导致转换的SNN继承其性能损失。然而,现有的ANN-SNN转换研究 从未考虑 过常规ANN和定制ANN之间的性能退化 。
为了实现高准确率和低延迟的SNN (例如1或2个时间步),我们 首次同时 考虑常规ReLU ANN和定制ANN之间的性能损失(performance loss)以及转换误差(conversion error)。
我们的主要贡献总结如下:
(1) 我们将ANN-SNN转换公式化为一个统一的优化问题,同时考虑ANN性能损失和转换误差。
(2) 我们提出在定制ANN中使用SlipReLU激活函数,以尽量减少层间转换误差,同时保持定制ANN的性能尽可能接近常规ANN。
(3) SlipReLU方法涵盖了一系列 将源ANN中的激活值映射到目标SNN中的发放率的激活函数 。许多最先进的最佳ANN-SNN转换方法可以看作是我们提出的SlipReLU方法的特例。
(4) 通过两个定理,我们证明了预期的ANN-SNN转换误差在位移值 δ ∈ [ − 0.5 , 0.5 ] δ ∈ [−0.5, 0.5] δ∈[−0.5,0.5] 的范围内理论上可以为零,而不是固定的0.5。实验结果进一步验证了所提出的SlipReLU方法的有效性。
2. Preliminaries(准备工作)
在本研究中,我们研究了图像数据集上的分类问题,记为 ( x , y ) ∈ D (x, y) ∈ D (x,y)∈D ,其中每个图像 x 与一个真实类标签 y 相关联。我们的目标是通过优化标准交叉熵 (CE) 损失来训练一个神经网络 f : x → f ( x ) f: x → f(x) f:x→f(x) ,它可以是ANN或SNN。
CE损失定义为 L C E ( y , p ) = − ∑ i = 1 C y i l o g ( p i ) L_{CE}(y, p) = − ∑^C_{i=1} y_i log(p_i) LCE(y,p)=−i=1∑Cyilog(pi)
其中 y i y_i yi 是真实标签, p i p_i pi 是网络预测 p i = f ( x i ) p_i = f(x_i) pi=f(xi) 。
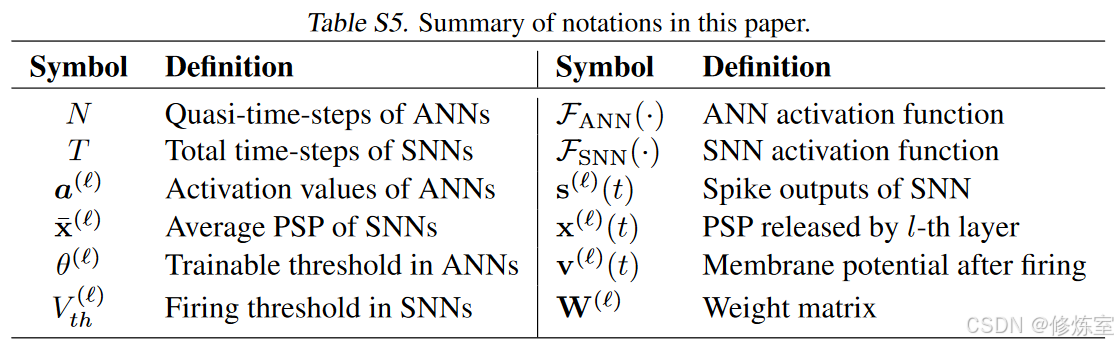
为了一致性,我们使用符号 f f f 来表示源ANN和目标SNN的相同共享结构。此外,我们用 F A N N F_{ANN} FANN 和 F S N N F_{SNN} FSNN 分别表示ANN和SNN模型中使用的激活函数。有关符号,请参见表S5。
ANN神经元模型
在传统ANN中,整个输入向量一次性被输入到网络中,并通过连续的激活函数逐层处理以生成单个输出值。ANN中模拟神经元的前向传递可以表示为:
a ( ℓ ) = F A N N ( z ( ℓ ) ) = F A N N ( W ( ℓ ) a ( ℓ − 1 ) ) , (1) a^{(ℓ)} = F_{ANN}(z^{(ℓ)}) = F_{ANN}(W^{(ℓ)}a^{(ℓ−1)}),\tag{1} a(ℓ)=FANN(z(ℓ))=FANN(W(ℓ)a(ℓ−1)),(1)
其中 z ( ℓ ) z^{(ℓ)} z(ℓ) 和 a ( ℓ ) a^{(ℓ)} a(ℓ) 分别是第 ℓ ℓ ℓ 层的预激活(pre-activation)和后激活(post-activation)向量, W ( ℓ ) W^{(ℓ)} W(ℓ) 是权重矩阵, F A N N ( ⋅ ) F_{ANN}(·) FANN(⋅) 是ANN的激活函数。
在传统的人工神经网络(ANN)中,每一层的神经元接收来自前一层的输出,并进行加权求和,然后通过激活函数处理得到该层的输出。具体来说:
- a ( ℓ − 1 ) a^{(ℓ-1)} a(ℓ−1) 是第 ℓ − 1 ℓ-1 ℓ−1 层的后激活向量,也就是前一层神经元经过激活函数处理后的输出。
- W ( ℓ ) W^{(ℓ)} W(ℓ) 是第 ℓ ℓ ℓ 层的权重矩阵,它将第 ℓ − 1 ℓ-1 ℓ−1 层的输出 a ( ℓ − 1 ) a^{(ℓ-1)} a(ℓ−1) 线性组合得到第 ℓ ℓ ℓ 层的预激活向量 z ( ℓ ) z^{(ℓ)} z(ℓ)。
- z ( ℓ ) z^{(ℓ)} z(ℓ) 是第 ℓ ℓ ℓ 层的预激活向量,即神经元接收到的加权输入。
- F A N N ( ⋅ ) F_{ANN}(·) FANN(⋅) 是ANN的激活函数,它对预激活向量 z ( ℓ ) z^{(ℓ)} z(ℓ) 进行非线性变换得到第 ℓ ℓ ℓ 层的后激活向量 a ( ℓ ) a^{(ℓ)} a(ℓ) 。
因此,公式
a ( ℓ ) = F A N N ( z ( ℓ ) ) = F A N N ( W ( ℓ ) a ( ℓ − 1 ) ) a^{(ℓ)} = F_{ANN}(z^{(ℓ)}) = F_{ANN}(W^{(ℓ)}a^{(ℓ-1)}) a(ℓ)=FANN(z(ℓ))=FANN(W(ℓ)a(ℓ−1)) 表示了在ANN中模拟神经元的前向传递过程:
- W ( ℓ ) a ( ℓ − 1 ) W^{(ℓ)}a^{(ℓ-1)} W(ℓ)a(ℓ−1) 表示第 ℓ ℓ ℓ 层的预激活向量,即前一层的后激活向量 a ( ℓ − 1 ) a^{(ℓ-1)} a(ℓ−1) 经过权重矩阵 W ( ℓ ) W^{(ℓ)} W(ℓ) 线性变换后的结果。
- F A N N ( W ( ℓ ) a ( ℓ − 1 ) ) F_{ANN}(W^{(ℓ)}a^{(ℓ-1)}) FANN(W(ℓ)a(ℓ−1)) 表示该预激活向量经过激活函数 F A N N ( ⋅ ) F_{ANN}(·) FANN(⋅) 处理后得到的第 ℓ ℓ ℓ 层的后激活向量 a ( ℓ ) a^{(ℓ)} a(ℓ) 。
为什么会和前一层有关呢?
这是因为神经网络的 每一层都依赖于前一层的输出作为其输入 。每一层的后激活向量 a ( ℓ ) a^{(ℓ)} a(ℓ) 都是由前一层的后激活向量 a ( ℓ − 1 ) a^{(ℓ-1)} a(ℓ−1) 经过当前层的权重矩阵 W ( ℓ ) W^{(ℓ)} W(ℓ) 和激活函数 F A N N ( ⋅ ) F_{ANN}(·) FANN(⋅) 计算得到的结果。
这种层层传递信息的方式使得神经网络能够逐层提取和组合特征,最终实现复杂的输入输出映射关系。
SNN神经元模型
与ANN不同,SNN在每一层中使用二值激活 (即脉冲)。
为了弥补二值激活的有限表示能力,SNN中引入了时间维度或延迟。SNN中的前向传递输入以事件流的形式呈现,并在 T T T 个时间步内重复前向传递以产生最终结果。
在本研究中,我们考虑了SNN的积分-发放 (Integrate-and-Fire, IF) 神经元模型 (Cao et al., 2015; Bu et al., 2021; Deng & Gu, 2021)。目标SNN中PSP (突触后电位) 的前向传播等效于源ANN中模拟神经元的前向计算。
然后我们推导了PSP的前向传播。在时间步 t t t ,第 ℓ ℓ ℓ 层的IF神经元从上一层接收其二值输入 x ( ℓ − 1 ) ( t ) x^{(ℓ−1)}(t) x(ℓ−1)(t) ,并根据以下公式临时更新其膜电位:
u ( ℓ ) ( t ) = v ( ℓ ) ( t − 1 ) + W ( ℓ ) x ( ℓ − 1 ) ( t ) , (2) u^{(ℓ)}(t) = v^{(ℓ)}(t − 1) + W^{(ℓ)}x^{(ℓ−1)}(t), \tag{2} u(ℓ)(t)=v(ℓ)(t−1)+W(ℓ)x(ℓ−1)(t),(2)
- v ( l ) ( t − 1 ) v^{(l)}(t - 1) v(l)(t−1):表示第 l l l 层神经元在时间步 t − 1 t - 1 t−1 的膜电位。
- W ( l ) W^{(l)} W(l):表示第 l l l 层神经元的权重矩阵。
- x ( l − 1 ) ( t ) x^{(l-1)}(t) x(l−1)(t):表示第 l − 1 l - 1 l−1 层神经元在时间步 t t t 的输出(即输入到第 l l l 层的值)。
该公式的物理意义是:在时间步 t t t,第 l l l 层神经元的膜电位 v ( l ) ( t ) v^{(l)}(t) v(l)(t) 由前一时间步 t − 1 t - 1 t−1 的膜电位 v ( l ) ( t − 1 ) v^{(l)}(t - 1) v(l)(t−1) 以及当前时间步 t t t 的输入加权和 W ( l ) x ( l − 1 ) ( t ) W^{(l)} x^{(l-1)}(t) W(l)x(l−1)(t) 决定。
这一步的计算结果会被用于后续的阈值判断,从而决定神经元是否发放脉冲。
其中
- v ( ℓ ) ( t ) v^{(ℓ)}(t) v(ℓ)(t) 是时间步 t t t 的膜电位
- u ( ℓ ) ( t ) u^{(ℓ)}(t) u(ℓ)(t) 是用于确定从 v ( ℓ ) ( t − 1 ) v^{(ℓ)}(t − 1) v(ℓ)(t−1) 到 v ( ℓ ) ( t ) v^{(ℓ)}(t) v(ℓ)(t) 更新的临时中间变量。
如果临时中间电位 u i ( ℓ ) ( t ) u^{(ℓ)}_i(t) ui(ℓ)(t) 超过膜阈值 V t h ( ℓ ) V^{(ℓ)}_{th} Vth(ℓ),它将产生脉冲输出 s i ( ℓ ) ( t ) = 1 s^{(ℓ)}_i(t) = 1 si(ℓ)(t)=1 。否则,不会释放任何脉冲 s i ( ℓ ) ( t ) = 0 s^{(ℓ)}_i(t) = 0 si(ℓ)(t)=0。
s i ( ℓ ) ( t ) = H ( u i ( ℓ ) ( t ) − V t h ( ℓ ) ) = { 1 i f u i ( ℓ ) ( t ) ≥ V t h ( ℓ ) 0 o t h e r w i s e (3) s^{(ℓ)}_i(t) = H(u^{(ℓ)}_i(t) − V^{(ℓ)}_{th}) = \left\{\begin{matrix}1 & if\ u^{(ℓ)}_i(t) \ge V^{(ℓ)}_{th} \\0 & otherwise\end{matrix}\right. \tag{3} si(ℓ)(t)=H(ui(ℓ)(t)−Vth(ℓ))={ 10if ui(ℓ)(t)≥Vth(ℓ)otherwise(3)
向量 s i ( ℓ ) ( t ) = { s i ( ℓ ) ( t ) } s^{(ℓ)}_i(t) = \{s^{(ℓ)}_i(t) \} si(ℓ)(t)={ si(ℓ)(t)} 收集了第 ℓ ℓ ℓ 层在时间 t t t 所有神经元的脉冲。
注意,不同层的 V t h ( ℓ ) V^{(ℓ)}_{th} Vth(ℓ) 可以不同。膜电位通过减法重置机制更新 (Rueckauer et al., 2017; Han et al., 2020),即如果神经元发放 s i ( ℓ ) ( t ) = 1 s^{(ℓ)}_i(t) = 1 si(ℓ)(t)=1 ,则临时膜电位 u i ( ℓ ) ( t ) u^{(ℓ)}_i(t) ui(ℓ)(t) 减去阈值 V t h ( ℓ ) V^{(ℓ)}_{th} Vth(ℓ) ,
v ( ℓ ) ( t ) = u ( ℓ ) ( t ) − s i ( ℓ ) ( t ) V t h ( ℓ ) (4) v^{(ℓ)}(t) = u^{(ℓ)}(t) − s^{(ℓ)}_i(t) V^{(ℓ)}_{th} \tag{4} v(ℓ)(t)=u(ℓ)(t)−si(ℓ)(t)Vth(ℓ)(4)
如果当前第 ℓ ℓ ℓ 层的神经元产生脉冲,它将传递一个无权重的PSP x ( ℓ ) ( t ) x^{(ℓ)}(t) x(ℓ)(t) 作为输入到下一层,类似于 Deng & Gu (2021),
x ( ℓ ) ( t ) = s ( ℓ ) ( t ) V t h ( ℓ ) x^{(ℓ)}(t) = s^{(ℓ)}(t)V^{(ℓ)}_{th} x(ℓ)(t)=s(ℓ)(t)Vth(ℓ)
至于SNN的第一层输入和最后一层输出,我们不像 Li et al. (2021) 那样采用任何脉冲机制。我们 直接将静态图像编码为时间动态脉冲作为第一层的输入,从而防止Poisson编码引入的不必要信息丢失 。对于最后一层输出,我们仅集成突触前输入,并且不发放任何脉冲。
在脉冲神经网络(SNN)的最后一层通常只集成突触前的输入(即膜电位或突触电位),而不再发送脉冲,这是因为SNN的输出需要转换为实际的数值结果,如分类任务中的概率分布或类别标签。这种方法可以简化计算,并且更符合传统人工神经网络(ANN)的输出形式。
为什么不发送脉冲
- 数值稳定性:
在传统ANN中,最后一层通常使用激活函数(如softmax或sigmoid)来 生成输出概率分布或直接的数值结果 。如果在SNN中最后一层继续发送脉冲,这些脉冲信号需要被进一步处理以得到数值结果。这可能引入额外的复杂性和不稳定性。
2. 计算效率:
- 集成突触前的输入(如累积膜电位)可以直接转换为数值输出,避免了继续模拟脉冲发放和传输的过程,从而提高计算效率。
3. 兼容性:
- 大多数任务(如图像分类)最终需要数值结果,将SNN的最后一层直接输出为数值形式(如膜电位的累积值)更容易与现有的评估方法兼容。如何得到SNN的输出结果
在SNN中,最后一层的输出通常是通过集成膜电位(或突触电位)得到的。具体步骤如下:
- 膜电位积累:
- 在最后一层,每个神经元集成来自前一层的突触输入,形成其膜电位。这个膜电位在整个推理过程中不断累积。- 膜电位转换为数值输出:
- 累积的膜电位直接用于计算输出。例如,对于分类任务,可以使用累积的膜电位来计算类别分数。- 数值结果的处理:
- 将这些膜电位转化为实际输出。例如,可以对累积的膜电位应用softmax函数,得到每个类别的概率分布。示例
假设有一个三分类任务,SNN的最后一层有三个神经元,对应三个类别。每个神经元的累积膜电位分别为 u 1 u_1 u1 , u 2 u_2 u2 和 u 3 u_3 u3。以下是得到最终输出结果的步骤:
- 累积膜电位:
- 在推理过程中,每个神经元累积其膜电位。例如,经过多次时间步后,得到 u 1 = 5.0 u_1 = 5.0 u1=5.0, u 2 = 2.0 u_2 = 2.0 u2=2.0, u 3 = 3.5 u_3 = 3.5 u3=3.5 。- 计算类别分数:
- 直接使用这些累积的膜电位作为类别分数。- 应用softmax:
- 将这些分数通过softmax函数转化为概率分布:
P ( y = i ) = e u i ∑ j = 1 3 e u j P(y=i) = \frac{e^{u_i}}{\sum_{j=1}^{3} e^{u_j}} P(y=i)=∑j=13eujeui
例如:
P ( y = 1 ) = e 5.0 e 5.0 + e 2.0 + e 3.5 , P ( y = 2 ) = e 2.0 e 5.0 + e 2.0 + e 3.5 , P ( y = 3 ) = e 3.5 e 5.0 + e 2.0 + e 3.5 P(y=1) = \frac{e^{5.0}}{e^{5.0} + e^{2.0} + e^{3.5}}, \quad P(y=2) = \frac{e^{2.0}}{e^{5.0} + e^{2.0} + e^{3.5}}, \quad P(y=3) = \frac{e^{3.5}}{e^{5.0} + e^{2.0} + e^{3.5}} P(y=1)=e5.0+e2.0+e3.5e5.0,P(y=2)=e5.0+e2.0+e3.5e2.0,P(y=3)=e5.0+e2.0+e3.5e3.5- 确定最终分类结果
根据计算得到的概率分布,选择概率最高的类别作为最终分类结果。例如:
P ( y = 1 ) = 0.786 , P ( y = 2 ) = 0.039 , P ( y = 3 ) = 0.175 P(y=1)=0.786,P(y=2)=0.039,P(y=3)=0.175 P(y=1)=0.786,P(y=2)=0.039,P(y=3)=0.175 。
那么类别 𝑦=1 的概率最高,最终分类结果就是类别 1。
3. 统一的ANN-SNN转换优化框架
在本节中,我们提出了一个ANN-SNN转换的统一优化框架,并对转换误差进行了分析。我们的统一框架解决了转换SNN性能与使用新激活函数的定制ANN和使用ReLU激活函数的常规ANN之间引入的偏差之间的权衡。
转换后的SNN性能由源ANN性能和转换误差共同决定 。之前的ANN-SNN转换方法只关注最小化转换误差,而不考虑定制ANN的性能 (Cao et al., 2015; Diehl et al., 2015; Deng & Gu, 2021)。
然而,我们的方法在两步过程中同时考虑了定制ANN的性能和转换误差。
- 首先,我们为源ANN设计一个新的激活函数,以创建定制的ANN。
- 然后,我们训练定制的ANN并将其转换为SNN。
通过考虑定制ANN和常规ANN之间的性能损失,我们的框架确保新的激活函数不会偏离常规ReLU太远。
3.1. 统一框架下的ANN-SNN转换
我们定义了一个ANN到SNN转换的统一优化框架。
定义1 (ANN-SNN转换的统一优化框架):
该框架被表述为一个具有隐含变量 T 的优化问题:
min F , T { w E z ( ∣ F ReLU ( z ; W ) − F ANN ( z ; W ) ∣ ) + ( 1 − w ) E z ( ∣ F ANN ( z ; W ) − F SNN ( z ; W , T ) ∣ ) } (5) \min_{F,T} \left\{ wE_z\left( \left| F_{\text{ReLU}}(z; W) - F_{\text{ANN}}(z; W) \right| \right) + (1 - w)E_z\left( \left| F_{\text{ANN}}(z; W) - F_{\text{SNN}}(z; W, T) \right| \right) \right\} \tag{5} F,Tmin{ wEz(∣FReLU(z;W)−FANN(z;W)∣)+(1−w)Ez(∣FANN(z;W)−FSNN(z;W,T)∣)}(5)
- 性能损失(Performance Loss):
w E z ( ∣ F ReLU ( z ; W ) − F ANN ( z ; W ) ∣ ) wE_z\left( \left| F_{\text{ReLU}}(z; W) - F_{\text{ANN}}(z; W) \right| \right) wEz(∣FReLU(z;W)−FANN(z;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









