







利用智谱清言 Batch API 批量提取专利文本中的人名与组织名
在处理大规模中文专利文本时,实体识别(Named Entity Recognition, NER),特别是对自然人姓名和组织名称的准确提取,是一项关键任务。然而,传统的规则匹配方法(如基于正则表达式或关键词)在中文环境中表现非常有限:
- 中文姓名长度不一,可能包含中间空格或叠字;
- 组织名称结构复杂,常含有多层次机构名、行业术语甚至外文缩写;
- 数据来源多样,格式不规范,人工校对成本高昂。
因此,这类任务非常适合交由 大语言模型(LLM) 来完成,尤其是具备强大语言理解与信息抽取能力的新一代中文大模型。
📌 背景与任务目标
我们的目标是从专利文本的以下字段中,批量提取出自然人姓名与组织机构名称,并将其结构化为标准格式:
- 发明人
- 申请人
- 代理人
- 专利权人
- 审查员
面对庞大的文本数据规模,传统逐条处理方法效率低、成本高。为此,我们采用了智谱清言(Zhipu AI)平台提供的 Batch API 批处理功能,将请求打包为 .jsonl 文件,一次性提交成批任务,大幅提高处理效率。
为什么选择智谱 GLM-4-Flash?
智谱 AI 提供的 GLM-4-Flash 是目前国内首个 免费开放调用 的高性能大语言模型 API.
第一步:构造 Batch API 所需的 .jsonl 文件
按照 智谱清言 Batch 接口文档 的要求,Batch API 采用 .jsonl 文件作为批量输入格式:每一行是一个标准 JSON 对象,代表一条请求。因此我们首先需要完成两件事:
- 设计清晰的系统提示词(system prompt),指引模型识别并格式化输出;
- 将原始数据转化为成批结构化请求,写入
.jsonl文件,供模型处理。
🔧 1.1 系统提示词设计
提示词是大语言模型行为的“说明书”。为了指导 GLM-4-Flash 精准识别中文专利文本中的人名和组织名,我们设计如下系统提示词:
system_prompt = """你是一个中文实体识别助手,请从如下文本中提取所有自然人姓名和组织名称,**并生成三元组格式的输出**:每个实体单独一行,格式为:
【申请号】,【字段名称】,【人名或组织名称】
【提取要求】:
1. 自然人姓名是2~4个连续的中文字符,不能只包含单个汉字,必须是具体自然人。
2. 组织名称包含“公司”“大学”“研究所”“医院”“集团”“事务所”“实验室”等关键词,或是常见的单位名称。
3. 只输出识别出的有效实体对应的三元组(申请号,字段,实体),不得额外输出“无提取项”“未提及”等文字。
4. 每个结果占一行,顺序按原始文本中实体出现顺序排列。
5. 如该条数据中没有符合要求的姓名或组织名称,则不输出任何结果(即跳过该条,不留空行也不输出提示)。
6. 不要输出带有解释说明的语句、标点、多余修饰词等,只保留三元组内容。
【示例1】:
原始文本:
CN108190907B,发明人,黄小东 卓润生 王旺阳
输出结果:
CN108190907B,发明人,黄小东
CN108190907B,发明人,卓润生
CN108190907B,发明人,王旺阳
【示例2】:
原始文本:
CN117545438A,申请人,米松尼克斯有限责任公司
输出结果:
CN117545438A,申请人,米松尼克斯有限责任公司
【示例3】:
原始文本:
CN108251925A,发明人,唐新军马晓琳李少敏宋均燕何小东刘霞;
输出结果:
CN108251925A,发明人,唐新军
CN108251925A,发明人,马晓琳
CN108251925A,发明人,李少敏
CN108251925A,发明人,宋均燕
CN108251925A,发明人,何小东
CN108251925A,发明人,刘霞
请处理以下这条数据:
"""
🧠 提示词设计建议:
- ✅ 明确输入输出格式:尤其在结构化任务中,指定格式有助于模型稳定输出;
- ✅ 强调字段语义:包括“申请号”、“字段名称”等信息,便于回溯;
- ✅ 控制实体范围:
- 自然人姓名:限定为2~4个连续汉字;
- 组织名称:通过关键词(如“公司”、“研究院”、“大学”、“有限责任公司”等)辅助识别;
- ❌ 禁止输出无关内容或格式不一致的实体(如日期、地址、位置等);
提示词质量越高,模型输出越稳定,是整个流程成功与否的关键之一。
📦 1.2 批量构造 .jsonl 请求文件(每批最多 5000 条)
假设我们已有清洗后的专利数据表(如 filtered_data.csv),我们接下来将每条数据逐行转换为 JSON 格式请求:
import pandas as pd
import json
df = pd.read_csv("../filtered_data.csv")
output = []
for idx, row in df.iterrows():
app_id = row["申请号"]
field = row["字段名称"]
content = row["文本内容"]
user_prompt = f"{app_id},{field},{content}"
request_data = {
"custom_id": f"request-{idx}", # 每条请求唯一标识
"method": "POST",
"url": "/v4/chat/completions",
"body": {
"model": "glm-4-flash",
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
"temperature": 0.95,
"top_p": 0.7,
"max_tokens": 1024
}
}
output.append(json.dumps(request_data, ensure_ascii=False))
# 每 5000 条一批,保存为 jsonl 文件
with open("batch_0.jsonl", "w", encoding="utf-8") as f:
f.write("\n".join(output))
✅ 注意事项总结:
- 每条请求必须使用唯一的
custom_id,便于任务追踪;.jsonl文件建议每批不超过 5000 条,防止上传失败;ensure_ascii=False关键参数,防止中文被转义为 Unicode,确保文本可读性;- 保留字段如
app_id和字段名称是为了在模型输出中便于还原实体的来源。
第二步:提交 Batch 任务
当我们准备好了包含批量请求的 .jsonl 文件后,下一步就是将其上传到智谱平台,并发起一个批处理任务。
我们将使用官方提供的 zhipuai Python SDK 来完成这一步。
📦 安装依赖(如未安装):
pip install zhipuai
☁️ 2.1 上传 .jsonl 文件
首先,将生成好的 .jsonl 文件上传至智谱平台。上传时需指定 purpose="batch",告知服务器这是用于批处理任务的输入文件。
from zhipuai import ZhipuAI
# 初始化客户端(请替换为你的实际 API Key)
client = ZhipuAI(api_key="你的APIKey")
# 选择你刚刚生成的 jsonl 文件路径
file_path = "batch_0.jsonl"
# 上传文件到智谱云
upload_result = client.files.create(
file=open(file_path, "rb"),
purpose="batch"
)
# 获取上传后返回的文件 ID
file_id = upload_result.id
print("✅ 上传成功,文件 ID 为:", file_id)
💡 说明:
file_id是上传成功后系统分配的唯一标识,后续提交任务必须使用它;- 建议在多批次上传时使用日志记录每个文件对应的
file_id,便于追踪和管理。
🚀 2.2 创建 Batch 任务
上传文件成功后,我们将该文件提交为一个正式的批量处理任务。每个任务支持最大 24 小时的处理窗口:
batch_resp = client.batches.create(
input_file_id=file_id, # 绑定上传的文件
endpoint="/v4/chat/completions", # 指定调用的 API 接口
completion_window="24h", # 最长处理时间,最多可设为 24 小时
auto_delete_input_file=True, # 可选:任务完成后自动删除上传的文件
metadata={"description": f"Batch task from {file_path}"} # 附加说明
)
batch_id = batch_resp.id
print("📨 Batch 任务提交成功,任务 ID 为:", batch_id)
📘 参数说明:
input_file_id:必填,来自上一步文件上传;endpoint:使用的 API 路径,这里是/v4/chat/completions;completion_window:表示最长的处理窗口时间,通常为"24h";metadata:自定义备注信息,便于后续查找;auto_delete_input_file:设置为True可节省文件存储空间。
2.3 批量上传多个 .jsonl 文件(可选)
在某些情况下,你可能需要上传多个 .jsonl 文件,这时可以通过一个批量上传的脚本来简化操作。该步骤将会遍历指定目录中的所有 .jsonl 文件,将它们一个一个地上传到智谱平台,并记录每个文件的 file_id,以便后续创建对应的 Batch 任务。
🧰 环境准备
pip install zhipuai
📁 文件目录要求
你应该将所有待上传的 .jsonl 文件放在一个文件夹内,例如:
project_root/
├── origin/
│ ├── batch_0.jsonl
│ ├── batch_1.jsonl
│ ├── batch_2.jsonl
│ ├── ...
📜 批量上传 Batch 代码示例
from zhipuai import ZhipuAI
import os
import csv
# 初始化客户端(请替换为你的 API Key)
client = ZhipuAI(api_key="你的APIKey")
# 设置文件目录路径
batch_dir = "origin"
output_csv = "uploaded_files_mapping.csv"
# 找出所有的 .jsonl 文件,并按文件名排序(如果需要)
jsonl_files = sorted(
[f for f in os.listdir(batch_dir) if f.endswith(".jsonl")],
key=lambda x: int(''.join(filter(str.isdigit, x))) # 按文件名中的数字排序
)
# 存储每个上传文件的记录
upload_records = []
# 遍历文件并进行上传
for idx, file_name in enumerate(jsonl_files):
file_path = os.path.join(batch_dir, file_name)
# 上传文件
try:
upload_result = client.files.create(file=open(file_path, "rb"), purpose="batch")
file_id = upload_result.id
print(f"✅ 文件 {file_name} 上传成功,File ID:{file_id}")
except Exception as e:
print(f"❌ 文件上传失败:{file_name},错误:{e}")
continue
# 创建 batch 任务
create = client.batches.create(
input_file_id=file_id,
endpoint="/v4/chat/completions",
auto_delete_input_file=True,
metadata={"description": f"batch task for {file_name}"}
)
batch_id = client.batches.retrieve(create.id)
print(f"📦 Batch 任务创建成功:{file_name} -> Batch ID:{batch_id}")
# 保存上传记录(包括 file_id 和文件名)
upload_records.append({
"file_name": file_name,
"file_id": file_id,
"batch_id": batch_id
})
# 将上传的文件记录保存到 CSV 中,便于后续管理
with open(output_csv, "w", newline='', encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["file_index", "file_name", "file_id"])
writer.writeheader()
writer.writerows(upload_records)
print(f"✅ 所有文件已上传,并记录到 {output_csv}")
📄 生成的 CSV 样例:
| file_name | file_id | batch_id |
|---|---|---|
| requests_batch_0.jsonl | xxxxx | Batch(id=‘batch_xxxxx’, completion_window=‘’, c… |
| requests_batch_1.jsonl | xxxxx | Batch(id=‘batch_xxxxx’, completion_window=‘’, c… |
| requests_batch_2.jsonl | xxxxx | Batch(id=‘batch_xxxxx’, completion_window=‘’, c… |
🧠 解析与步骤解释:
- 文件遍历:首先,我们遍历指定的文件夹(
batch_dir)中的所有.jsonl文件,并确保它们按照文件名中的数字顺序排列。 - 文件上传:对每个
.jsonl文件,我们使用ZhipuAISDK 的files.create()方法进行上传。成功上传后,我们会从响应中获取file_id。 - 记录保存:每次上传后,将文件名和对应的
file_id保存到upload_records列表中,并最终将该列表写入 CSV 文件。 - 输出:CSV 文件(
uploaded_files_mapping.csv)记录了每个文件的文件名、file_id及其对应的batch_id。
✅ 小贴士:
- 文件数量较多时,建议适当增加延时(例如
time.sleep(1)),避免频繁上传造成的 API 限制。 - 如果每个
.jsonl文件很大,可以考虑对其进行切割或分批上传,以防止上传过程中出现超时或其他错误。
第三步:监控任务状态并下载结果
在提交完 Batch 任务之后,我们需要耐心等待模型处理,并实时监控任务的执行状态。一旦任务完成,就可以下载批量结构化的输出结果。
⏱️ 3.1 查询任务状态
你有两种方式可以检查任务的运行进度:
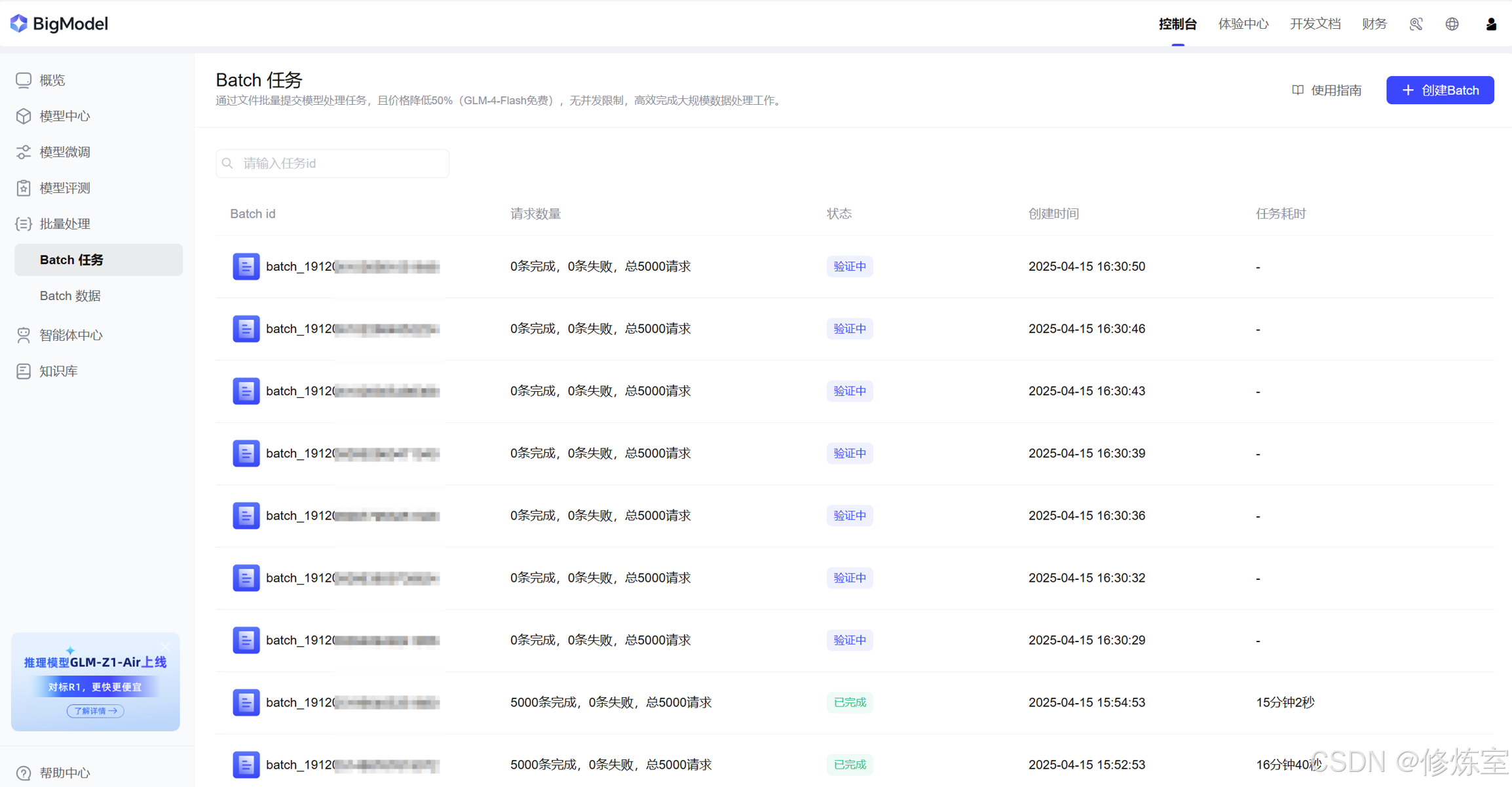
✅ 方法一:通过网页控制台可视化查看
前往智谱云的控制台页面:
可查看所有提交的任务状态、任务描述、创建时间及文件下载链接。
✅ 方法二:通过代码轮询监控状态
以下 Python 脚本可以帮助你实时监控某个任务的状态,直到其完成或失败:
import time
# 显示任务状态的中文说明(用于友好提示)
BATCH_STATUS_DESC = {
"validating": "文件正在验证中,Batch任务未开始",
"failed": "文件未通过验证 ❌",
"in_progress": "任务进行中 ⏳",
"finalizing": "任务已完成,正在生成结果文件 🔄",
"completed": "任务完成 ✅,可下载结果",
"expired": "任务失败 ❌(已过期)",
"cancelling": "任务正在取消中",
"cancelled": "任务已取消 ❌"
}
# 替换为你实际的 batch_id
batch_id = "your_batch_id_here"
while True:
batch_job = client.batches.retrieve(batch_id)
status = batch_job.status
status_desc = BATCH_STATUS_DESC.get(status, f"未知状态:{status}")
print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] 状态更新: {status_desc}")
if status in ["completed", "failed", "expired", "cancelled"]:
print("🎯 任务进入终态,退出监控")
break
time.sleep(10) # 每 10 秒轮询一次
🧠 常见状态说明:
validating:正在验证上传的文件格式in_progress:模型正在执行任务finalizing:任务完成,正在整理输出结果completed:任务结束,结果文件可下载failed/expired:任务失败或超时,需重新提交
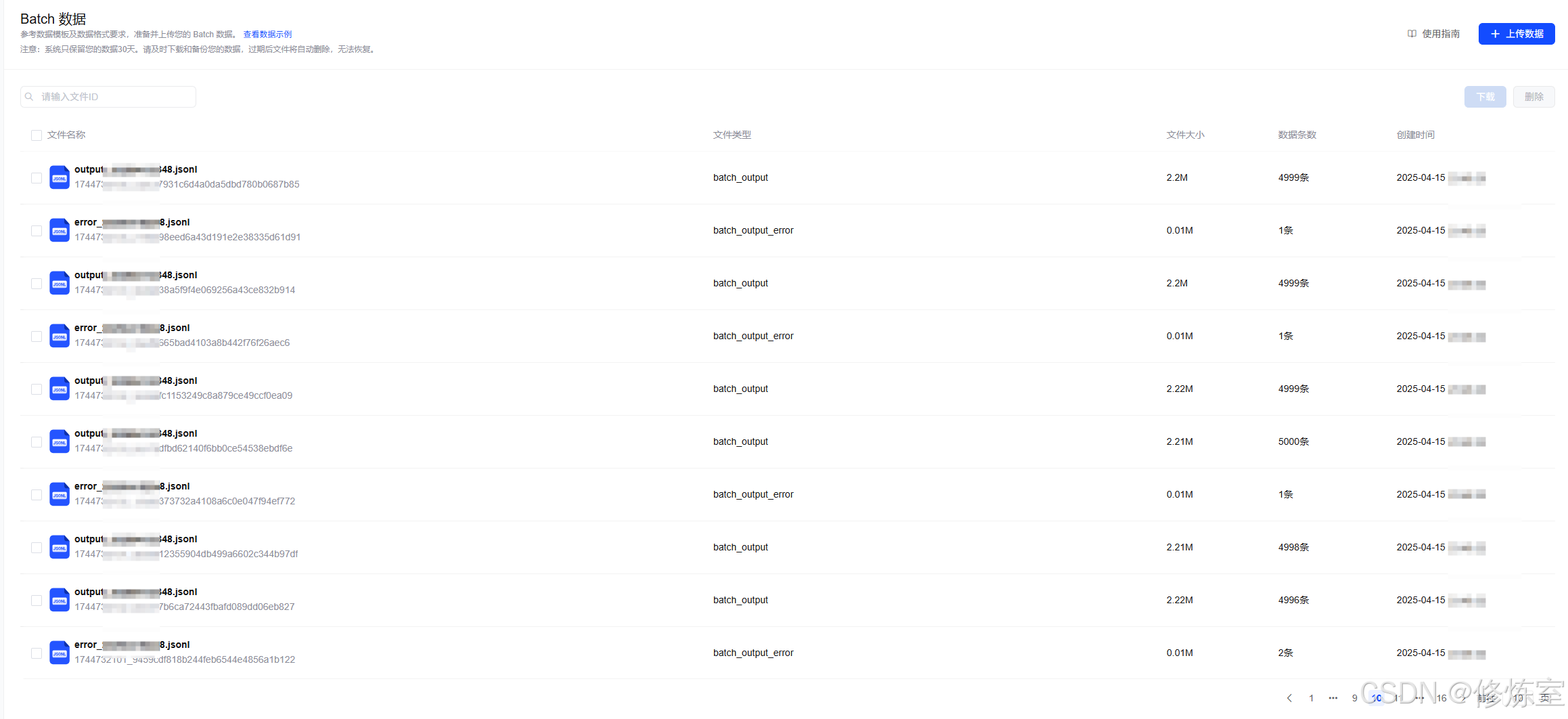
📥 3.2 下载输出结果文件
当任务状态为 completed 时,即可获取输出文件 ID,并下载对应的结构化结果。
也可通过控制台手动下载:Batch 数据集下载页面
📄 下载代码示例:
# 查询任务获取结果文件 ID
result = client.batches.retrieve(batch_id)
output_file_id = result.output_file_id # 正确请求结果
error_file_id = result.error_file_id # 异常请求结果
# 下载正确的结果文件(如果有)
if output_file_id:
content = client.files.retrieve_content(output_file_id)
with open(f"results/output_{batch_id}.jsonl", "w", encoding="utf-8") as f:
f.write(content)
print("✅ 结果文件已保存")
# 下载错误日志(可选)
if error_file_id:
error_content = client.files.retrieve_content(error_file_id)
with open(f"results/errors_{batch_id}.jsonl", "w", encoding="utf-8") as f:
f.write(error_content)
print("⚠️ 错误日志文件已保存")
⚠️ 注意事项:
- 智谱平台的结果文件仅保留 30 天,请务必及时下载备份;
- 正确的输出在
output_file_id中,出错或格式不规范的请求会保存在error_file_id中,便于后续分析修复;- 输出文件是
.jsonl格式,每行为一个结构化 JSON 结果,可用于后续数据处理与分析。
第四步:解析 .jsonl 结果文件,提取结构化三元组
模型最后得到的结果是 .jsonl 格式,每一行是一个结构化 JSON,我们需要将其中的三元组形式提取出来,并写入成 CSV 文件,方便后续处理和分析。
✅ 功能目标:
- 遍历指定文件夹中所有以
output开头的.jsonl文件; - 从每行的
response.body.choices[0].message.content中提取三元组格式; - 解析出:
申请号、字段名、实体名称; - 持久化保存为
CSV文件,供后续分析使用。
🧠 数据结构说明:
智谱 Batch 接口返回格式如下所示(JSON 每行结构):
{
"response": {
"status_code": 200,
"body": {
"created": ,
"usage": {
"completion_tokens": 16,
"prompt_tokens": 496,
"total_tokens": 512
},
"model": "glm-4-flash",
"id": "",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"role": "assistant",
"content": "CN106981841A,发明人,田海波"
}
}
],
"request_id": "request-xxx"
}
},
"custom_id": "request-xx",
"id": "xxxxxx"
}
我们要提取的就是 content 字段中的每一行,并按 , 分隔成三元组。
✅ 完整解析与写入代码:
import os
import json
import csv
# 输入结果文件夹 & 输出目标 CSV 文件
input_dir = './data' # 放置 .jsonl 文件的位置
output_file = '原始-output.csv' # 输出的结构化三元组 CSV 文件
# 如果输出文件不存在,先写入表头
file_exists = os.path.isfile(output_file)
if not file_exists:
with open(output_file, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['申请号', '字段', '内容'])
# 遍历所有以 output 开头的 jsonl 文件
for filename in os.listdir(input_dir):
if filename.startswith('output') and filename.endswith('.jsonl'):
filepath = os.path.join(input_dir, filename)
records = []
with open(filepath, 'r', encoding='utf-8') as f:
for line in f:
try:
data = json.loads(line.strip())
content = data.get("response", {}).get("body", {}).get("choices", [{}])[0].get("message", {}).get("content", "")
if content.strip():
# 提取每一行三元组
lines = content.strip().splitlines()
for line in lines:
parts = line.strip().split(',')
if len(parts) == 3:
records.append(parts)
except Exception as e:
print(f"⚠️ 解析失败:文件 {filename} 某行异常,错误:{e}")
# 将提取出的记录写入 CSV
if records:
with open(output_file, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerows(records)
print(f"✅ 从文件 {filename} 中提取了 {len(records)} 条记录,已追加保存。")
else:
print(f"⚠️ 文件 {filename} 没有提取到有效记录。")
print("🎉 所有处理完成!")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









