







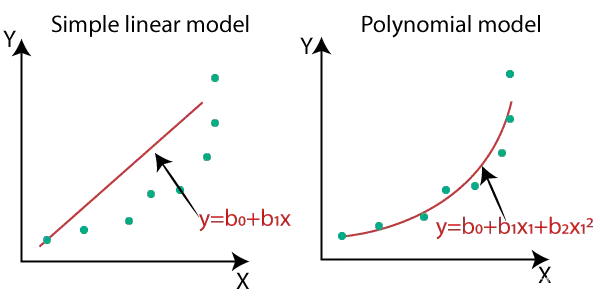
在线性回归中,我们是寻找一条直线来尽可能的拟合数据。但是我们在大部分情况下并不满足简单的线性回归的。如下图所示的这种特殊的线性回归的情况,这种特殊的回归方法被称为多项式回归(Polynomial regression)。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
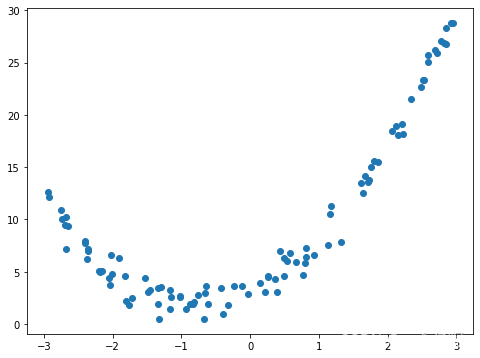
随机生成一批数据
plt.rcParams["figure.figsize"] = (8,6)
x = np.random.uniform(-3, 3, size = 100)#-3到3均匀分布的100个数据
y = 2 * x ** 2 + 3 * x + 3 + np.random.normal(0, 1, size = 100) # 加上一点噪声
plt.scatter(x, y)#散点图
plt.show()
对这些数据使用线性拟合:
X = x.reshape(-1,1)
lin_reg = LinearRegression()
lin_reg.fit(X, y)
y_pred = lin_reg.predict(X)
plt.scatter(x, y)
plt.scatter(x, y_pred, color = 'r')
plt.show()
#线性回归去拟合明显不好。为了解决这个问题,可以增加一个X的平方的特征:
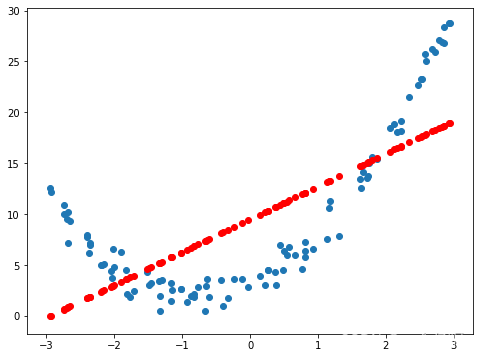
直线拟合效果并不理想,不如用曲线。
如:
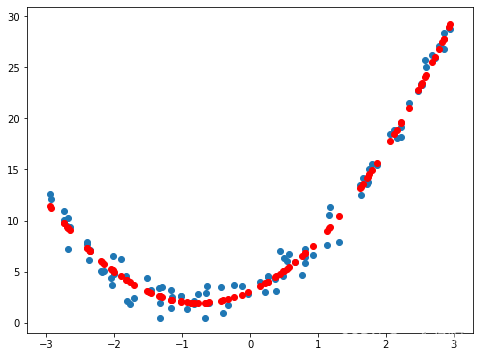
X2 = np.hstack([X, X**2])#把X,与X**2组合在一起,新的X2有了两列数据,X,X**2,作为两类特征。
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_pred2 = lin_reg2.predict(X2)
plt.scatter(x, y)
plt.scatter(x, y_pred2, color = 'r')
plt.show()
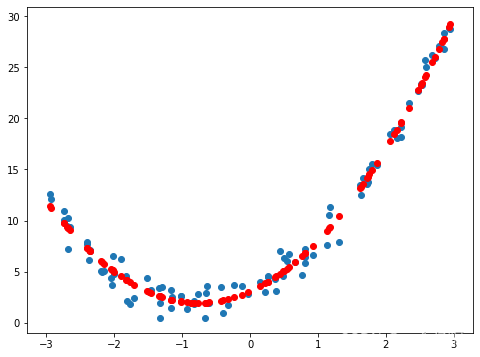
#其实在sklearn中有封装好的方法(sklearn.preprocessing.PolynomialFeatures),我们不必自己去生成这个特征了
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2) # 添加几次方特征
poly.fit(X)
X2 = poly.transform(X)#造出了新的特征数据,X2含有常数项、X、X**2
# 训练
lin_reg = LinearRegression()
lin_reg.fit(X2, y)
y_pred = lin_reg.predict(X2)
plt.scatter(x, y)
plt.scatter(x, y_pred, color = 'r')
plt.show()

















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









