







SSD
摘要
基于“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的结果,但是在速度方面离实时效果还比较远在提高 mAP 的同时兼顾速度,逐渐成为 Object Detection 未来的趋势。 YOLO 虽然能够达到实时的效果,但是其 mAP 与刚面提到的 state of art 的结果有很大的差距,即速度快,精度差。
YOLO 有一些缺陷:每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。针对 YOLO 中的这些不足,该论文提出的方法 SSD 在这两方面都有所改进,同时兼顾了 mAP 和实时性的要求。在满足实时性的条件下,接近 state of art 的结果。对于输入图像大小为 300*300 在 VOC2007 test 上能够达到 58 帧每秒( Titan X 的 GPU ),72.1% 的 mAP。
输入图像大小为 500 *500 , mAP 能够达到 75.1%。作者的思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。
与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度。
文章的核心之一是同时采用lower和upper的feature map做检测。
概念
feature map cell
就是将 feature map 切分成 8×8 或者 4×4 之后其中的一个格子;
default box feature map中每一层的default box的数量是给定的
而 default box 就是每一个格子上,一系列固定大小的 box,即图中虚线所形成的一系列 boxes。
假设每个feature map cell有k个default box,那么对于每个default box都需要预测c个类别score和4个offset,那么如果一个feature map的大小是m×n,也就是有m*n个feature map cell,那么这个feature map就一共有(c+4)k m*n 个输出。
这些输出个数的含义是:采用3×3的卷积核对该层的feature map卷积时卷积核的个数,包含两部分(实际code是分别用不同数量的3*3卷积核对该层feature map进行卷积):数量c*k*m*n是confidence输出,表示每个default box的confidence,也就是类别的概率;数量4*k*m*n是localization输出,表示每个default box回归后的坐标)。
训练中还有一个东西:prior box(坐标),是指实际中选择的default box(每一个feature map cell 不是k个default box都取)。也就是说default box是一种概念,prior box则是实际的选取。
训练中一张完整的图片送进网络获得各个feature map,对于正样本训练来说,需要先将prior box与ground truth box做匹配,匹配成功说明这个prior box所包含的是个目标,但离完整目标的ground truth box还有段距离,训练的目的是保证default box的分类confidence的同时,将prior box尽可能回归到ground truth box。
举个栗子:假设一个训练样本中有2个ground truth box,所有的feature map中获取的prior box一共有8732个。那个可能分别有10、20个prior box能分别与这2个ground truth box匹配上。训练的损失包含定位损失和回归损失两部分。
匹配策略
监督学习的训练关键是人工标注的label。对于包含default box(在Faster R-CNN中叫做anchor)的网络模型(如: YOLO,Faster R-CNN, MultiBox)关键点就是如何把 标注信息(ground true box,ground true category)映射到(default box上)
正负样本: 给定输入图像以及每个物体的 ground truth,首先找到每个ground true box对应的default box中IOU最大的作为(与该ground true box相关的匹配)正样本。然后,在剩下的default box中找到那些与任意一个ground truth box 的 IOU 大于 0.5的default box作为(与该ground true box相关的匹配)正样本。 一个 ground truth 可能对应多个 正样本default box 而不是只取一个IOU最大的default box。其他的作为负样本(每个default box要么是正样本box要么是负样本box)。
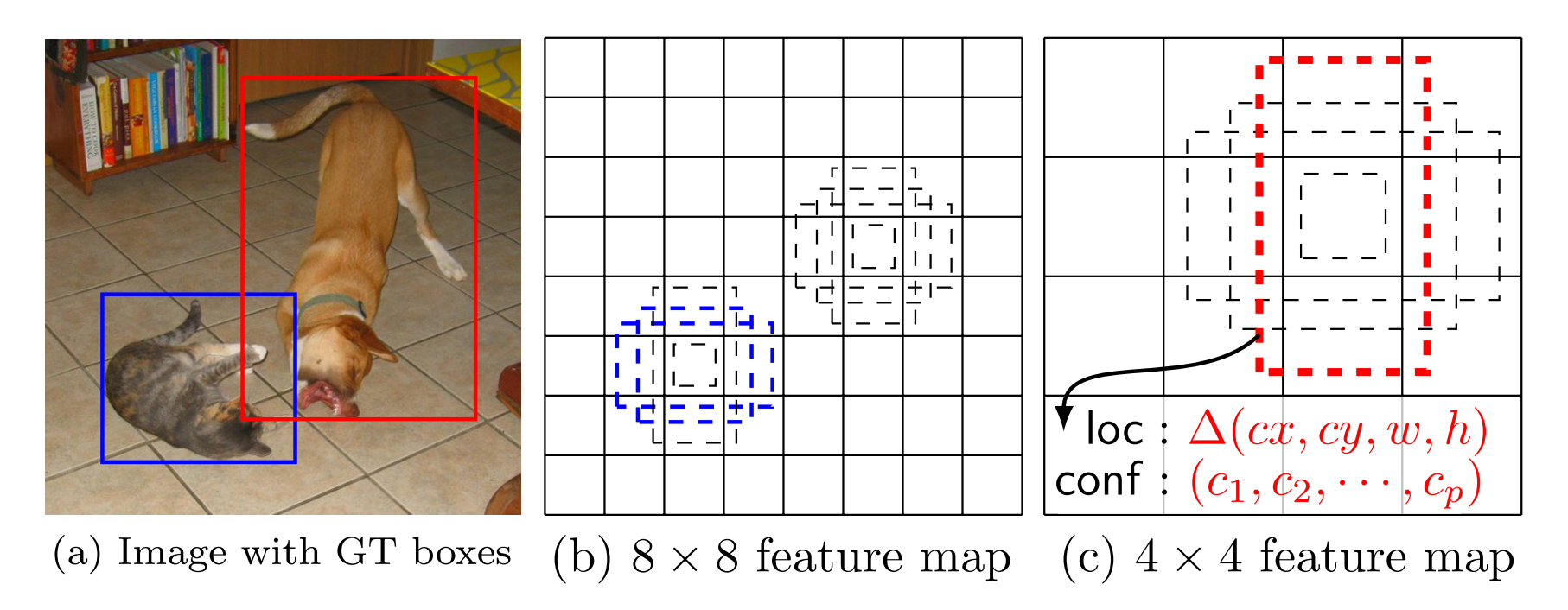
下图的例子是:给定输入图像及 ground truth,分别在两种不同尺度(feature map 的大小为 8*8,4*4)下的匹配情况。有两个 default box 与猫匹配(8*8),一个 default box 与狗匹配(4*4)。


选择default box的比例和横宽比
大多数卷积网络通过加深层数减小特征图的大小。这不仅减少计算和存储消耗,而且还提供一定程度的平移和尺寸不变性。为了处理不同的对象尺寸,一些方法建议将图像转换为不同的尺寸,然后单独处理每个尺寸,然后组合结果。然而,通过用单个网络中的若干不同层的特征图来进行预测,我们可以得到相同的效果,同时还在所有对象尺度上共享参数。之前的研究已经表明使用来自较低层的特征图可以提高语义分割质量,因为较低层捕获到输入对象的更精细的细节。类似地,添加从高层特征图下采样的全局文本可以帮助平滑分割结果。受这些方法的启发,我们使用低层和高层的特征图进行检测预测。 下图示出了在框架中使用的两个示例特征图(8×8和4×4),当然在实践中,我们可以使用更多具有相对小的计算开销的特征图。
通过组合许多特征图在所有位置的不同尺寸和宽高比的所有默认框的预测,我们具有多样化的预测集合,覆盖各种输入对象尺寸和形状。例如下图中,狗被匹配到4×4特征图中的默认框,但不匹配到8×8特征图中的任何默认框。这是因为那些框具有不同的尺度但不匹配狗的框,因此在训练期间被认为是负样本。
已知网络中不同层的特征图具有不同的(经验)感受野大小。所幸的是,SSD 结构中,default boxes 不必要与每一层 layer 的 感知野 对应。本文的设计中,feature map 中特定的位置,来负责图像中特定的区域,以及物体特定的尺寸。加入我们用 m 个 feature maps 来做 predictions,每一个 feature map 中 default box 的尺寸大小计算如下:
其中smin是0.2,smax是0.95,意味着最低层具有0.2的刻度,最高层具有0.95的刻度,并且其间的所有层是规则间隔的。再用不同 aspect ratio 的 default boxes,用 ar 来表示:ar={1,2,3,12,13}ar={1,2,3,12,13},则每一个 default boxes 的 width、height 就可以计算出来:
对于 aspect ratio 为 1 时,本文还增加了一个 default box,这个 box 的 scale 是 。所以最终,在每个 feature map location 上,最多有 6 个 default boxes。
每一个 default box 的中心,设置为:
|fk| 是第 k 个 feature map 的大小
可以看出这种default box在不同的feature层有不同的scale,在同一个feature层又有不同的aspect ratio,因此基本上可以覆盖输入图像中的各种形状和大小的object!
具体到每一个feature map上获得prior box时,会从这6种中进行选择。如下表和图所示最后会得到(38*38*4 + 19*19*6 + 10*10*6 + 5*5*6 + 3*3*4 + 1*1*4)= 8732个prior box。
Hard negative mining
在生成一系列的 predictions 之后,会产生很多个符合 ground truth box 的 predictions boxes,但同时,不符合 ground truth boxes 也很多,而且这个 negative boxes,远多于 positive boxes。这会造成 negative boxes、positive boxes 之间的不均衡。训练时难以收敛。
因此,本文采取,先将每一个物体位置上对应 predictions(default boxes)是 negative 的 boxes 进行排序,按照 default boxes 的 confidence 的大小。 选择最高的几个,保证最后 negatives、positives 的比例在 3:1。
本文通过实验发现,这样的比例可以更快的优化,训练也更稳定。
Data augmentation
为了模型更加鲁棒,需要使用不同尺寸的输入和形状,作者对数据进行了如下方式的随机采样:
- 使用整张图片
- 使用IOU和目标物体为0.1, 0.3,0.5, 0.7, 0.9的patch (这些 patch 在原图的大小的 [0.1,1] 之间, 相应的宽高比在[1/2,2]之间)
- 随机采取一个patch
当 ground truth box 的 中心(center)在采样的 patch 中时,我们保留重叠部分。在这些采样步骤之后,每一个采样的 patch 被 resize 到固定的大小,并且以 0.5 的概率随机的 水平翻转(horizontally flipped)。用数据增益通过实验证明,能够将数据mAP增加8.8%。
网络结构
 )
)
该论文采用 VGG16 的基础网络结构,使用前面的前 5 层,然后利用 astrous 算法将 fc6 和 fc7 层转化成两个卷积层。再格外增加了 3 个卷积层,和一个 average pool层。不同层次的 feature map 分别用于 default box 的偏移以及不同类别得分的预测。这些增加的卷积层的 feature map 的大小变化比较大,允许能够检测出不同尺度下的物体: 在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。最后通过 NMS 得到最终的检测结果。
惯用思路:使用通用的结构(如前 5个conv 等)作为基础网络,然后在这个基础上增加其他的层
观察YOLO,后面存在两个全连接层,全连接层以后,每一个输出都会观察到整幅图像,并不是很合理。但是SSD去掉了全连接层,每一个输出只会感受到目标周围的信息,包括上下文。这样来做就增加了合理性。并且不同的feature map,预测不同宽高比的图像,这样比YOLO增加了预测更多的比例的box。(下图横向的流程)

以5x5x256为例 它的#defalut_boxes = 6


按照不同的 scale 和 ratio 生成,k 个 default boxes,这种结构有点类似于 Faster R-CNN 中的 Anchor。(此处k=6所以:5*5*6 = 150 boxes)



增加的每个卷积层的 feature map 都会通过一些小的卷积核操作,得到每一个 default boxes 关于物体类别的21个置信度
20个类别和1个背景) 和4偏移 (shape offsets) 。

损失函数


训练过程中的 prior boxes 和 ground truth boxes 的匹配,基本思路是:让每一个 prior box 回归并且到 ground truth box,这个过程的调控我们需要损失层的帮助,他会计算真实值和预测值之间的误差,从而指导学习的走向。
SSD 训练的目标函数(training objective)源自于 MultiBox 的目标函数,但是本文将其拓展,使其可以处理多个目标类别。
具体过程是我们会让每一个 prior box 经过Jaccard系数计算和真实框的相似度,阈值只有大于 0.5 的才可以列为候选名单;假设选择出来的是N个匹配度高于百分之五十的框吧,我们令 i 表示第 i 个默认框,j 表示第 j 个真实框,p表示第p个类。那么xpij表示 第 i 个 prior box 与 类别 p 的 第 j 个 ground truth box 相匹配的Jaccard系数,若不匹配的话,则xpij=0。总的目标损失函数(objective loss function)就由 localization loss(loc) 与 confidence loss(conf) 的加权求和:

N 是与 ground truth box 相匹配的 prior boxes 个数
localization loss(loc) 是 Fast R-CNN 中 Smooth L1 Loss,用在 predict box(l) 与 ground truth box(g) 参数(即中心坐标位置,width、height)中,回归 bounding boxes 的中心位置,以及 width、heightconfidence loss(conf) 是 Softmax Loss,输入为每一类的置信度 c
权重项 α,可在protxt中设置 loc_weight,默认设置为 1
预测
在预测阶段,直接预测每个 default box 的偏移以及对于每个类别相应的得分。最后通过 nms 的方式得到最后检测结果。
使用注意
1.使用batch_sampler做data argument时要注意是否crop的样本只包含目标很小一部分。
2.检查对于你的样本来说回归和分类问题哪个更难,以此调整multibox_loss_param中loc_weight进行训练。
3.正负样本比例,HARD_EXAMPLE方式默认只取64个最高predictions loss来从中寻找负样本,检查你的样本集中正负样本比例是否合适。















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









