







文章目录
1 YOLO(you only look once)算法
1.1 YOLO整体结构
一个网络搞定一切,GoogleNet + 4个卷积+2个全连接层

- YOLO流程理解
- 原始图片resize到
448x448,经过前面卷积网络之后,将图片输出成了一个7*7*30的结构 - 默认
7*7个单元格,每个单元格预测两个bbox框 - 进行NMS筛选,筛选概率以及IoU
1.2 网格(grid)——7x7x30
1.2.1 单元格(grid cell)
最后网络输出的7*7*30的特征图怎么理解?7 * 7=49个像素值,理解成49个单元格,每个单元格可以代表原图的一个方块。单元格需要做的两件事:
- 每个单元格负责预测一个物体类别,并且直接预测物体的概率值
- 每个单元格预测两个(默认)bbox位置,两个bbox置信度(confidence)
7*7*2=98个bbox
30=(4+1+4+1+20), 4个坐标信息,1个置信度(confidence)代表一个bbox的结果, 20代表 20类的预测概率结果
1.2.2 网格输出筛选
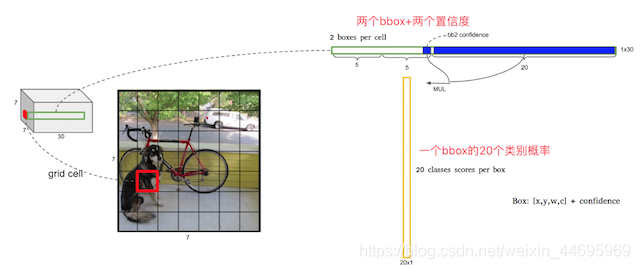
一个单元格会预测两个bbox,在训练时我们只有一个Bbox专门负责(一个Object 一个Bbox),怎么进行筛选?
- 首先,如何判断单元格中是否包含object呢?
如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。 - 如何筛选单元格中的两个bbox:通过置信度大小比较(每个bbox都对应一个置信度)
- 如果grid cell里面没有object,confidence就是
confidence=0*0 - 如果有,则confidence score等于 预测的两个bbox和ground truth的IOU乘积(confidence=
IoU1*IoU2)
- 每个单元格输出:一个置信度高的bbox,一个概率大的类别
- 网格输出筛选
每个单元格预测出一个自己的类别(概率最大的那个类别),整个网格输出如图所示:
(这个类别概率不属于单元格两个bbox中任何一个,而是属于这个单元格所预测的类别。)
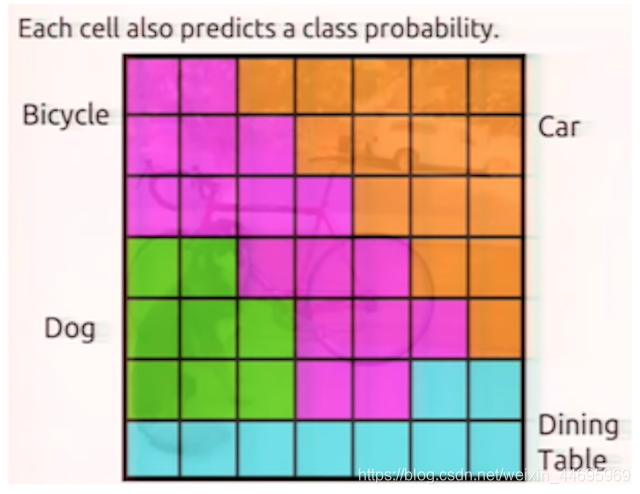
不同于Faster R-CNN中的anchors,YOLO的bbox是由网络得出,而Faster R-CNN是人为设定一个值,然后利用RPN(区域预测网络)对其优化到一个更准的bbox和类别
1.3 非最大抑制(NMS)
每个Bbox的Class-Specific Confidence Score以后,设置阈值,滤掉概率低的bbox,对每个类别过滤IoU,就得到最终的检测结果
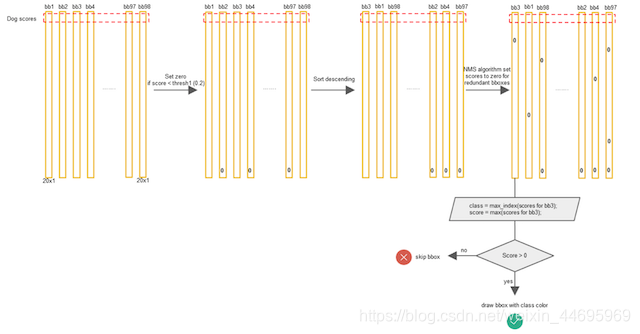
1.4 YOLO训练
怎么理解这个过程?同样以分类那种形式来对应,假设以一个单元格的预测值为结果,如下图
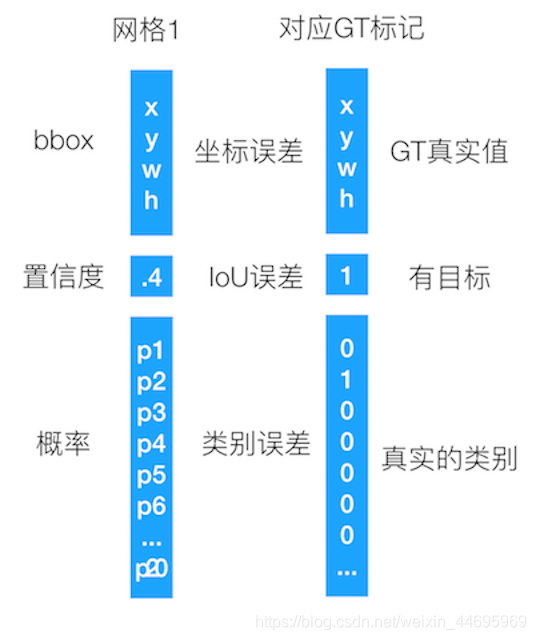
- 损失
三部分损失:bbox损失+confidence损失+classfication损失
1.5 与Faster R-CNN比较
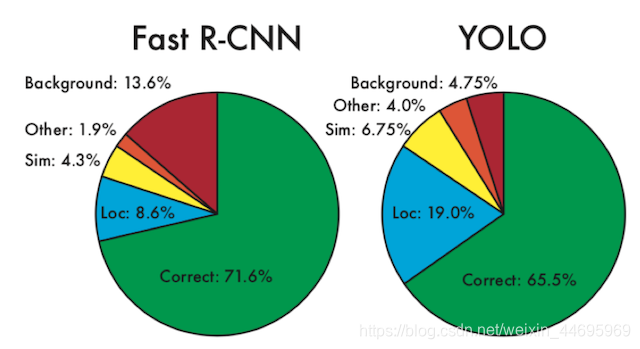
- Faster R-CNN利用RPN网络与真实值调整了候选区域,然后再进行候选区域和卷积特征结果映射的特征向量的处理来通过与真实值优化网络预测结果。
- 而这两步在YOLO当中合并成了一个步骤,直接网络输出预测结果进行优化。
所以经常也会称之为YOLO算法为直接回归法代表。 - YOLO的特点
- 优点:速度快
- 缺点:准确率会打折扣
YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体检测效果不好,这是因为一个单元格中只预测了两个框
2 SSD(Single Shot MultiBox Detector)算法
2.1 SSD简介
SSD算法源于2016年发表的算法论文,论文网址:https://arxiv.org/abs/1512.02325
SSD的特点在于:
- SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用全图各个位置的多尺度区域进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster-RCNN一样比较精准。
- SSD的核心是在不同尺度的特征特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移。
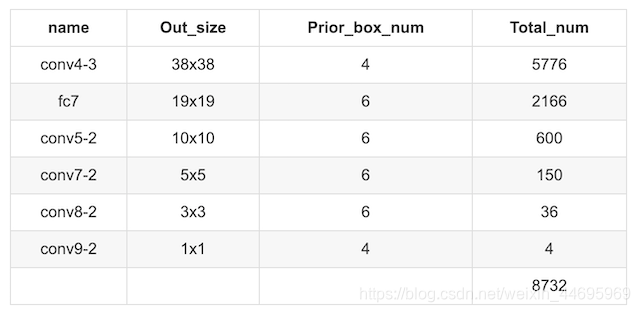
2.2 SSD结构
以VGG-16为基础,使用VGG的前五个卷积,后面增加从CONV6开始的5个卷积结构,输入图片要求300*300。

2.3 SSD流程
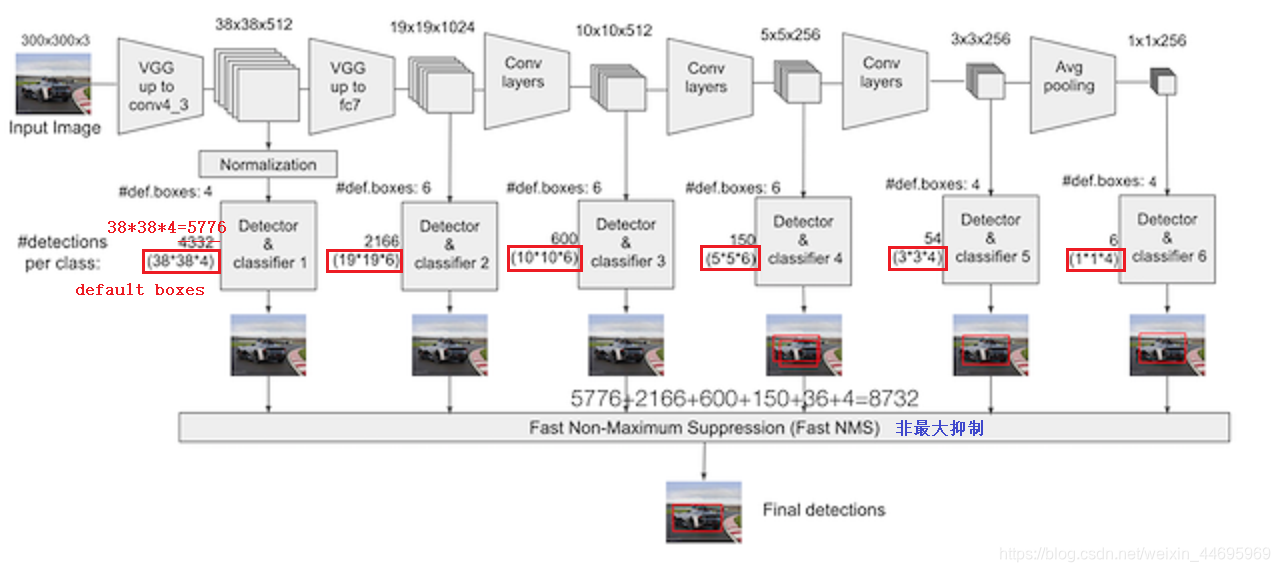
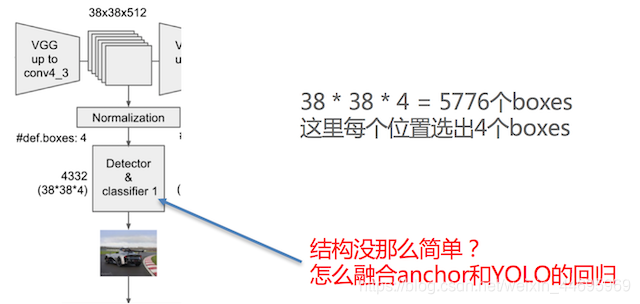
SSD中引入了Defalut Box,实际上与Faster R-CNN的anchor box机制类似,就是预设一些目标预选框,不同的是在不同尺度feature map所有特征点上使用PriorBox层(Detector & classifier)
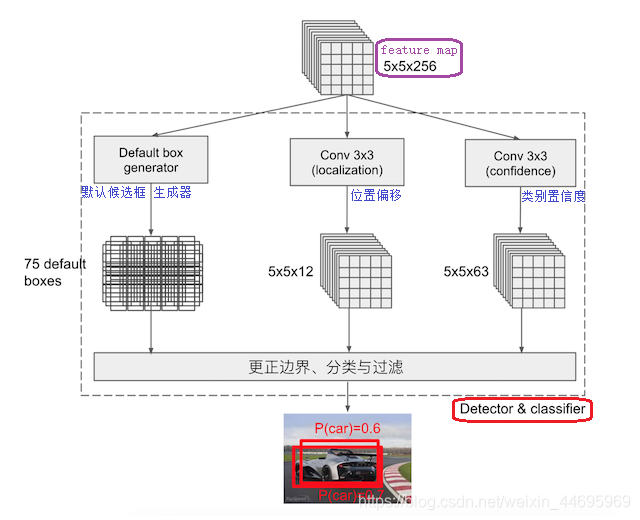
2.4 Detector & classifier
Detector & classifier的三个部分:
- PriorBox层:生成default boxes(默认候选框)
- Conv3 x 3:生成localization(4个位置偏移)
- Conv3 x 3:confidence(21个类别置信度(要区分出背景))
- 以feature map尺度为
5*5*256为例
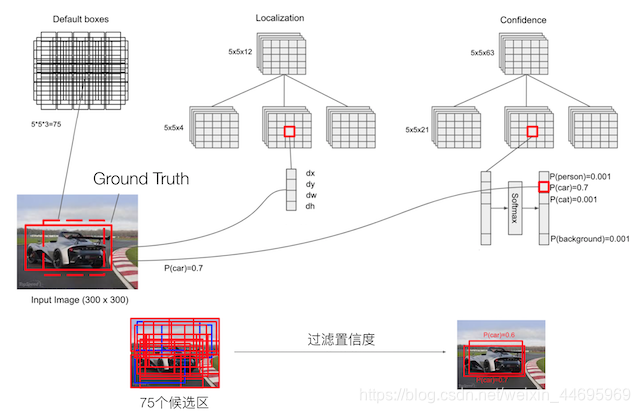
2.4.1 PriorBox层-default boxes
- default boxex类似于RPN当中的滑动窗口生成的候选框,SSD中也是对特征图中的每一个像素生成若干个框。
- 特点分析:
- priorbox:相当于faster rcnn里的anchors,预设一些bbox,网络根据bbox,通过分类和回归给出被检测到物体的类别和位置。每个window都会被分类,并回归到一个更准的位置和尺寸上
- 各个feature map层经过priorBox层生成prior box
2.5 与其他算法的比较
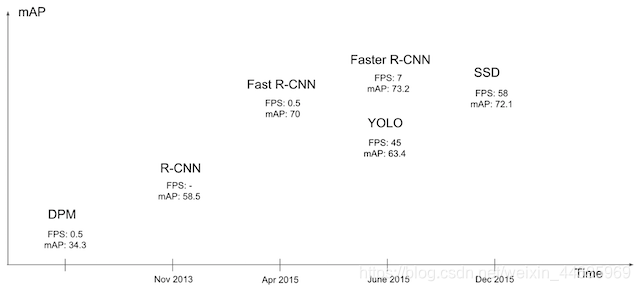
从图中看出SSD算法有较高的准确率和性能,兼顾了速度和精度

















 3471
3471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









