







 本文介绍如何使用Python根据词频字典绘制词云图,内容包括数据读取、统计、词云图的生成,参考了相关博客资源,适用于数据量较大的情况,代码简洁,结果直观。
本文介绍如何使用Python根据词频字典绘制词云图,内容包括数据读取、统计、词云图的生成,参考了相关博客资源,适用于数据量较大的情况,代码简洁,结果直观。
由于工作需要,要根据现有的新闻数据统计词频,绘制词云图,比较擅长python,因此没有用可以生成云图的网页工具。由于我的数据量比较大,因此根据字符串自动进行统计并绘制云图的方式并不适合我。我需要手动从文件中读取数据并进行统计,然后将词频字典传入函数中进行绘制。
参考资料:
本文代码参考上述两个博客修改而成,语料为英文,因此未用到结巴分词,也不涉及字体问题。为适应mask,所以结果图比较简单,如需要调整参数的,可参考下面这篇文章,其中介绍了wordcloud的各种参数的含义。Wordcloud各参数含义
数据示例
{"date":"20130131","url":"http://gulftoday.ae/portal/5308f5d3-e752-41e0-b011-4537ffe658b2.aspx","locinfo":[["Uzbekistan","UZ","UZ","41","64"]],"content":"delivering advanced defence system agency deputy defence assaying trip increase influence soviet union political trade security initiative aim tighten cooperation attempt capability soviet security bloc collective security treaty organisation combine division surplus defence ministry quoted division rocket system sending division faced criticism lack activity inception signed treaty suspending membership bloc signed contract unit war torn military","label":["military diplomacy"]}
{"date":"20130128","url":"http://enews.fergananews.com/news.php?id=2795","locinfo":[["Fergana, Farg ona, Uzbekistan","UZ","UZ03","40.3933","71.7794"]],"content":"advocate pay rare political inmate initiative independent human advocate visited inmate convicted political motif penalty enforcement colony chairman permission obtained human advocate penalty enforcement directorate ministry internal affair hold academic degree technical science born lived chairman executive council member supreme council soviet republic appointed mayor arrested criminal conspiracy","label":["jail sentence"]}
结果
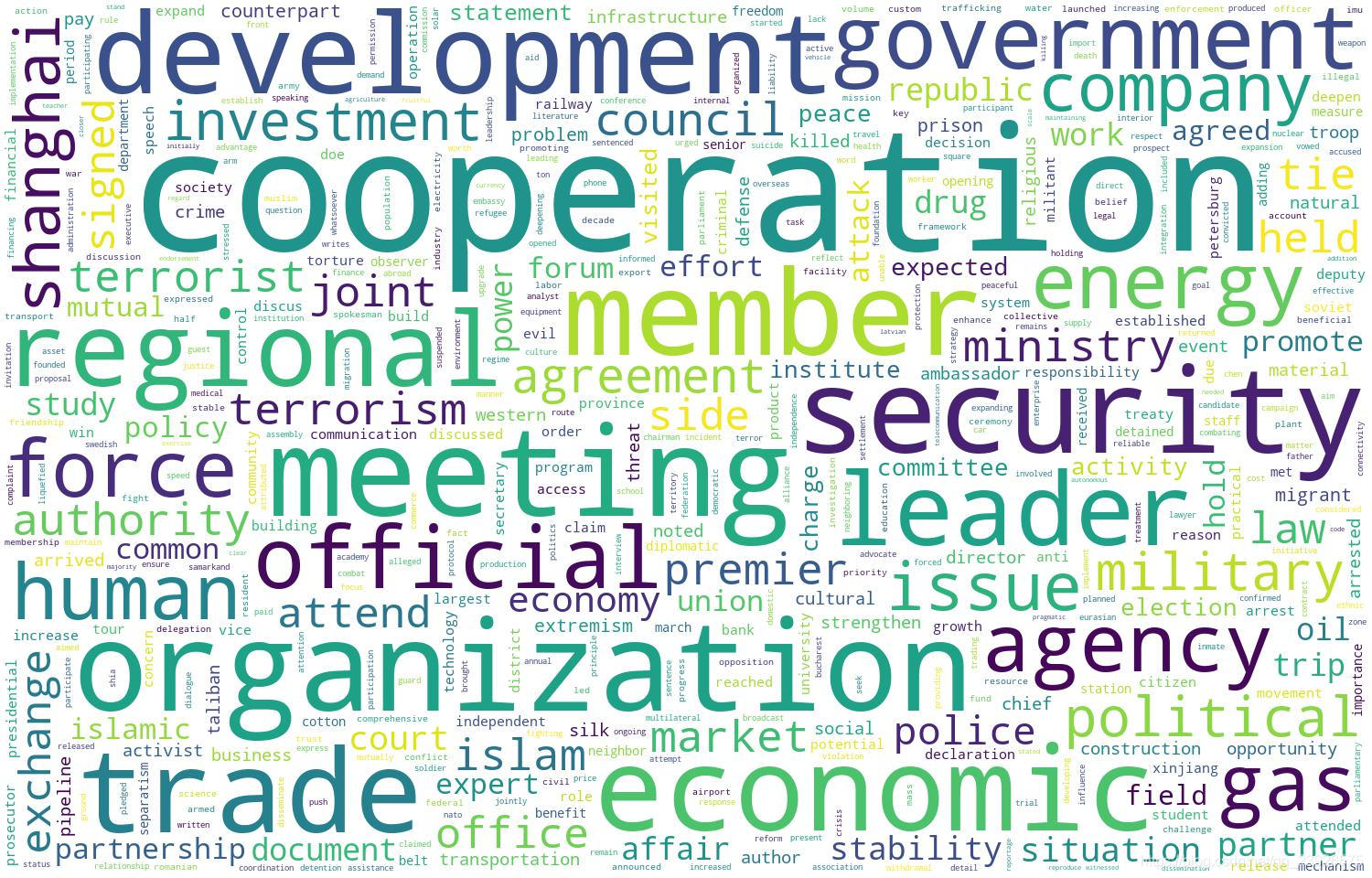
代码
#-*-coding:utf-8-*-
import sys
import os
from pprint import pprint
import codecs
import json
from collections import Counter, defaultdict
from wordcloud import WordCloud
import matplotlib.pyplot as plt
path = sys.path[0] + os.sep
def wc_from_text(str, fn):
'''根据字符串进行统计,并生成词云图'''
wc = WordCloud(
background_color="white", # 设置背景为白色,默认为黑色
width = 1500, # 设置图片的宽度
height= 960, # 设置图片的高度
margin= 10 # 设置图片的边缘
).generate(s)
plt.imshow(wc) # 绘制图片
plt.axis("off") # 消除坐标轴
plt.show() # 展示图片
wc.to_file(path + fn) # 保存图片
def wc_from_word_count(word_count, fp):
'''根据词频字典生成词云图'''
wc = WordCloud(
max_words=500, # 最多显示词数
# max_font_size=100, # 字体最大值
background_color="white", # 设置背景为白色,默认为黑色
width = 1500, # 设置图片的宽度
height= 960, # 设置图片的高度
margin= 10 # 设置图片的边缘
)
wc.generate_from_frequencies(word_count) # 从字典生成词云
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
wc.to_file(fp) # 保存图片
def generate_dict_from_file(fp):
with codecs.open(fp, 'r', 'utf-8') as source_file:
for line in source_file:
dic = json.loads(line)
yield dic
def main(data_fp, pic_fp):
word_count = defaultdict(lambda: 0)
for dic in generate_dict_from_file(data_fp):
words = dic['content'].split(' ')
for word in words:
word_count[word] += 1
with codecs.open(path + 'word_count.json', 'w', 'utf-8') as f:
json.dump(word_count, f, ensure_ascii=False)
wc_from_word_count(word_count, pic_fp)
if __name__ == '__main__':
s = 'access restored ban remains blocked government order accessible aid proxy provider telecom restored access celebrating government revoked censorship order newsroom waiting appeal court lawsuit government allowed constitution reporting stringer spread dedication journalism critical reporting brought outlet respect recognition landed blacklist authoritarian regime dominate permanently blocked severe intolerance critical journalism authority deny domestic access occasional basis regional outlet sensitive issue incident hard technical glitch deliberately blocked access depending covered government corruption human abuse social discontent policy freedom protested blocked violent conflict ethnic resident authority imposed permanent ban parliament resolution lawmaker addressed conflict recommended action government resolution reason obtaining court order law shutting outlet introduce measure domain space resolution authority'
# wc_from_text(s, 'wc1.jpg')
# word_count = Counter(s.split(' '))
# wc_from_word_count(word_count, 'wc2.jpg')
data_fp = path + 'result.json'
pic_fp = path + 'word_cloud_uz.jpg'
main(data_fp, pic_fp)
以上,欢迎交流。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









