







一个例子搞清楚(先验分布/后验分布/似然估计)
preface:
- 无论是《通信原理》、《信息论》、《信道编码》还是《概率与统计理论》,或者在现在流行的《模式识别》和《Machine Learning》中总会遇到这么几个概念:先验分布/后验分布/似然估计。
- 如果大家不熟悉这几个词,相信大家熟知贝叶斯公式,该公式涉及到了以上几个概念。但是学完本科课程,也会算题,就是在实际情境中总感觉理不清这几个概念的关系,最近上课老被老师讲的先验、后验搞得晕头转向。因此,如果您和我遇到类似的囧事,这篇文章很适合您。
- 声明:本文主要内容修改整理于知乎回答1。
本文目标:
- 一个隔壁小哥的故事
- 故事中的因果和三个概念
- 贝叶斯公式的角色
- 最大似然估计和贝叶斯的关系
隔壁小哥的故事
隔壁小哥要去15公里外的一个公园,他可以选择步行走路,骑自行车或者开辆车,然后通过其中一种方式花了一段时间到达公园。
首先在这个事里边,大家不要关注隔壁小哥去干嘛,也许去送外卖吧:) 。言归正传,这件事中采用哪种交通方式是因,花了多长时间是果。俗话说瓜熟蒂落,皆是因果;因果循环,报应不爽。要理解即将提到的概念,何为因何为果先要搞清楚。
三个概念之后验(知果求因)
隔壁小哥去公园的故事才刚刚开始,假设在这里您已经牢记住这个故事的因和果。故事仍然要接着讲,顺便带出我们的概念。
假设我们已经知道小哥花了1个小时到了公园,那么你猜他是怎么去的(走路or坐车or自行车),事实上我们不能百分百确定他的交通方式,我们正常人的思路是他很大可能是骑车过去的,当然也不排除开车过去却由于堵车严重花了很长时间,当然还有可能他是个赛跑的运动员自己一路飞跑过去的。
假设已经知道小哥花了3个小时才到公园,这个时候我们猜的时候会觉得他很大可能是静静地走路过去的。但是假设已经知道小哥只花了20分钟才到公园,那么正常人会觉得他最大可能是开车奔驰而去。
这种预先已知结果(路上花的时间),然后根据结果估计(猜)原因(交通方式)的概率分布即 后验概率。
例子问题公式化:
P ( 交 通 方 式 ∣ 花 费 的 时 间 ) P( 交通方式 | 花费的时间 ) P(交通方式∣花费的时间)
修改成一般的公式:
P ( 因 ∣ 果 ) P( 因 | 果 ) P(因∣果)
公式正规化:
P ( θ ∣ x ) P( \theta | x ) P(θ∣x)
(公式中的 “ ∣ | ∣”读作 g i v e n given given,即给定的意思。如 P ( A ∣ B ) P(A|B) P(A∣B) 即A given B 的概率)
[解释]:看到这里估计大家很奇怪为什么要用 x x x 、 θ \theta θ 这样的字母表示,而不是熟悉的 x x x 、 y y y 。这样表示自然是有原因的。在这里大家只需要先暂时记住 θ \theta θ 代表因、 x x x 代表果,后面的贝叶斯我们将会具体介绍这些字母的含义。
三个概念之先验概率(由历史求因)
换个情景,我们不再考虑隔壁小哥去公园的结果了。假设隔壁小哥还没去,大早上刚起床,打算吃完早饭再去。
假设我们比较了解小哥的个人习惯,别管怎么了解的:) 。小哥是个健身爱好者就喜欢跑步运动,这个时候我们可以猜测他更可能倾向于走路过去。
当然我的隔壁小哥是个大死肥宅,懒得要命!这个时候我们猜测他更可能倾向于坐车,连骑自行车的可能性都不大。
这个情景中隔壁小哥的交通工具选择与花费时间不再相关。因为我们是在结果发生前就开始猜的,根据历史规律确定原因 (交通方式)的概率分布即 先验概率。
例子问题公式化:
P ( 交 通 方 式 ) P(交通方式) P(交通方式)
一般化:
P ( 因 ) P( 因 ) P(因)
正规化:
P ( θ ) P(\theta) P(θ)
三个概念之似然估计(由因求果)
换个情景,我们先重新考虑隔壁小哥去公园的交通方式。
假设隔壁小哥步行走路去,15公里的路到公园,一般情况下小哥大概要用2个多小时,当然很小的可能性是小哥是飞毛腿,跑步过去用了1个小时左右,极为小的可能是小哥是隐藏的高手,10分钟就轻功跑酷到了。
小哥决定开车,到公园半个小时是非常可能的,非常小的概率是小哥因为途径的路上有车祸堵了3个小时。
这种先定下来原因,根据原因来估计结果的概率分布即 似然估计。根据原因来统计各种可能结果的概率即似然函数。
似然函数问题公式化:
P ( 时 间 ∣ 交 通 方 式 ) P(时间|交通方式) P(时间∣交通方式)
一般化:
P ( 果 ∣ 因 ) P( 果|因 ) P(果∣因)
正规化:
P ( x ∣ θ ) P( x|\theta ) P(x∣θ)
贝叶斯公式
我们熟知的贝叶斯公式是这样的:
P ( A ∣ B ) = P ( B ∣ A ) ∗ P ( A ) P ( B ) P( A|B )=\frac{P(B|A) *P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)∗P(A)
但在这里我们采用如下形式:
P ( θ ∣ x ) = P ( x ∣ θ ) ∗ P ( θ ) P ( x ) P( \theta|x )=\frac{P(x|\theta) *P(\theta)}{P(x)} P(θ∣x)=P(x)P(x∣θ)∗P(θ)
后 验 概 率 = 似 然 估 计 ∗ 先 验 概 率 e v i d e n c e 后验概率 =\frac{似然估计 *先验概率}{evidence} 后验概率=evidence似然估计∗先验概率
[注]: P ( x ) P(x) P(x) 即 e v i d e n c e evidence evidence。隔壁小哥去公园很多次,忽略交通方式是什么,只统计每次到达公园的时间 x x x,于是得到了一组时间的概率分布。这种不考虑原因,只看结果的概率分布即 e v i d e n c e evidence evidence,它也称为样本发生的概率分布的证据。
e v i d e n c e evidence evidence 在故事中如下表示:
P ( 时 间 ) P(时间) P(时间) 或
P ( 果 ) P(果) P(果)
知乎回答原文参考 这儿.
深入贝叶斯推断
在这里相信大多数人已经很好地理解了先验概率,后验概率,证据以及和似然估计的概念了。接下来我们将接着讲故事,隔壁小哥到公园以后去做一个游戏,游戏内容如下:
在小哥面前有两个一模一样的宝箱,一号箱子里面有3颗水果糖和1颗巧克力糖;二号箱子里面有2颗水果糖和2颗巧克力糖。
(1) 现在小哥将随机选择一个箱子,从中摸出一颗糖。请问小哥选择一号箱子的概率有多大?
(2) 现在小哥将随机选择一个箱子,从中摸出一颗糖发现是水果糖。请问这颗水果糖来自一号箱子的概率有多大?
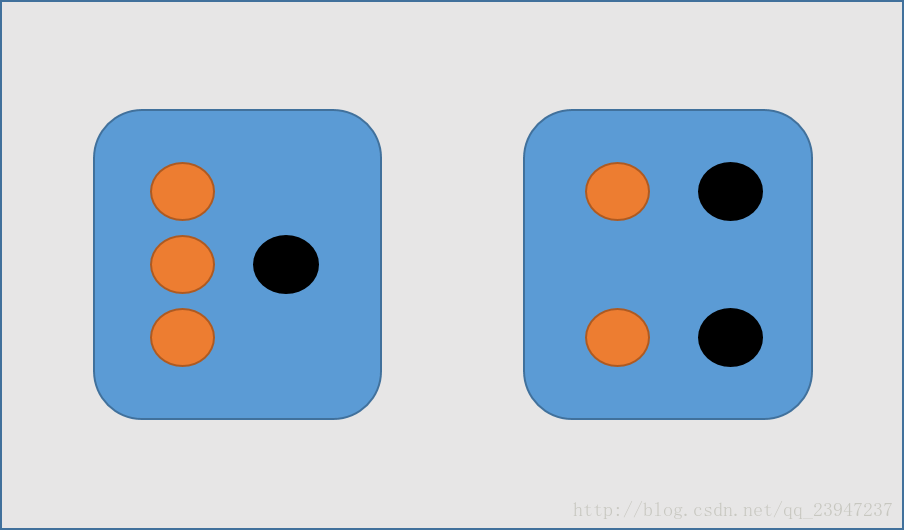
暂且不去算这道题,在这个看似无聊的事情中,从哪个箱子去抓是 因;抓到的糖是什么糖为 结果。再去回顾我们之前的贝叶斯公式:
P ( θ ∣ x ) = P ( x ∣ θ ) ∗ P ( θ ) P ( x ) P( \theta|x )=\frac{P(x|\theta) *P(\theta)}{P(x)} P(θ∣x)=P(x)P(x∣θ)∗P(θ)
[解释]:其中 x x x 是观测得到的结果数据。 P ( x ) P(x) P(x)是观测结果数据的概率分布。如下表:
| x x x | 水果糖 | 巧克力糖 |
|---|---|---|
| P ( x ) P(x) P(x) | 5/8 | 3/8 |
[解释]:其中 θ \theta θ 是决定观测结果数据分布的参数。 P ( θ ) P(\theta) P(θ) 是先验概率,没有观测数据的支持下 θ \theta θ 发生的概率。如下表:
| θ \theta θ | 一号箱 | 二号箱 |
|---|---|---|
| P ( θ ) P(\theta) P(θ) | 1/2 | 1/2 |
[解释]: P ( θ ∣ x ) P(\theta|x) P(θ∣x) 是后验概率,有观测数据的支持下 θ \theta θ 发生的概率。在上面的故事中第二问是小哥随机选择一个箱子,从中摸出一颗糖发现是水果糖。这颗水果糖来自一号箱子的概率就是后验概率:
P ( θ = 一 号 箱 ∣ x = 水 果 糖 ) P(\theta =一号箱 | x = 水果糖) P(θ=一号箱∣x=水果糖)
[解释]: P ( x ∣ θ ) P(x|\theta) P(x∣θ) 是似然函数,给定某参数 θ \theta θ 时结果数据的概率分布。
其中, P ( θ = 一 号 箱 ) P(\theta =一号箱) P(θ=一号箱) 就是先验概率,根据贝叶斯公式,需求证据 P ( x = 水 果 糖 ) P(x=水果糖) P(x=水果糖) 和似然函数 P ( x = 水 果 糖 ∣ θ = 一 号 箱 ) P( x = 水果糖 | \theta =一号箱) P(x=水果糖∣θ=一号箱) 。
P ( x = 水 果 糖 ) = ∑ i P ( x = 水 果 糖 ∣ θ = i 号 箱 ) P ( θ = i ) P(x=水果糖) = \sum_{i}P( x = 水果糖 | \theta =i 号箱)P(\theta = i) P(x=水果糖)=i∑P(x=水果糖∣θ=i号箱)P(θ=i)
我们再考虑上面的计算:
(1) 现在小哥将随机选择一个箱子,从中摸出一颗糖。请问小哥选择一号箱子的概率。根据明显的先验知识我们就可以知道
P ( θ = 一 号 箱 ) = 1 / 2 P(\theta =一号箱) =1/2 P(θ=一号箱)=1/2
(2) 现在小哥将随机选择一个箱子,从中摸出一颗糖发现是水果糖。请问这颗水果糖来自一号箱子的概率。后验概率为
P ( θ = 1 ∣ x = 水 果 ) = P ( x = 水 果 ∣ θ = 1 ) ∗ P ( θ = 1 ) P ( x = 水 果 ) P( \theta =1|x=水果 )=\frac{P(x=水果|\theta =1) *P(\theta =1)}{P(x=水果)} P(θ=1∣x=水果)=P(x=水果)P(x=水果∣θ=1)∗P(θ=1)
P ( θ = 1 ∣ x = 水 果 ) = P ( x = 水 果 ∣ θ = 1 ) ∗ P ( θ = 1 ) ∑ i P ( x = 水 果 糖 ∣ θ = i 号 箱 ) P ( θ = i ) P( \theta =1|x=水果 )=\frac{P(x=水果|\theta =1) *P(\theta =1)}{ \sum_{i}P( x = 水果糖 | \theta =i 号箱)P(\theta = i)} P(θ=1∣x=水果)=∑iP(x=水果糖∣θ=i号箱)P(θ=i)P(x=水果∣θ=1)∗P(θ=1)
P ( θ = 1 ∣ x = 水 果 ) = ( 3 / 4 ) ∗ ( 1 / 2 ) ( 3 / 4 ) ∗ ( 1 / 2 ) + ( 2 / 4 ) ∗ ( 1 / 2 ) P( \theta =1|x=水果 )=\frac{(3/4) *(1/2)}{ (3/4) *(1/2)+(2/4) *(1/2)} P(θ=1∣x=水果)=(3/4)∗(1/2)+(2/4)∗(1/2)(3/4)∗(1/2)
P ( θ = 1 ∣ x = 水 果 ) = 3 / 5 P( \theta =1|x=水果 )=3/5 P(θ=1∣x=水果)=3/5
我们为什么要在这里连续计算两道题呢,并不是为了单纯的计算,而是去比较计算结果得到贝叶斯推断的意义。
大家可以看到:没有做实验之前我们推断 P ( θ = 一 号 箱 ) = 1 / 2 P(\theta =一号箱) =1/2 P(θ=一号箱)=1/2 这个先验概率;而有了参考结果数据“从中摸出一颗糖发现是水果糖“,我们便可以得到 P ( θ = 一 号 箱 ∣ x = 水 果 糖 ) = 3 / 5 P( \theta =一号箱|x=水果糖 )=3/5 P(θ=一号箱∣x=水果糖)=3/5 这个后验概率。也就是说推断是一号箱的概率,在取出水果糖前和后,【 θ = 一 号 箱 \theta =一号箱 θ=一号箱 】事件的可能性得到了增强( 1 / 2 < 3 / 5 1/2 < 3/5 1/2<3/5)。
我们可以用小哥在公园的第二个奇遇来解释【贝叶斯估计】的意义:
小哥在公园里玩飞镖,附近有个陌生人说他是一个专业的飞镖玩家,假设你现在是小哥,你可能最开始会假设这家伙在开玩笑忽悠我吧。
首先你对这个人几乎什么都不了解,但遇到一个真正的专业飞镖玩家的概率是很小的。 因为澳大利亚的专业飞镖玩家也不过大约15个。
如果这个陌生人为了证明自己,开始扔飞镖并且第一次正中靶心,但这个数据可能还是不能令你非常信服,因为你觉得这可能只是运气。
但如果这个人连续十次都正中靶心,多个观测样本让你会倾向于接受他的专业说法。
在这件事当中,你对【陌生人是专业玩家】的先验置信度就被累积的实验数据所覆盖而增强变大,贝叶斯定理起作用了。
MAP/ML/贝叶斯估计
给定一些数据样本 x x x,假定我们知道样本是从某一种分布中随机取出的,但我们不知道这个分布具体的参数 θ \theta θ。
- 最大似然估计(ML,Maximum Likelihood)可以估计模型的参数。其目标是找出一组参数 θ \theta θ,使得模型产生出观测数据 x x x 的概率最大:
a r g m a x θ P ( x ∣ θ ) \underset{\theta}{argmax} P(x|\theta) θargmaxP(x∣θ)
- 假如这个参数有一个先验概率,那么参数该怎么估计呢?这就是MAP要考虑的问题。 最大后验估计(MAP-Maxaposterior)。MAP优化的是一个后验概率,即给定了观测值后使概率最大:
a r g m a x θ P ( θ ∣ x ) = a r g m a x θ P ( x ∣ θ ) ∗ P ( θ ) P ( x ) \underset{\theta}{argmax} P(\theta|x)=\underset{\theta}{argmax} \frac{P(x|\theta) *P(\theta)}{P(x)} θargmaxP(θ∣x)=θargmaxP(x)P(x∣θ)∗P(θ)
因为给定样本 x x x 后, p ( x ) p(x) p(x) 会在 θ \theta θ 空间上为一个定值,和 θ \theta θ的大小没有关系,所以可以省略分母 p ( x ) p(x) p(x)。
可化简为:
a r g m a x θ P ( θ ∣ x ) = a r g m a x θ P ( x ∣ θ ) ∗ P ( θ ) \underset{\theta}{argmax} P(\theta|x)=\underset{\theta}{argmax} P(x|\theta) *P(\theta) θargmaxP(θ∣x)=θargmaxP(x∣θ)∗P(θ)
即为:
P o s t e r i o r ∝ ( L i k e l i h o o d ∗ P r i o r ) Posterior∝(Likelihood∗Prior) Posterior∝(Likelihood∗Prior)
P ( x ) P(x) P(x) 相当于是一个归一化项,整个公式就表示为:后验概率 正比于 先验概率 ∗ * ∗ 似然函数。
- 前两种都是假设参数是个确定值,但贝叶斯估计假设参数是个随机数。
贝叶斯估计,假定把待估计的参数看成是符合某种先验概率分布的随机变量,而不是确定数值。在样本分布上,计算参数所有可能的情况,并通过计算参数的期望,得到后验概率密度。
学习和科研是一件枯燥乏闷的事情,也常会遇到令自己感到难受和不公的事情。在这里希望大家有一颗平常心,但行好事,莫问前程!
贝叶斯估计公式推导参考 这儿.
1. https://www.zhihu.com/question/24261751/answer/158547500
2. http://www.cnblogs.com/xueliangliu/archive/2012/08/02/2962161.html
这里是 脚注 的 内容. ↩︎

















 6058
6058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









